AI系统论文:Janus(MoE)(continuing)

abstruct
all-to-all communication: (expert-centric) 让专家位于原地,数据在专家之间进行交换。
作者提出了一种”data-centric“的范式:让数据位于原地,在GPU之间移动专家。(因为专家的规模小于数据)。——Janus
主要适用于
the size of expert is small while the amout of input data is large(e.g., large batch size)
特点
- 支持“fine-grained”(细粒度的)异步通信。——使得计算和通信重叠
同时,实现了分层通信,通过在同一台机器上共享获取的专家来进一步减少交叉节点流量。
细粒度的(fine-grained) 指的是:将时间或者资源划分的非常细,来更好地进行调控
- 其次,在调度“抓取专家”请求时,Janus实现了拓扑感知的优先级策略,以有效地利用节点内和节点间的链路
- 最后,Janus允许预取专家,这允许下游计算在前一步完成后立即开始。
- 是“data-centric”的
introduction
MoE示意图
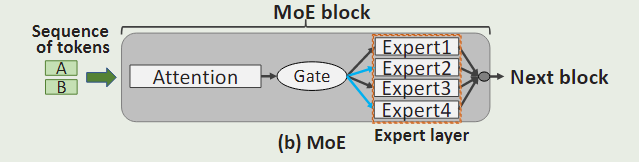
expert parallelism示意图
是为了解决MoE模型超过了单个GPU的内存限制而提出的。示例如下:
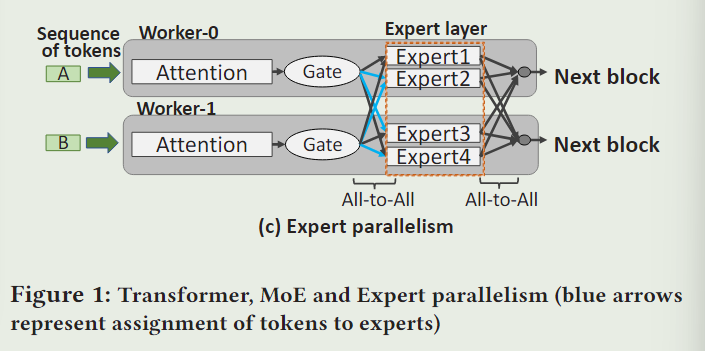
Expert被放在了不同的GPU(worker)上,因此,在模型计算过程中,必须在专家层前后添加all -to- all通信,以便在各gpu之间交换中间结果。
在NLP中,中间数据也叫作 token
data-centric的优点:
- 实现expert之间的异步通信,而不像expert-centric一样,必须等每轮迭代中GPU全部完成后,再进行通信(同步)。同时,同一个机器上的expert可以被该机器上不同的GPU重用。
- 由于专家权重(expert weights)在单次迭代中是确定的。因此预取专家是可能的,并且它允许我们进一步改善计算和通信之间的重叠
"expert weights" 指的是模型中的参数,具体来说是用来调整模型中不同专家(或子模型)的重要性或贡献程度的权重参数。
这里的权重不是用来决定数据分配给哪个专家的权重,而是用来决定每个专家模型对最终预测结果的贡献有多大的权重
因此,其在一次迭代过程中是确定的。
Janus提升模型性能的三个视角
- Janus将获取每个专家的请求作为单独的任务。
好处:一个worker可以在接受另一个专家的同时(communication),执行一个expert的计算任务(computation)。同时,也使得Janus能够将同一个机器上的不同worker对同一个expert的请求合并。
-
topology-aware priority 策略来仔细安排专家请求的优先级
-
Janus利用空闲时隙中的带宽来预取专家,这使得专家层的计算可以在
一层的计算完成后立即开始。
2 Background
2.1 Transformer and MoE Model
Transformer
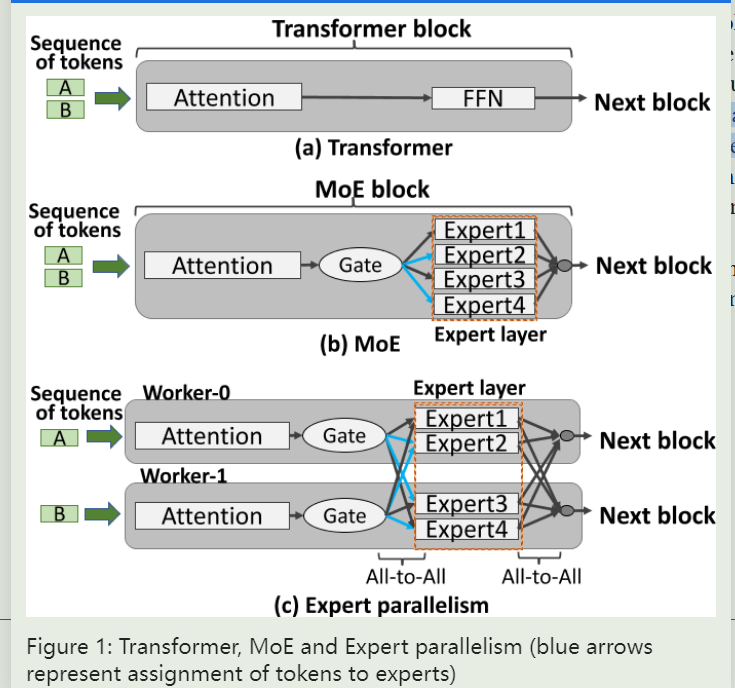
Transformer块(figure1(a))通常由两部分组成:注意力层和前馈网络层(FFN)。一般,MoE块可以从Transformer块派生。
2.2 Expert Parallelism
有些MoE模型,每个GPU上的experts是不一样的。有些则是independent copy。
3 Observation and Motivation
3.1 observation on expert-centric paradigm
3.1.1 The communication workload is heavy and imbalanced.
- all-to-all 通信开销在MoE模型中每轮迭代的占比很大(有时多达一半)。
- All to All原语是一种同步集体通信,这意味着延迟由需要发送和接收最大数量tokens的最繁忙的worker决定。因此,不平衡的工作量对训练时间有负面影响
3.1.2 The links between GPUs are heterogeneous
同一台机器中的GPU通过NVlink连接,不同机器中的GPU通过RDMA网络连接。机器内All-to-All goodput 比机器间 All-to-All goodput 大 18 倍,这表明机器内链路的带宽在机器间All-to-All 通信中没有得到充分利用,系统性能受限于机器间链路的带宽。
3.1.3 Cross-GPU links can be underutilized or idle in some time slots
3.2 Data-centric Paradigm
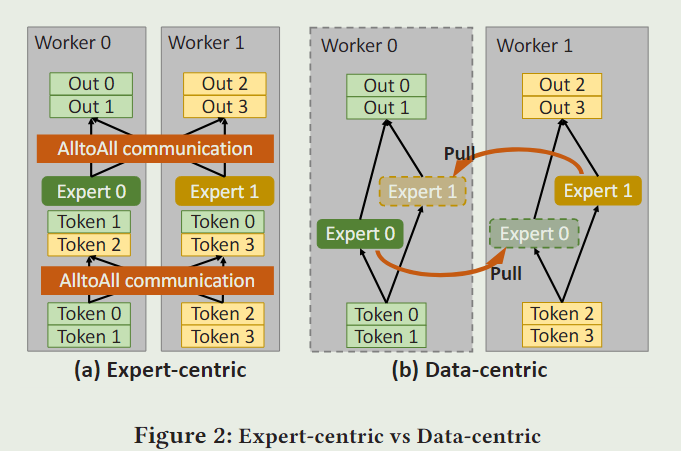
先不看了,这段其实没啥太大用处
他与SmartMoE的异同:
同:
- 两者均是在worker/device之间移动expert。
异:
SmartMoE专注于平衡不同device之间的负载,通过训练一定轮数后,依据历史训练信息——不同expert的负载,来将他们分配给不同的device(每个worker有多个expert)
Janus则专注于在一个训练迭代过程进行expert的拉取,调整expert是为了在需要的设备上训练训练对应的输入(每个worker只有一个expert),并不是为了平衡device的负载差异。
4 overview of janus
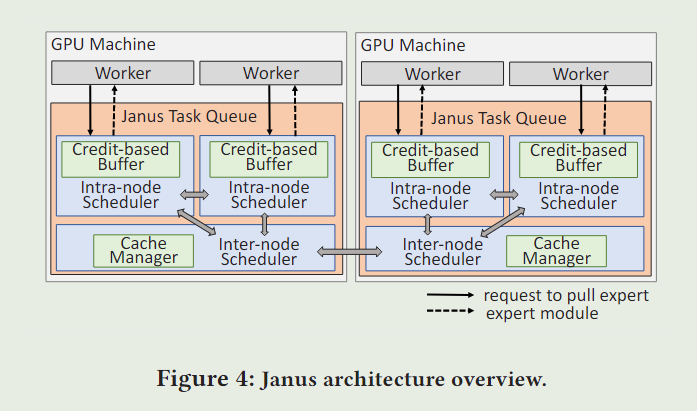
每个worker存储其上的Experts的权重,并且每轮迭代后在worker上更新参数。
训练流程:
- 传输专家的通信大小大于传输数据,则传输数据,改为expert-centric
- 否则,用data-centric,传输expert
worker获取完专家后,在自己上计算完成后。等一轮迭代结束后,计算梯度,然后发送回原本的worker上进行更新。
每个GPU上有一个Janus Task Queue,其中含有:一个Inter-node Scheduler 和多个Intra-node Schedulers(有几个worker就有几个intra-node schedulers)。
具体地:intra-node scheduler位于GPU的显存中,负责从其对应的worker上接受请求并且为这个worker获取expert。并有一个名为Credit-based buffer的部件,来为拉取过来的experts安排显存。
inter-node scheduler:每个机器有一个inter-node scheduler,负责响应intra-node scheduler的worker拉取请求,来从其他机器上fetching expert,它里面有Cache manager来负责为fetching 来的expert分配GPU内存。
如果worker请求的expert已经被pre拉取到本地GPU了,那intra-node scheduler直接从另一个worker中拿过来,如果没有被pre过来,那intra将请求发给inter-node scheduler。
Janus Task Queue的调度策略:
首先,在收到来自工人的请求后,队列以细粒度的方式逐个拉专家,而不是同时拉所有专家(5.1)。?
其次,队列根据工作者的拓扑结构安排请求的顺序,以缓解瓶颈带宽争用。
第三,队列尝试在可能的情况下预取专家,这使得一旦前一层的计算完成(5.3),专家层的计算就可以立即开始。
5 System design
5.1 Fine-grained task scheduling
Janus将工作人员的所有非本地专家的请求分成一组小任务,每个小任务中只需要提取单个专家,因此Janus以细粒度的方式调度这些小任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号