分布式锁
分布式介绍
分布式锁背景
分布式锁应该具备哪些条件
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行
- 高可用的获取锁与释放锁
- 高性能的获取锁与释放锁
- 具备可重入特性(可理解为重新进入,由多于一个任务并发使用,而不必担心数据错误)
- 具备锁失效机制,防止死锁
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁的实现有哪些
- Memcached(数据库):利用 Memcached 的
add命令。此命令是原子性操作,只有在key不存在的情况下,才能add成功,也就意味着线程得到了锁。 - Redis:和 Memcached 的方式类似,利用 Redis 的
setnx命令。此命令同样是原子性操作,只有在key不存在的情况下,才能set成功。 - Zookeeper:利用 Zookeeper 的顺序临时节点,来实现分布式锁和等待队列。Zookeeper 设计的初衷,就是为了实现分布式锁服务的。
基于数据库
加锁
insert into distributed_lock(unique_mutex, holder_id) values ('unique_mutex', 'holder_id');
如果当前sql执行成功代表加锁成功,如果抛出唯一索引异常(DuplicatedKeyException)则代表加锁失败,当前锁已经被其他竞争者获取。
解锁
delete from methodLock where unique_mutex='unique_mutex' and holder_id='holder_id';
进阶:
锁释放时机:如果一个竞争者获取锁时候,进程挂了,此时distributed_lock表中的这条记录就会一直存在,其他竞争者无法加锁。为了解决这个问题,每次加锁之前我们先判断已经存在的记录的创建时间和当前系统时间之间的差是否已经超过超时时间,如果已经超过则先删除这条记录,再插入新的记录。另外在解锁时,必须是锁的持有者来解锁,其他竞争者无法解锁。这点可以通过holder_id字段来判定。
缺点:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
解决方案:
1、数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
2、没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
3、非阻塞的?搞一个while循环,直到insert成功再返回成功。
4、非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
基于Redis
问题和解决方案
redis内存模型
抛出异常,导致锁未被释放
服务器宕机,导致锁未释放
超时时间设置不合适,太长太短都有问题
当前线程释放其他线程加的锁
其他线程获取锁的方式是
redis主从切换锁失效的问题
redis和高并发
基于zk
zk实现方式是利用它节点的唯一性和有序性:
假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;zk提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zk在生成子节点时会根据当前的子节点数量自动添加整数序号,也就是说如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
具体步骤:
1、客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推。
2、客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听自己前一位子节点的变更消息,获得子节点变更通知后重复此步骤直至获得锁;
3、执行业务代码;
4、完成业务流程后,删除对应的子节点释放锁。监听此节点的客户端获得锁
缺点:
性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同步到所有的Follower机器上。
实现方式比较
从性能角度(从高到低)
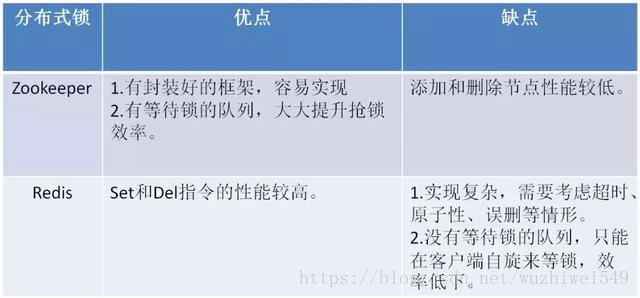
缓存 > Zookeeper >= 数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号