Camunda流程引擎常用API接口介绍
本文介绍Camunda7(Camunda7.19.0版本)流程引擎常用API接口,让大家了解Camunda常用的API接口有哪些(包括有:RepositoryService、RuntimeService 、TaskService 、HistoryService等),项目中如何调用Java API和REST API,尤其是查询API接口,Camunda提供了多种查询方式(包括有:Java Query API、REST Query API、Native Queries、Custom Queries、SQL Queries),用户可以根据实际业务需求选择合适的查询API。
1、Camunda Java API(Java接口)
Java API 是与引擎交互的最常见方式。中心起点是 ProcessEngine,它可以通过多种方式创建。从ProcessEngine 中,您可以获得包含工作流/BPM 方法的各种服务。ProcessEngine和服务对象是线程安全的。
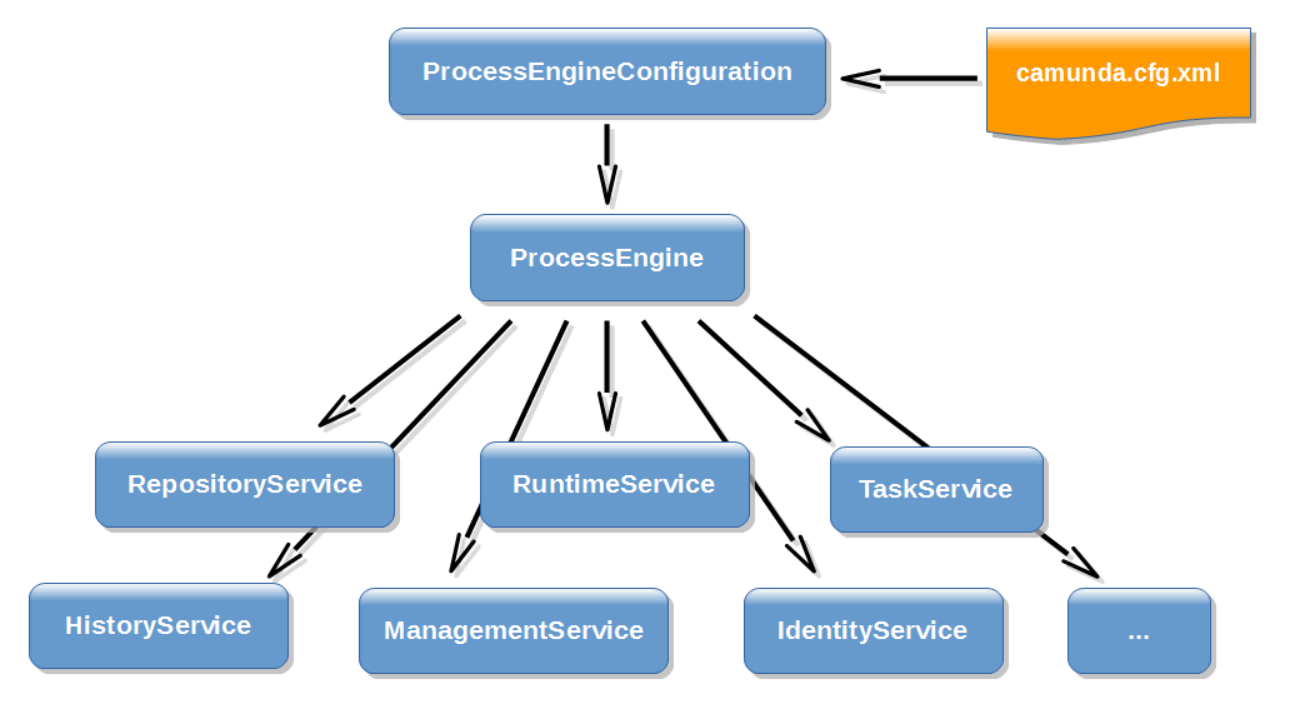
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();
RepositoryService repositoryService = processEngine.getRepositoryService();
RuntimeService runtimeService = processEngine.getRuntimeService();
TaskService taskService = processEngine.getTaskService();
IdentityService identityService = processEngine.getIdentityService();
FormService formService = processEngine.getFormService();
HistoryService historyService = processEngine.getHistoryService();
ManagementService managementService = processEngine.getManagementService();
FilterService filterService = processEngine.getFilterService();
ExternalTaskService externalTaskService = processEngine.getExternalTaskService();
CaseService caseService = processEngine.getCaseService();
DecisionService decisionService = processEngine.getDecisionService();
ProcessEngines.getDefaultProcessEngine()将在第一次调用进程引擎时初始化并构建该引擎,之后始终返回相同的进程引擎。所有流程引擎的正确创建和关闭都可以用ProcessEngines.init() 和ProcessEngines.destroy() 来完成。
ProcessEngines 类将扫描所有camunda.cfg.xml和activiti.cfg.xml文件。对于camunda.cfg.xml所有文件,流程引擎将以典型方式构建:
ProcessEngineConfiguration
.createProcessEngineConfigurationFromInputStream(inputStream)
.buildProcessEngine()
对于activiti.cfg.xml所有文件,流程引擎将以 Spring方式构建:首先创建 Spring应用程序上下文,然后从该应用程序上下文获取流程引擎。所有服务都是无状态的。这意味着您可以轻松地在集群中的多个节点上运行 Camunda Platform,每个节点都访问同一个数据库,而不必担心是哪台机器实际执行了以前的调用。对任何服务的任何调用都是幂等的,无论它在何处执行。
RepositoryService接口
RepositoryService 可能是使用 Camunda 引擎时需要的第一个服务。此服务提供用于管理和操作部署和流程定义的操作。这里不赘述,流程定义是 BPMN 2.0 流程的 Java 对应物。它是流程中每个步骤的结构和行为的表示形式。部署是引擎内的打包单元。一个部署可以包含多个 BPMN 2.0 XML 文件和任何其他资源。一个部署中包含的内容的选择由开发人员决定。它的范围可以从单个流程 BPMN 2.0 XML 文件到一整套流程和相关资源(例如,部署“hr-processes”可以包含与 hr 流程相关的所有内容)。RepositoryService 允许部署此类包。部署部署意味着将其上传到引擎,在将所有进程存储在数据库中之前,都会在引擎中进行检查和解析。
此外,RepositoryService 服务允许
- 查询引擎已知的部署和进程定义。
- 暂停和激活流程定义。挂起意味着不能对它们执行进一步的操作,而激活则相反。
- 检索各种资源,例如部署中包含的文件或引擎自动生成的流程图。
RuntimeService 接口
虽然 RepositoryService 是关于静态信息的(即不会改变,或者至少不会改变很多的数据),但 RuntimeService 恰恰相反。它处理启动流程定义的新流程实例。如上所述,流程定义定义了流程中不同步骤的结构和行为。流程实例是此类流程定义的一次执行。对于每个进程定义,通常有许多实例同时运行。RuntimeService 也是用于检索和存储进程变量的服务。这是特定于给定流程实例的数据,可以由流程中的各种构造使用(例如,独占网关通常使用流程变量来确定选择哪条路径来继续流程)。RuntimeService 还允许查询流程实例和执行。执行(Executions )是 BPMN 2.0 的“令牌token”概念的表示。基本上,执行是指向流程实例当前位置的指针。最后,每当流程实例正在等待外部触发器并且需要继续该流程时,都会使用 RuntimeService。流程实例可以具有各种等待状态,此服务包含各种操作,以向实例发出“信号”,表明已收到外部触发器,并且流程实例可以继续。
TaskService 接口
需要由系统的实际人类用户执行的任务是流程引擎的核心。任务周围的所有内容都分组在 TaskService 中,例如
- 查询分配给用户或组的任务。
- 创建新的独立任务。这些是与流程实例无关的任务。
- 操作将任务分配给哪个用户或哪些用户以某种方式参与该任务。
- 认领并完成任务。声明意味着某人决定成为任务的被分配者,这意味着该用户将完成任务。完成意味着“完成任务的工作”。通常,这里需要填写表单,结合表单设计器提前开发好表单。
IdentityService接口
IdentityService 非常简单。它允许管理(创建、更新、删除、查询等)组和用户。重要的是要了解,核心引擎实际上不会在运行时对用户进行任何检查。例如,可以将任务分配给任何用户,但引擎不会验证系统是否知道该用户。这是因为该引擎还可以与 LDAP、Active Directory 等服务结合使用。Camunda开源流程平台自带的组织用户管理和简单,很难满足国内组织/部门/岗位/用户/角色这种复杂的组织架构需求,而且还有多组织、跨组织、兼职部门、一人多岗的情况,这里需要项目上自行扩展开发。
FormService 接口
FormService 是一项可选服务。这意味着Camunda流程引擎可以在没有它的情况下完美使用,而不会牺牲任何功能。此服务引入了启动表单和任务表单的概念。启动表单是在启动流程实例之前向用户显示的表单,而任务表单是在用户想要完成任务时显示的表单。您可以在BPMN 2.0流程定义中定义这些表单。这是可选的,因为表单不需要嵌入到流程定义中。
HistoryService接口
HistoryService 负责查询引擎执行收集的所有历史数据。在执行流程时,引擎可以保留大量数据(这是可配置的),例如流程实例的启动时间、谁执行了哪些任务、完成任务需要多长时间、每个流程实例遵循的路径等。此服务主要用于访问此数据的查询功能。
ManagementService接口
对自定义应用程序进行编码时,通常不需要ManagementService。它允许检索有关数据库表和表元数据的信息。此外,它还公开了作业的查询功能和管理操作。作业在引擎中用于各种事情,如定时器、异步延续、延迟暂停/激活等。
FilterService 接口
FilterService 允许创建和管理筛选器。筛选器是存储的查询,如任务查询。例如,任务列表使用筛选器来筛选用户任务。
ExternalTaskService 接口
ExternalTaskService 提供对外部任务实例的访问。外部任务表示独立于流程引擎在外部处理的工作项。外部任务机制是Camunda流程引擎特有的能力,Activiti和Flowable开源流程引擎没有外部任务接口。
CaseService 接口
CaseService 类似于 RuntimeService,是案例实例CMMN的服务接口。它处理启动案例定义的新案例实例和管理案例执行的生命周期。该服务还用于检索和更新案例实例的流程变量。
DecisionService DMN规则引擎的服务接口。它是在独立于流程定义的业务规则任务中评估决策的替代方法。
Java API接口文档
有关Camunda流程平台服务操作和引擎 API 的更多详细信息,请参阅 https://docs.camunda.org/javadoc/camunda-bpm-platform/7.19/。
2、Camunda Query API(查询接口)
若要从引擎查询数据,有多种实现方式:
- Java 查询 API(Java Query API):用于查询引擎实体(如 ProcessInstances、Tasks 等)的 Fluent Java API。
- REST 查询 API(REST Query API):REST API 用于查询引擎实体(如 ProcessInstances、Tasks 等)。
- 本机查询(Native Queries):如果查询 API 缺乏您需要的可能性(例如,OR 条件),请提供自己的 SQL 查询来检索引擎实体(如 ProcessInstances、Tasks 等)。
- 自定义查询(Custom Queries):使用完全自定义的查询和自己的 MyBatis 映射来检索自己的值对象或将引擎与域数据连接起来。
- SQL 查询(SQL Queries):将数据库 SQL 查询用于报告等用例。
推荐的方法是使用Java Query API。
2.1、Java Query API(使用Java API查询)
Java 查询 API 允许使用fluent API 进行查询编程。您可以向查询添加各种条件(所有这些条件都作为逻辑 AND 一起应用),并且精确地添加一个排序。以下代码显示了一个示例:
List<Task> tasks = taskService.createTaskQuery()
.taskAssignee("kermit")
.processVariableValueEquals("orderId", "0815")
.orderByDueDate().asc()
.list();
查询最大结果数限制
在不限制最大结果数的情况下查询结果或查询大量结果可能会导致内存消耗过高,甚至导致内存溢出异常。借助查询最大结果限制,您可以限制最大结果数。
具体参考:https://docs.camunda.org/manual/7.19/reference/deployment-descriptors/tags/process-engine/#queryMaxResultsLimit
此限制仅在以下情况下强制执行:
- 经过身份验证的用户执行查询
- 查询 API 是直接调用的,例如通过 REST API(不通过Delegation Code在进程中强制执行,比如:Java Delegates、Delegate Variable Mapping、Execution Listeners、Task Listeners)
禁止的查询接口
允许的查询接口
- 使用该方法执行查询Query#unlimitedList
- 执行最大结果数小于或等于最大结果限制的分页查询
- 执行本机查询,因为它无法通过 REST API 或 Webapps 访问,因此不太可能被利用
查询接口局限性
- 通过 REST API 执行统计信息查询
- 通过 Webapps(私有 API)执行调用的实例查询
自定义身份服务查询
- 通过实现接口实现自定义身份提供程序实现ReadOnlyIdentityProviderWritableIdentityProvider
- 以及身份服务查询的专用实现(例如,GroupQuery, TenantQuery, UserQuery)
确保在调用Query#unlimitedList时不受任何限制地返回所有结果。检索无限列表的可能性对于确保 REST API 正常工作非常重要,因为一些终结点依赖于检索无限结果。
分页查询
分页允许配置查询检索到的最大结果以及第一个结果的位置(索引)。
请看以下示例:
List<Task> tasks = taskService.createTaskQuery()
.taskAssignee("kermit")
.processVariableValueEquals("orderId", "0815")
.orderByDueDate().asc()
.listPage(20, 50);
上面显示的查询检索 50 个结果,从索引为 20 的结果开始。
OR 查询
查询 API 的默认行为将筛选条件与 AND 表达式链接在一起。OR 查询支持生成查询,其中筛选条件与 OR 表达式链接在一起。
- 此功能仅适用于任务和流程实例查询(运行时和历史记录)。
- 以下方法不能应用于 OR 查询:orderBy...()、initializeFormKeys()、withCandidateGroups()、withoutCandidateGroups()、withCandidateUsers()、withoutCandidateUsers()。
调用or()后,可以遵循多个过滤条件的链。每个筛选条件都与一个 OR 表达式链接在一起。调用endOr()标志着 OR 查询的结束。调用这两种方法相当于将筛选条件放在括号中。
List<Task> tasks = taskService.createTaskQuery()
.taskAssignee("John Munda")
.or()
.taskName("Approve Invoice")
.taskPriority(5)
.endOr()
.list();
上面的查询检索分配给“John Munda”的所有任务,这些任务同时命名为“Approve Invoice”或被赋予priority=5(assignee=“John Mun达”and(name=“Approve Invoice”or priority=5))。在内部,查询将转换为以下 SQL 查询(略微简化):
SELECT DISTINCT *
FROM act_ru_task RES
WHERE RES.assignee_ = 'John Munda'
AND ( Upper(RES.name_) = Upper('Approve Invoice')
OR RES.priority_ = 5 );
可以一次使用任意数量的 OR 查询。当生成一个查询时,该查询不仅包含单个 OR 查询,还包含与 AND 表达式链接在一起的筛选条件,则 OR 查询通过前导 AND 表达式追加到条件链中。
与变量相关的筛选条件可以在同一 OR 查询中多次应用:
List<Task> tasks = taskService.createTaskQuery()
.or()
.processVariableValueEquals("orderId", "0815")
.processVariableValueEquals("orderId", "4711")
.processVariableValueEquals("orderId", "4712")
.endOr()
.list();
除了与变量相关的筛选条件外,此行为也有所不同。每当在查询中多次使用非变量筛选器条件时,仅使用最后应用的值:
List<Task> tasks = taskService.createTaskQuery()
.or()
.taskCandidateGroup("sales")
.taskCandidateGroup("controlling")
.endOr()
.list();
在上面显示的查询中,筛选条件taskCandidateGroup的值“sales”将替换为值“controlling”。为了避免这种行为,可以使用带有尾随…In的筛选条件,例如:可以使用:
taskCandidateGroupIn()、tenantIdIn()、processDefinitionKeyIn()。
2.2、REST Query API(使用REST服务查询)
Java 查询 API 作为 REST 服务公开,有关详细信息,请参阅 Camunda REST 文档:https://docs.camunda.org/manual/7.19/reference/rest/。
2.3、Native Queries(使用Navive查询)
有时您需要更强大的查询,例如,使用 OR 运算符的查询或无法使用 Query API 表达的限制。对于这些情况,我们引入了本机查询,它允许您编写自己的 SQL 查询。返回类型由您使用的 Query 对象定义,并将数据映射到正确的对象中,例如 Task、ProcessInstance、Execution 等。由于查询将在数据库上触发,因此必须使用数据库架构中定义的表名和列名。这需要对内部数据结构有一定的了解,建议谨慎使用本机查询。可以通过 API 检索表名,以使依赖项尽可能小。
List<Task> tasks = taskService.createNativeTaskQuery()
.sql("SELECT * FROM " + managementService.getTableName(Task.class) + " T WHERE T.NAME_ = #{taskName}")
.parameter("taskName", "aOpenTask")
.list();
long count = taskService.createNativeTaskQuery()
.sql("SELECT count(*) FROM " + managementService.getTableName(Task.class) + " T1, "
+ managementService.getTableName(VariableInstanceEntity.class) + " V1 WHERE V1.TASK_ID_ = T1.ID_")
.count();
2.4、Custom Queries(使用自定义查询)
出于性能原因,有时可能不希望查询引擎对象,而是查询一些自己的值或 DTO 对象,从不同的表中收集数据,也可能包括您自己的业务表。
2.5、SQL Queries(使用QL查询)
如果你对Camunda数据库表结构很了解,可以直接使用SQL直接查询数据库表。Camunda数据库表结构详细说明见文档:https://blog.csdn.net/wxz258/article/details/109048818。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号