
由快速排序引申而来--如何学习算法
大部分人都知道,其实我们一般都不需要去学什么算法。除非是,要么是学生(立志参加ACM),或者做纯粹算法研究的专业人员,再者要么是为了进一些大公司而准备面试,要么是纯兴趣使然。真正因为参加工作要用很多算法的人实在是少之又少。当然,或许做图像处理或者数据处理,数据挖掘,再或者,有关搜索引擎等等之类的东西(恕我才识浅陋,从这篇文章看各自相关算法的应用领域:当今世界最为经典的十大算法--投票进行时,亦可窥知一二)。我甚至认为,绝大部分的人是肯定掌握了一些跟数据结构有关的基本算法的,所以,总而言之,我始终相信,一个人,尤其是学生,实在是没有必要花太多精力在算法相关上的。
但有两个朋友关于快速排序的理解,让我对此前的观点--认为不需要多学算法,稍稍产生了怀疑。
- 在7月初找工作的时候,一位朋友(以前做过面试官)跟我聊天时谈到,刚毕业的学生当中,十个人有九个人不能把快速排序写出来。我当时就震惊了。因为,我不信。我无法理解一个如此基础而重要的简单的快速排序竟有那么多的人写不出来。总共才二十多来行代码阿。于是,我想试试自己的临场发挥能力。便当即把快速排序写了出来(不过,到底还是有一些细节性的错误,后来又修改了一次)。这是其一。
- 昨晚认识了两个在广东的朋友,他们于第二天将到我现在这家公司实习。其中一位朋友谈到他在公司面试的时候,面试官问他快速排序的时间复杂度和空间复杂度时,他说他完全懵了,此前根本就没有这个意识,不知道。我当即告诉他,说快速排序的时间复杂度平均为O(N*logN),最坏为O(N^2),空间复杂度由于是由数组存储,所以,当然是O(N)。我对他说,你拿一张纸和一支笔,在五分钟之内,我能当场把快速排序准确无误的写出来。朋友连称厉害。我当时明白了两点:1、的确有人对快速排序不够理解,写不出快速排序,甚至连最基本的了解都没有;2、很多人称我厉害,原来我只是知道一些他们不知道的但同时又够简单的基础算法。
自从我开始写经典算法研究系列之后,便有很多很多的朋友叫我写一篇如何学习算法的文章,或者谈谈算法学习方面的心得与体会。本来之前是因为一来算法这个东西在实际工作中应用不多(就像上面提到的快速排序算法,标准库里一个sort直接搞定,根本不再需要你去写十几行的代码,既如此,又何必重复造轮子)。二来是我个人觉得,学习这种事情你学就对了,只要你有兴趣,便什么问题都能解决。应该不用像一些“大家”,“专家”那样扯起长篇大论。但现在,情况已经不同了(我特别讨厌那些在我面前装的人。说什么自己算法很牛逼,或者自以为是,或说一个搞算法研究的人可以去做图书编辑,搞笑)。
关于如何学习算法,下面,个人简略谈三点(学算法= 兴趣 + 态度 + 编码 + 关注实践应用):
- 兴趣。学好任何一个东西,首先便必须得具备兴趣。算法也不例外。如果你对算法实在没有兴趣,也大可不必担忧。毕竟,各有所爱。
- 态度,重试程度。如果你觉得因为算法在实际工作中应用不多,或者标准库里都封装了一切。或者认为,最基本的快速排序都不必去了解,那么此文可以一扫而过了。
- 实践。看书,如数据结构方面的教材,一定要把各种最基本的数据结构,如数组,字符串,栈,堆,队列,树,图弄得通通透透(其实,看我之前整理的微软面试100题,也有很大帮助,因为那些面试题大多都跟数据结构和算法相关的,而我也是这么做过来的),其次便是如朋友天时通所说的,基本的迭代法,穷举搜索法,递推法,递归法,贪婪法,分治法,动态规划法,回溯法等等都要弄懂弄透。然后可以读编程珠玑,算法导论(很多人都说算法导论看不懂,实则是其上面的很多数学证明,我也不是很懂。具体可多在纸上画画,如红黑树的相关操作及代码),再加上推敲--反复思考,反复研究,最后编码--关注和结合实际应用,编码实现(写代码实现一个算法比研透一个算法更有用)。仅以上,无它也。
很多朋友还问到,我是怎么学习算法,或者说学习过程是怎样的,我是这样子学的:从去年12月开始接触算法起(写第一篇算法文章,A*搜寻算法),我先是因为要写有关算法的文章,所以很多的时候都要去参考资料,包括书籍和网上的,特别注重把一个算法真正阐述清楚,而要阐述清楚的话,那么我自己本身就得先把那个算法真正弄懂弄透,即只有自己懂了,我才可以讲明白。然后是我一直在做那有关微软等公司的面试题(大部都涉及到数据结构和算法),然后,再与他人多多交流,最后,在反复推敲和思考某一个算法之后,我便开始编写代码实现某个算法了。这就是我学算法的学习过程。
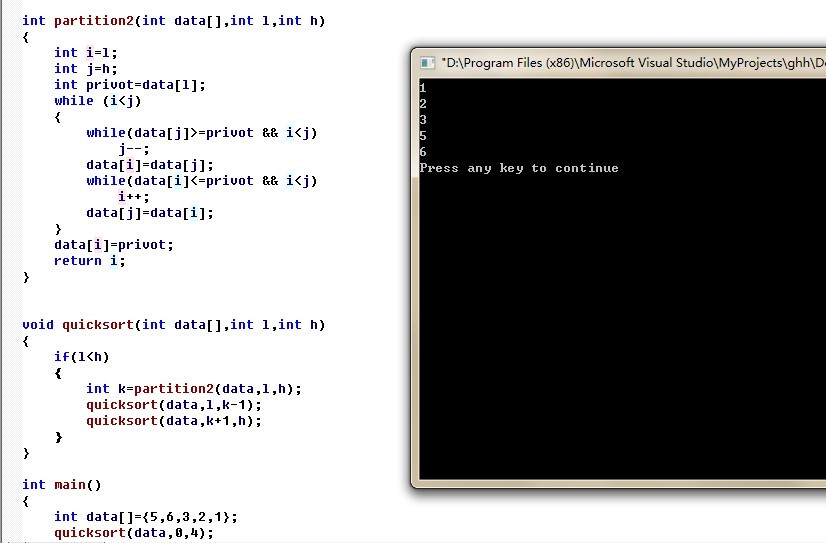
ok,闲不多扯,接下来,咱们来具体看看快速排序算法的实现。如下图所示,是前两天在公司练习的快速排序,诸位可以参考下:

个人认为,完整写出这个快速排序还是不难的,不过要注意很多细节问题,如:
- 我们知道,快速排序的分治partition过程有两种方法,一种是上面所述的两个指针索引一前一后逐步向后扫描的方法(算法导论上采用的是这种方法),还有一种方法是两个指针从首位向中间扫描的方法(大多数的人和一般的教材采用的是这第二种首尾向中间扫描法)。
- partition过程中,要注意一些边界值问题。如i、j索引的初始化,for循环中,j从数组中第一个位置l 到倒数第二个位置h-1处,且是当data[j]<=privot(是小于等于,非小于),然后找到了之后,i++,再交换。最后还有一次data[i+1]与data[h]的交换。最后,便是返回值的问题,返回i+1。
- 第三个要注意的方面是递归处。if(l<h),才进入递归。
主要要注意的问题就是上述三个方面。只要把握好细节,那么快速排序算法,二十几行自能搞定。下图是快速排序算法的第二种实现(就是上面所提到的首尾向中间扫描法):
这里,也要注意一个小问题,就是上述partition过程中,while循环内,下述A,B两个过程的顺序不能搞错。因为如果把A,B两个过程调换过来的话,即相当于把data[l]先赋给了privot,所以那样先从低处扫描的话,那么data[i],即privot覆盖了高处data[j] 的值。像原来的正常顺序,为什么又可以了列?因为data[l]已经保存在privot里面,所以 ,才不怕privot 覆盖了低处的值。
while(data[j]>=privot && i<j)
j--;
data[i]=data[j]; //以上三行为A过程
while(data[i]<=privot && i<j)
i++;
data[j]=data[i]; //以上三行为B过程
你如果还不理解的话,看下如下的示例过程就知道了。首先,我们以正常的过程来进行第一趟排序:
a:3 8 7 1 2 5 6 4 //以第一个元素为主元
2 8 7 1 5 6 4
b:2 7 1 8 5 6 4
c:2 1 7 8 5 6 4
d:2 1 7 8 5 6 4
e:2 1 3 7 8 5 6 4 //最后补上,关键字3
那如果上面的代码A,B过程的顺序被调换,也就是被弄错了列?如下:
while(data[i]<=privot && i<j)
i++;
data[j]=data[i]; //以上三行为B过程while(data[j]>=privot && i<j)
j--;
data[i]=data[j]; //以上三行为A过程
排序的过程将如下所述,低处的元素8将覆盖高处的元素4,元素4不像上面的元素3被事先保存在privot里,所以,元素4就丢了:
a:3 8 7 1 2 5 6 4 //以第一个元素为主元
3 7 1 2 5 6 8
b:.....
OK,有关快速排序算法实现的更多版本,请参考此篇文章:十二、快速排序算法之所有版本的c/c++实现。
结语(下述第2点所示的图片语录来自一匿名网友,不过,他表达了我想说的意思):
- 虽然实际项目中80%不需要自己构造算法,但对足够基础的算法有所了解是理所必然的。快速排序(仅指学生)写不出来的确没什么,但与此同时,表露了一个不重视基础算法的态度问题。

今天,我明白了一点,找工作一定要找与自己兴趣相关的工作。否则,一切,无从谈起。以上任何言论,均代表本人观点。
谢谢浏览,希望闲话之外,对你有所帮助。完。
原创文章,作者本人享有版权及著作权。转载,请注明出处及作者本人,否则,追究法律责任。
posted on 2011-07-25 11:17 Hibernate4 阅读(216) 评论(0) 编辑 收藏 举报


