“动手学深度学习Pytorch版”笔记
一: 2.3.3 梯度:
梯度就是对张量中的每个变量都求偏导,求出某点的值,然后将他们按照原先张量的对应顺序写成一个新张量,这个新张量就是原先张量在某点的梯度
如:
import torch
x = torch.ones(2,2,requires_grad=True)
print(x)
y = x + 2
print(y)
z = y * y * 3
print(z)
out = z.mean() # 求所有数的均值
print(out)
out.backward()
print(x.grad)
结果:
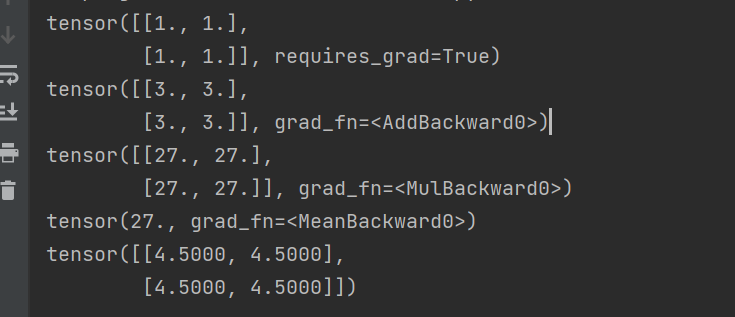
解释:

二:torch使用方法
torch.normal
X = torch.normal(0,1,(1000,2))
此处返回一个1000行2列的tensor,里面每个元素都是从均值为0,标准差为1的正态分布中随机抽取的。
normal(tensor mean, tensor std, tensor out) # 分别表示均值,标准差,输出张量的格式(几行几列)
torch.matmul
参考
orch.matmul是tensor的乘法,输入可以是高维的。
当输入都是二维时,就是普通的矩阵乘法,和tensor.mm函数用法相同。
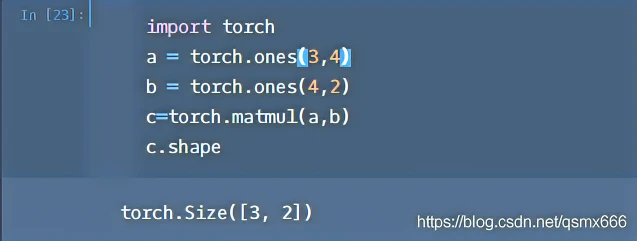
当输入有多维时,把多出的一维作为batch提出来,其他部分做矩阵乘法。
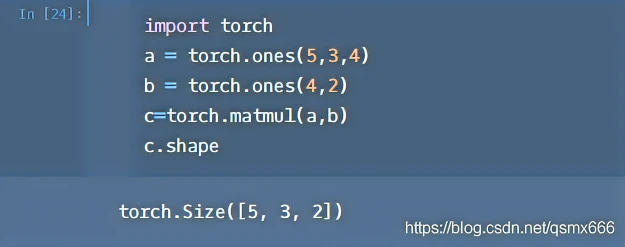
下面看一个两个都是3维的例子。
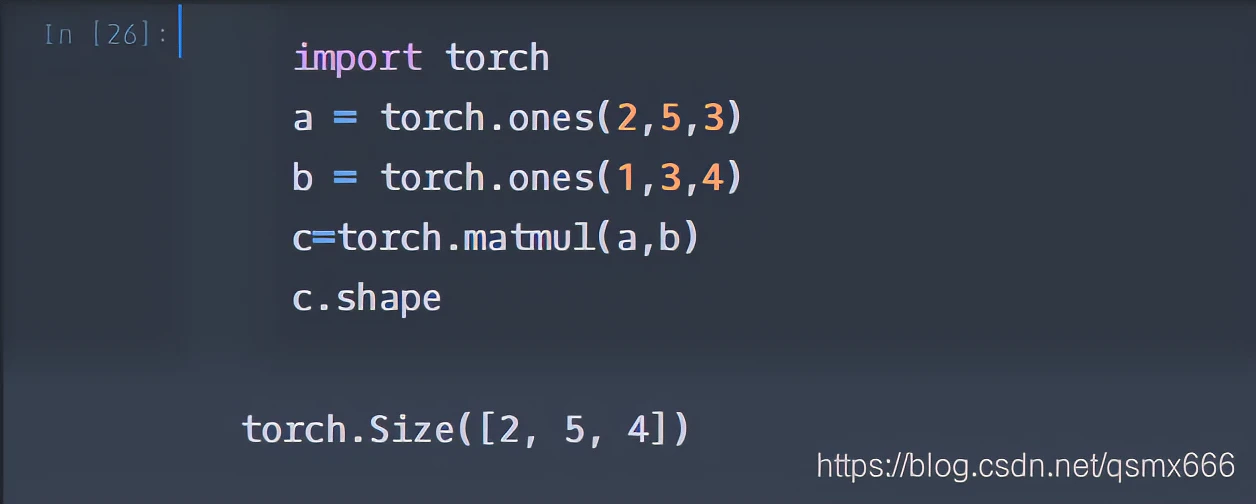
将b的第0维1broadcast成2提出来,后两维做矩阵乘法即可。
再看一个复杂一点的,是官网的例子。
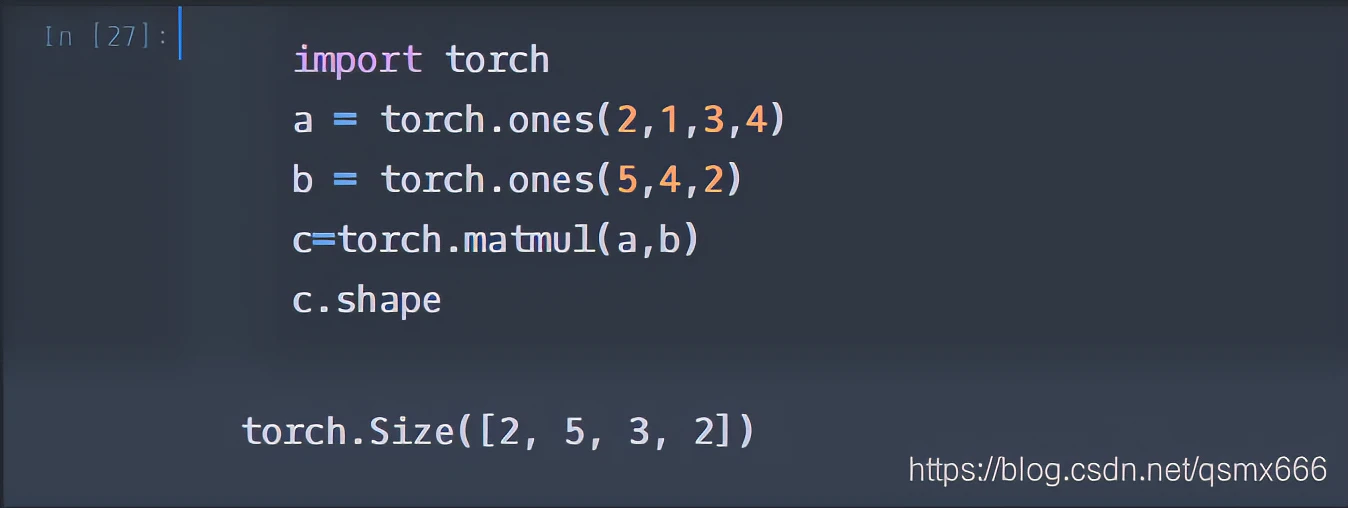
首先把a的第0维2作为batch提出来,则a和b都可看作三维。再把a的1broadcat成5,提取公因式5。(这样说虽然不严谨,但是便于理解。)然后a剩下(3,4),b剩下(4,2),做矩阵乘法得到(3,2)。
————————————————
版权声明:本文为CSDN博主「明日何其多_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qsmx666/article/details/105783610
random.shuffle()
引入库:random
import random
作用:random.shuffle()用于将一个列表中的元素打乱顺序,值得注意的是使用这个方法不会生成新的列表,只是将原列表的次序打乱。
yield 用法
with torch.no_grad():
参考
一句话:被with torch.no_grad()包住的代码,不用跟踪反向梯度计算
data.TensorDataset(Tensor x,Tensor y)
作用:对数据x,y按照第一维度进行打包,因此x,y的第一维度必须同维度
from torch.utils import data
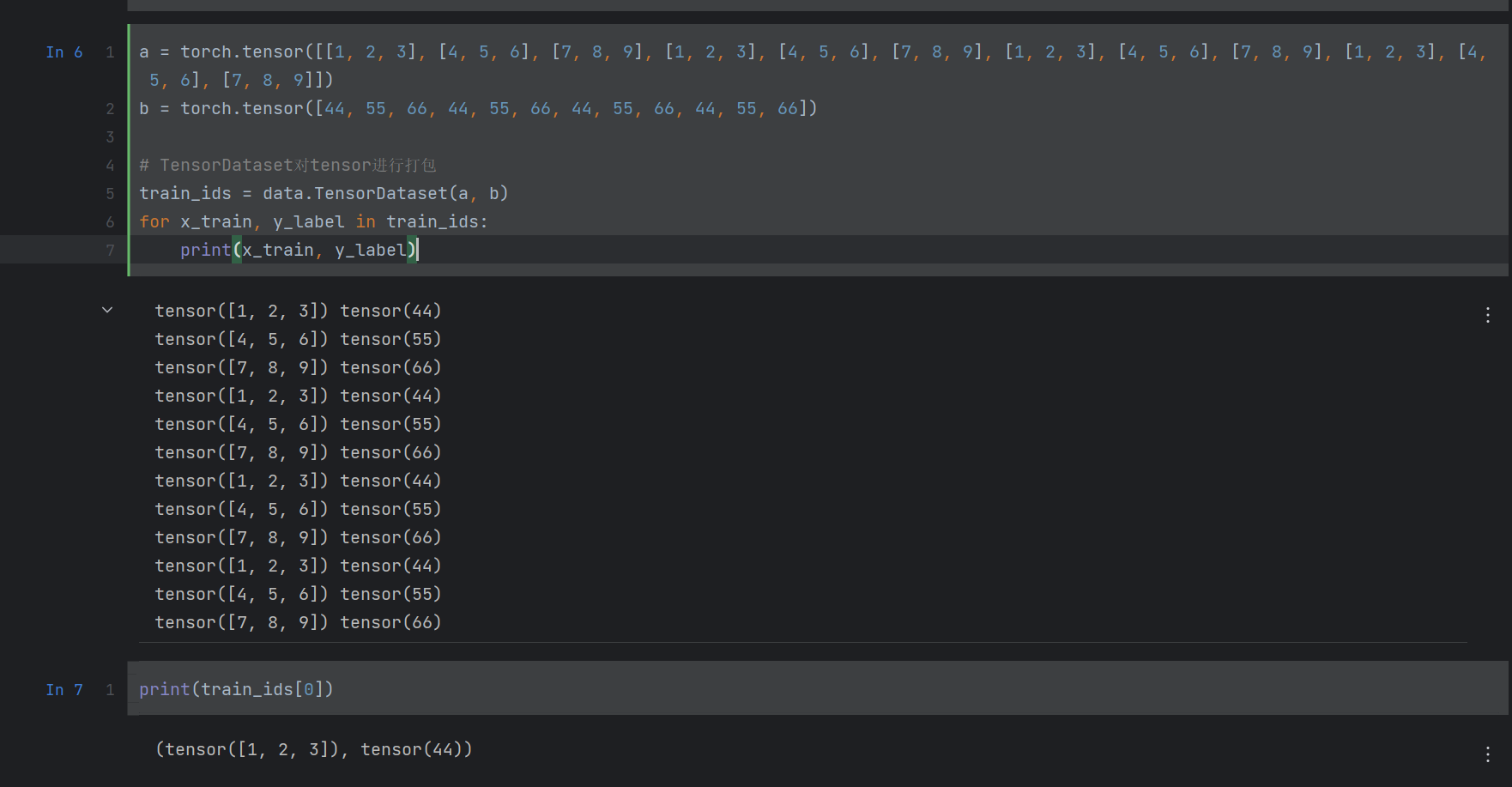
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = torch.tensor([44, 55, 66, 44, 55, 66, 44, 55, 66, 44, 55, 66])
# TensorDataset对tensor进行打包
train_ids = data.TensorDataset(a, b)
for x_train, y_label in train_ids:
print(x_train, y_label)
结果:
data.DataLoader(Tensor dataset, batch_size, shuffle)
参考
作用:对dataset的数据按照长度为batch_size进行打包,shuffler如果为True:打乱顺序,否则不打乱
一般与data.TensorDateset(x, y)一起用
DataLoader返回的是一个可迭代对象,可以通过next(iter())来逐步迭代访问,但不可通过下标来访问
-
dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
-
使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
-
也可以使用
for inputs, labels in dataloaders进行可迭代对象的访问; -
一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据;
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = torch.tensor([44, 55, 66, 44, 55, 66, 44, 55, 66, 44, 55, 66])
# TensorDataset对tensor进行打包
train_ids = data.TensorDataset(a, b)
for x_train, y_label in train_ids:
print(x_train, y_label)
print('=' * 80)
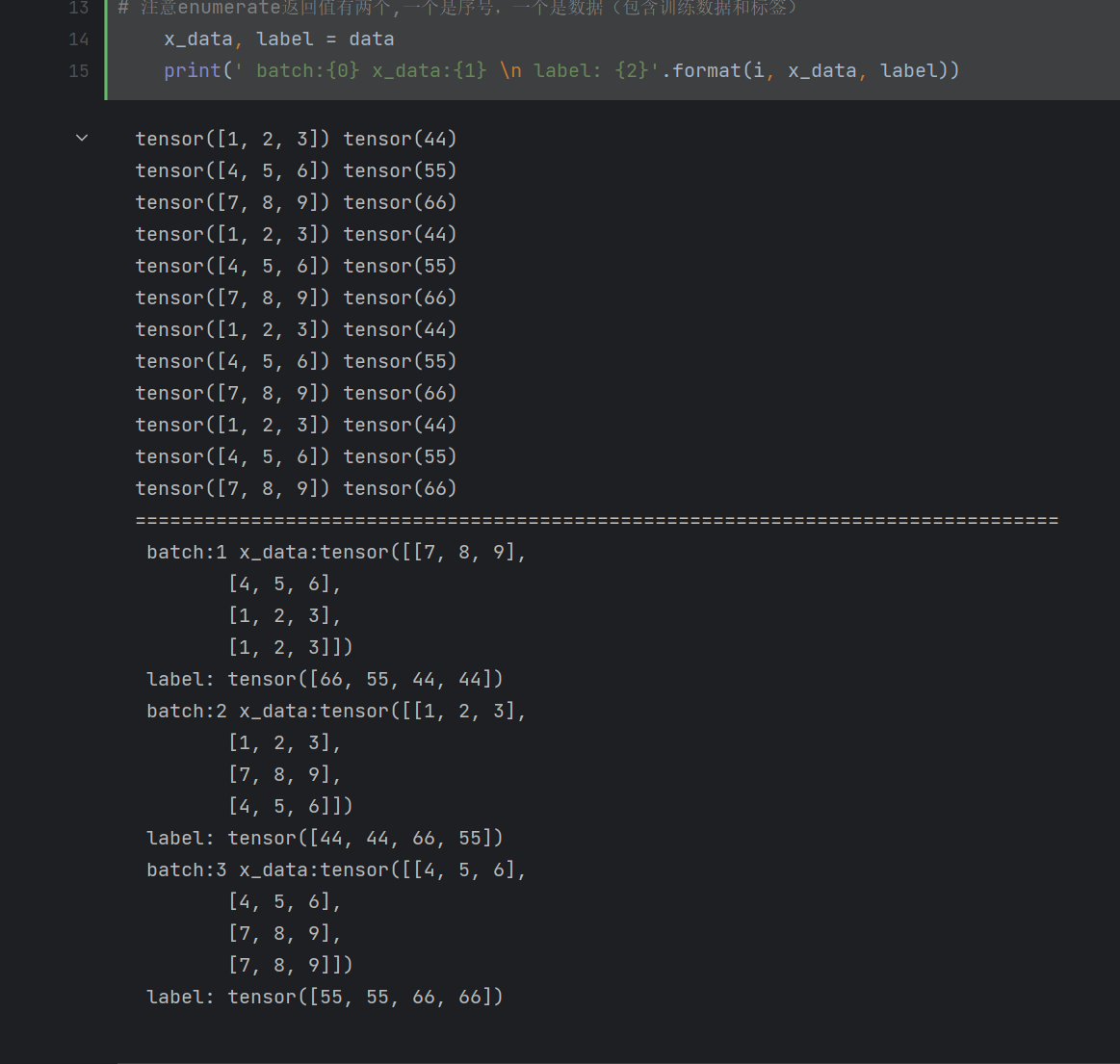
train_loader = data.DataLoader(dataset=train_ids, batch_size=4, shuffle=True) # 在dataset中,每batch_size封装为1组,同时由于shuffle=True故打乱顺序
for i, data in enumerate(train_loader, 1):
# 注意enumerate返回值有两个,一个是序号,一个是数据(包含训练数据和标签)
x_data, label = data
print(' batch:{0} x_data:{1} \n label: {2}'.format(i, x_data, label))
结果:
把一个tensor作为另一个tensor的索引
参考
动图参考:
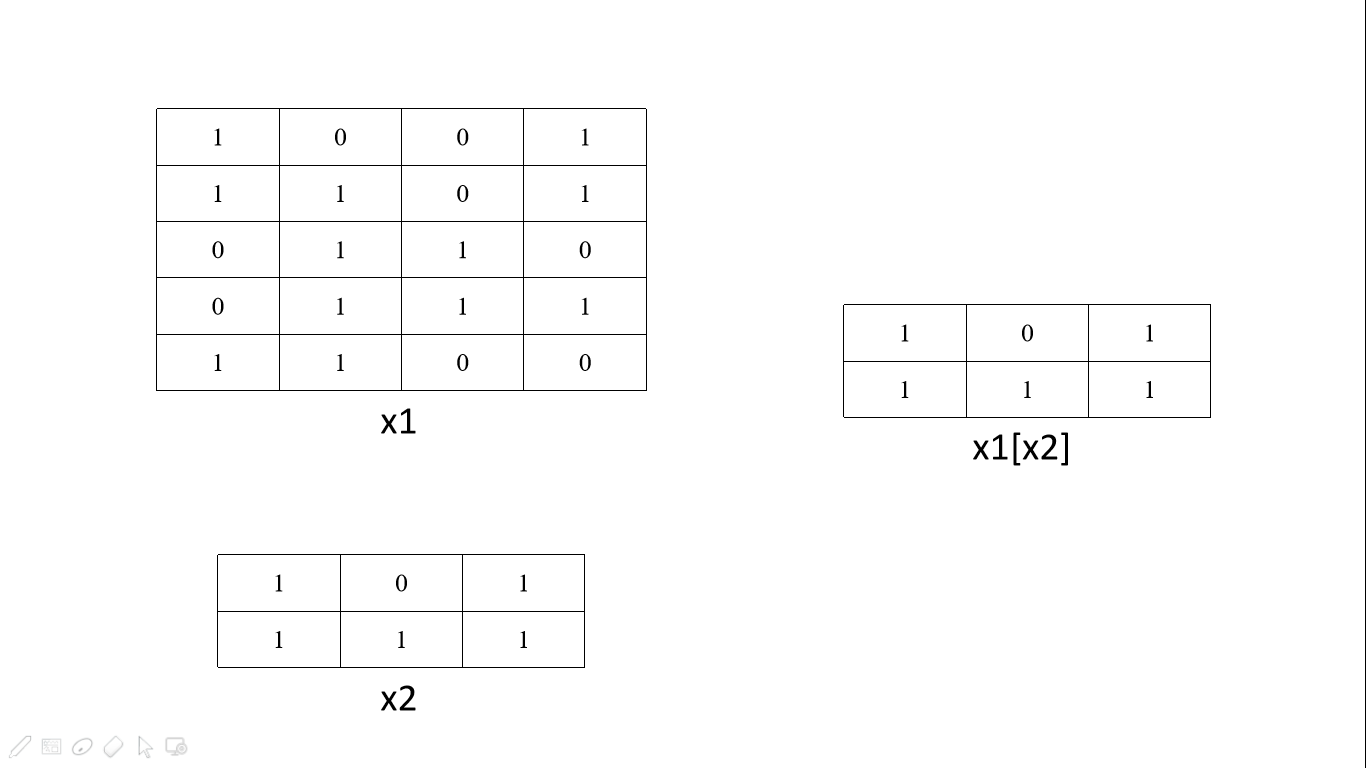
例子解析:
x = torch.tensor([[1, 2, 3, 4],
[2, 3, 4, 5],
[3, 4, 5, 6]])
y = torch.tensor([[1, 0, 1],
[0, 2, 1]])
x[y]
x 是一个 \(3\times 4\) 的tensor, y 是一个 \(2 \times 3\) 的tensor
将 y 作为 x 的索引后,会形成一个 \(2 \times 3 \times 4\) 的tensor
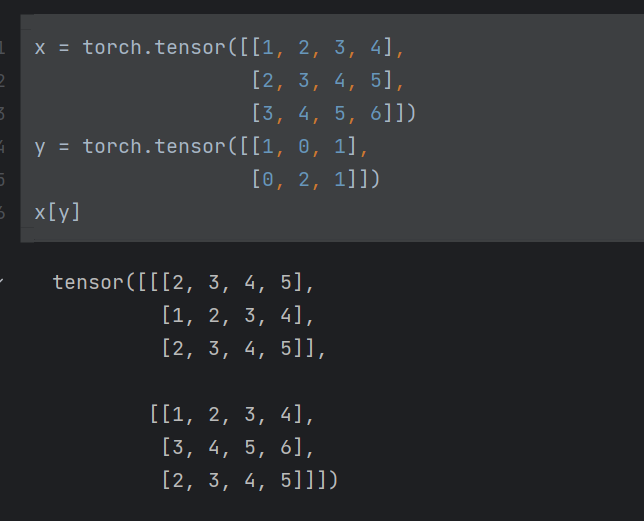
实现过程
y[0][0] = 1, 故取 x 的第一行,也就是[2, 3, 4, 5], 作为新tensor的第一行
y[0][1] = 0, 故取 x 的第零行,也就是[1, 2, 3, 4], 作为新tensor的第二行
y[0][2] = 1, 故取 x 的第一行,也就是[2, 3, 4, 5], 作为新tensor的第三行
以上作为第一个模块组
然后对y[1][i], for i in range[3], 按照上述方法取出来新tensor的第二个模块
最终形成了新tensor
总之:,y有几行,新tensor形成几个模块组,对 y 的每一行,里面的元素分别取 x 的对应行,作为该模块组的行
拓展
- int + tensor 作为 tensor 的索引
x = torch.tensor([[11, 12, 13, 14],
[22, 23, 24, 25],
[33, 34, 35, 36]])
y = torch.tensor([[1, 0, 1],
[0, 2, 1]])
x[0, y]
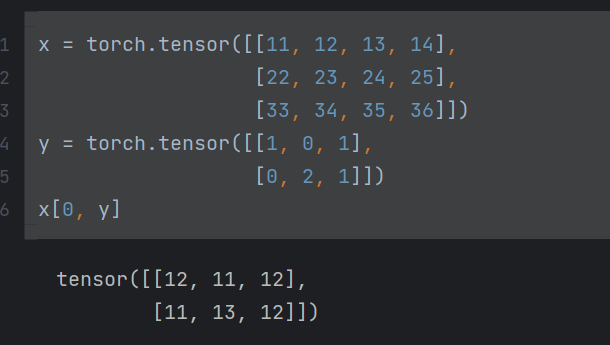
是对x的第零行进行选取,此时y中每一个[ ]中的数字代表选择第零行序号为该数字的元素,并且每个[ ]作为一组
- tensro + tensor 作为 tensor 的索引
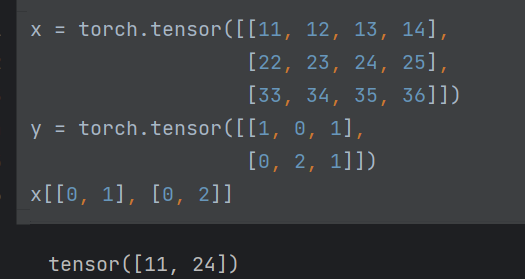
此时分别选取x的第0行第一个和第一行第2个元素,作为新tensor。
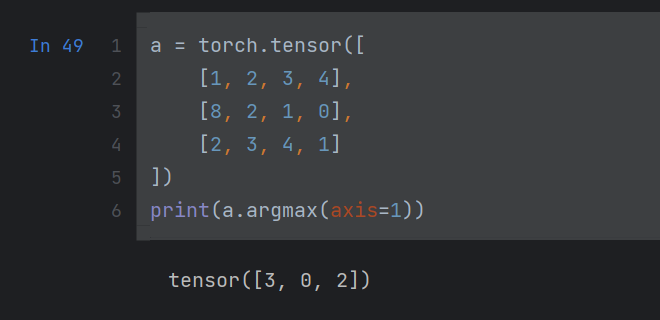
torch.argmax(input, dim=None, keepdim=False)
input: 输入的tensor
dim = 0: 求tensor中每一列中最大元素的下标
dim = 1: 求tensor中每一行中最大元素的下标
返回:返回一个tensor
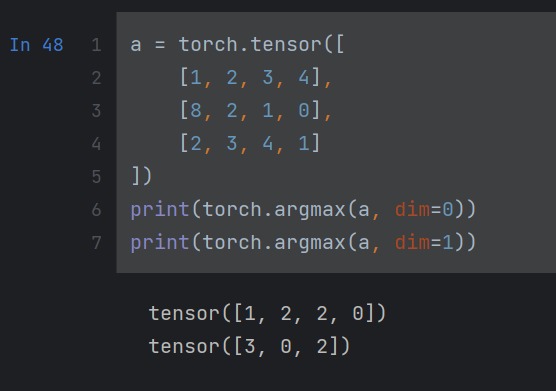
a.argmax(axis=)
a是一个tensor
用法与上个argmax一样,axis用法与dim一样
y.type(x.dtype)
y与x均是tensor,但tensor里面的数据类型可能不同
y.type(x.dtype) 的作用是将y中数据类型转为x中的数据类型
isinstance(a, b)
Python中函数中局部变量和全局变量同名时候:
参考
特点:
如果全局和函数中新的变量都为a,那么在函数中修改a的值,不会改变全局中的a的值,如果想在函数中使用全局变量a,需要加上关键词 global
a = 100
def testA():
print(a)
def testB():
a = 200
print(a)
print(a) # 100
print(testA()) # 100
print(testB()) # 200
print(testA()) # 100
def testB():
global a # 关键字声明a为全局变量,系统就会去找叫a的全局变量
a = 200
print(a)
nn.Sequential()创建的层:
import torch
from torh import nn
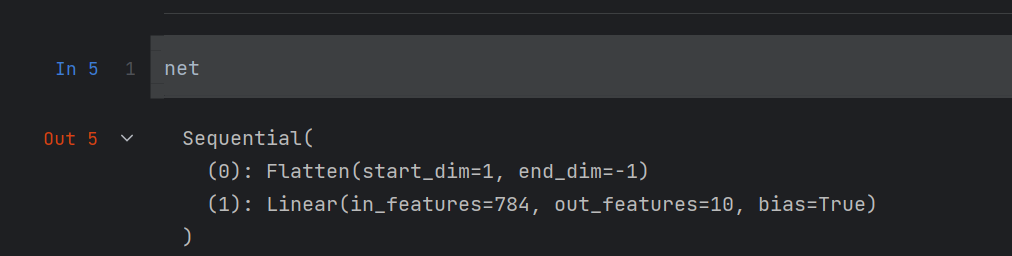
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
说明创建了一个net,有两层:
第一层:net[0],表示Flatten,即展平层
第二层:net[1],表示Linear,是线性层也就是全连接层
打印net:
Linear中,包含两个参数:
- weight
- bias
Linear层刻画了一个:\(y = xW + b\) 的全连接层,其中,W就是weight,b就是bias
对weight中的值进行操作,通过.data进行实现 - 打印weight:
net[1].weight.data
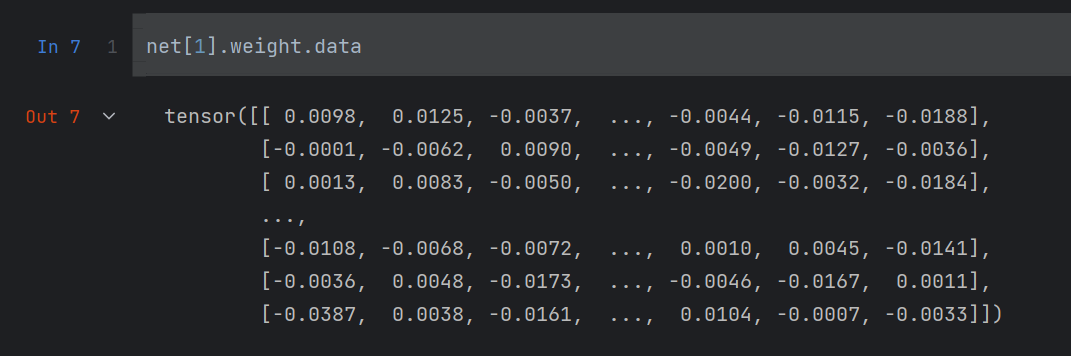
2. 对weight进行正态分布随机初始化
net[1].weight.data.normal_(0, 0.01)
初始化的结果就是上面的截图
net.apply(fn)函数
作用:对net的每一层调用它的参数fn函数
如:
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
print(m)
if type(m) == nn.Linear:
# print(m)
nn.init.normal_(m.weight, mean=0, std=0.01)
net.apply(init_weights)
结果:
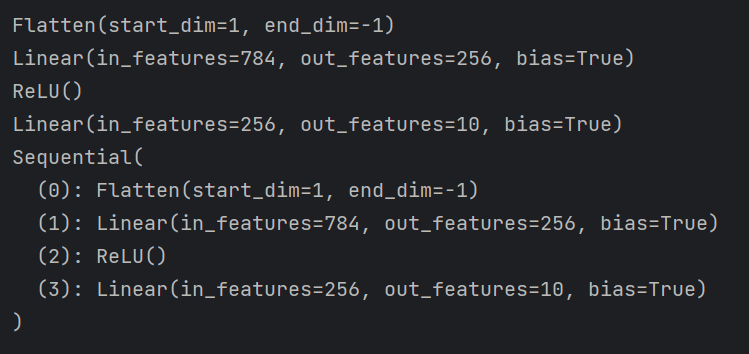
apply分别对神经网络net的每一层从Flatten到Sequntial调用了init_weights函数
nn.init.normal_()
参考
是对tensor进行正态分布初始化:
nn.init.normal(weight, mean=, std=)
mean: 均值
std: 标准差
卷积
在数学中,给定两个函数\(f(x)\)和\(g(x)\),它们的卷积定义为:
其中\(*\)表示卷积运算符,\(\tau\)是积分变量。
求两个函数的卷积可以使用积分来完成。具体来说,可以将其中一个函数翻转并平移,然后将两个函数相乘并对积分变量求积分。这个过程可以用图像的形式理解:将一个函数压缩并向右移动,另一个函数拉伸并向左移动,然后将它们的重叠部分相加。
以下是一个例子:设\(f(x) = e^{-x}\)和\(g(x) = x^2\)。它们的卷积为:
使用分部积分法可得到:
最终得到:
因此,\(f(x)\)和\(g(x)\)的卷积为\(2xe^{-x} - 2e^{-x} + 2\)。
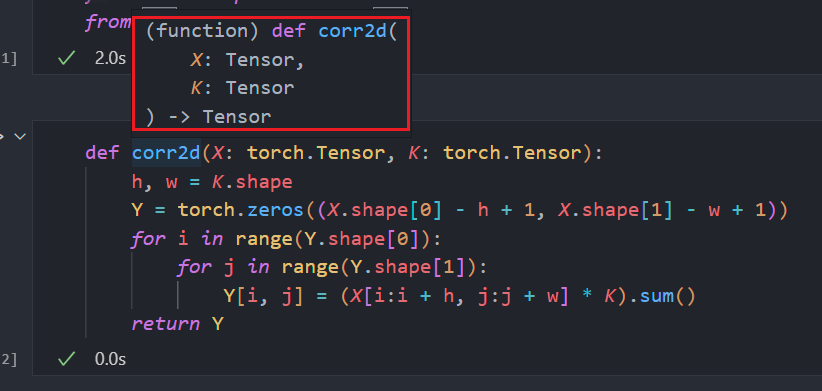
python 添加函数参数类型及其智能提示
def add(x:int, y:int) -> int:
return x + y
冒号和->后面均是参数类型表示,x,y均为int型,函数返回值为int型
此时IDE会进行智能提示:

如果参数类型是tensor,那么声明是:torch.Tensor,注意是大写,小写的话则不对如下:
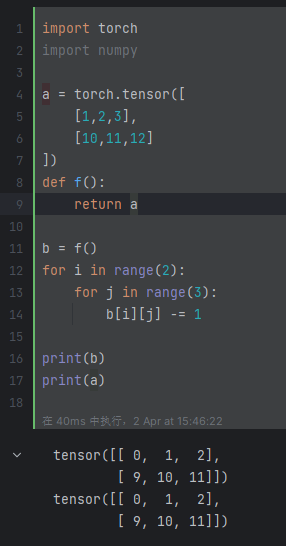
torch.tensor 与 numpy 执行等号复制时候,均是指针的复制,也就是指向了同一块内存
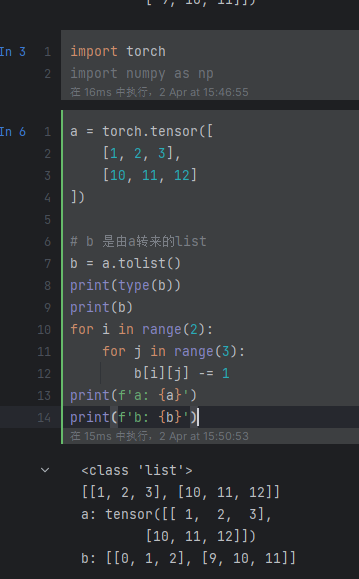
那么把tensor, numpy与list等相结合呢?
使用a.tolist(), (tensor与numpy均是这个)返回a的list形式,用的是另一块内存
tensor->list
numpy->list
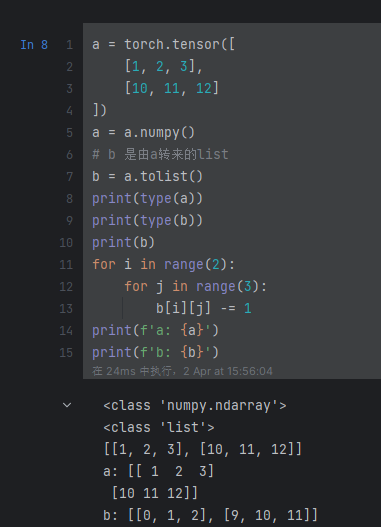
结论:转为list后,就与原来的numpy与tensor无关了,使用的就不是同一块内存单元了,且从list创建tensor,也是新用一块内存,也不会影响原来的list

 浙公网安备 33010602011771号
浙公网安备 33010602011771号