SQL学习笔记
1.常见的集中数据类型
- 1.char(n) , varchar(n)两个的区别是char(n)是固定空间,varchar(n)是动态的 //SQL中的字符串用单引号表示,不是双引号
- 2.int , Tinyint(-128~127), smallint.
- 3. double,float.
- 4.date(精确到日) datetime(精确到秒)
2.表的建立和删除
1.表的建立
create table biao --表名 ( sno varchar(50) not null,--决定数据是否可以为空 age int not null, name varchar(50) not null, sex varchar(50) not null, addr varchar(50) not null )
2.表的删除
drop table <表名> [RESTRICT|CASCADE] --RESTRICT如果该表有依赖(外键,触发器等)就不能删除 --CASCADE会连带依赖一起删除 --默认第一个
3.主键的插入删除
主键: 被设为主键的列在插入数据时不能出现重复数据。
两种方式,建表时插入或者建完后插入。
1、在表内插入主键
create table biao --建表时直接插入 ( sno varchar(50) primary key not null --在数据后直接设置 ) --该方法直接了当很方便,在只有一个主键的时候可以使用,但是有多个主键的时候这样就会报错,例如:
create table biao --这样就会报错 ( sno varchar(50) primary key not null, name varchar(50) primary key not null ) 正确做法是: create table biao ( sno varchar(50) not null, name varchar(50) not null, primary key(sno,name)--在最后设置主键 )
2、在表外插入主键
alter table text1 add (constraint)[约束名] primary key(sno);
3、主键的删除
SQL中删除主键只能通过约束名来删除,通常设置主键时如果不设约束名,会自动生成一个约束名。
alter table text1 drop (constraint)[PK__text1__DDDF6446A6EF60A0]--约束名称
4.外键的插入删除
外键: 就是通过其他表的主键数据来约束该列,该外键对应的主键插入了那些数据,那么外键就只能插入这些数据,即外键插入的数据必须在对应的主键存在。
例如: student表中sno(学号) 设为主键,那么其他表再用到学号就可以设为外键,保证这个学号有对应的学生。
1、表内插入
外键设置时注意,如果你外键所关联的那个主键不是唯一主键,那会报错
create table text2 ( sno varchar(50) not null, age int not null, foreign key(sno) references biao(sno) --前面为当前表要设为外键的列,后面为要关联的表中的列 )
2、表外插入
alter table text2 add foreign key (sno) references biao(sno)
3、删除
和主键一样,SQL中只能通过约束名来删除他们
alter table text2 drop [FK__text2__sno__5165187F];
5.对表内容修改
1.插入数据:
(1)insert into [表名] values(内容) . //默认插入全部数据
insert into text2 values('666','大聪明') --如果有几个值不想输入,可以设为空值,前提是该列可以为空值 insert into text2 values('123',null)
(2)insert into(选择你要赋值的列) values(给这几列对应赋值)
insert into student(sno,name,age,sex) values('123','小明',18,'男') --其中没有赋值的列会自动赋空值
2.更新数据:update [表名] set [列名] =‘更新后的值' (where =.....限制条件)
--更改学号为123的学生的年龄 update student set age=18 where sno='123' --将所有学生的年龄加1 update student set age=age+1 --带子查询的更新,将计算机学生的成绩更新为0 update sc set grade=0 where sno in(select sno from student where sdept='计算机')
3.在表中新添加一列
--添加age一列类型为int alter table student add age int
4.删除表中某一列
alter table class drop column age
5.删除某些记录: delete from <表名> [where条件]
--删除小明的记录 delete from class where name='小明' --同样可以进行所有记录的删除和子查询删除,与更新操作相同
6.check约束: 用来约束某一列或几列数据的数值。
create table ss ( sno varchar(50) primary key not null, grade int not null, check(grade>=0 and grade<=100)--成绩在0-100 )
6. 索引
索引: 可以快速查到想要的内容。
索引本质以及索引为什么可以提高查询效率可以看这位大佬的博客: https://blog.csdn.net/Fanbin168/article/details/29200545
索引类型: (1) 普通索引
(2) 唯一索引:索引指向的数据时唯一的
(3) 聚簇索引/非聚簇索引:
引用一下他人的例子:
图书馆的例子:一个图书馆那么多书,怎么管理呢?建立一个字母开头的目录,例如:a开头的书,在第一排,b开头的在第二排,这样在找什么书就好说了,这个就是一个聚集索引,可是很多人借书找某某作者的,不知道书名怎么办?图书管理员在写一个目录,某某作者的书分别在第几排,第几排,这就是一个非聚集索引 //https://blog.csdn.net/weixin_30517001/article/details/96502742
1.创建索引: create [索引类型] [cluster] index [索引名] on <表名>(列名....) //cluster表示聚簇索引,默认为非聚簇索引
--给stu表中的name 列添加了一个普通索引 create index index_1 on stu(name)
2.修改索引名: alter index <旧索引名> rename to <新索引名>
3.删除索引: drop index <索引名>
7.查询数据
1.单表查询
select 学号 from student select 学号 (as) 列名 from student--可以把要读取的列另取一个名字显示出来
2.查询的限制语句:
(1)where : where用来限制某个或几个条件
select * from 图书信息表 where 作者='方志远' select * from student where grade<80
(2) between, not between:判断是否在某个范围
select * from student where grade between 70 and 90 select * from student where grade not between 70 and 90 select * from student-- 这条与第二条等价 where grade<70 and grade >90
(3) In , not in:判断是否在给定的区间内
select * from student where sno in('123','166','177')
(4)Like 字符匹配:可以用来判断字符串是否相似,其中两种通配符' _ ' 和' % ',' _ '表示省略一个字符,‘ % ’表示省略了之后的所有字符
--查找表中姓刘的学生的全部信息 select * from student where name like'刘%' --查找前两个字是欧阳并且名字总共三个字的学生 select * from student where name like'欧阳_' --查找第二个字是欧阳的学生 select * from student where name like'_欧%' --所有不姓刘的学生 select * from student where name not like '刘%' --查询课程名为'DB_D的可能,所以要将其中的通配符功能关闭,让它变成普通字符,escape'\'表示'\'为换码字符,可以使得'_'失去通配符功能. select * from course where Cname Like 'DB\_D' escape'\'
(5)关于空值的查询:null,not null. 注意这里判断时不是用' = ' 而是用 is.
--查询成绩为非空的学生信息 select * from student where grade is not null
(6) 多重条件查询 and,or
--查询年龄小于20的男生 select * from student where age<20 and sex='男' --查询年龄小于20的男生或者年龄小于18的女生 select * from student where (age<20 and sex='男') or (age<18 and sex='女生')
3.聚集函数,方便检索功能
(1) count(*) :统计元组个数( 就是查现在表中还有了几条数据)
(2) count( [ DISTINCT | ALL ] <列名>): 统计一列中值的个数,其中DISTINCT表示去重,不加则默认ALL
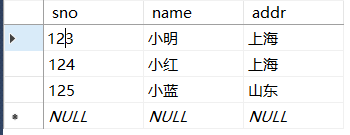
假如现在有这样一个表,我们查找表中的人都来自多少种城市。
--对表中的地址进行去重 select count(DISTINCT addr) from class;
(2)sum( [ DISTINCT | ALL ] <列名>):计算一列值的总和 /*/必须是数值型
(3)AVG( [ DISTINCT | ALL ] <列名>):计算平均值 /*/必须是数值型
(4)MAX( [ DISTINCT | ALL ] <列名>):求最大值
(5)MIN( [ DISTINCT | ALL ] <列名>):求最小值
4.group by语句,用于配合聚集函数使用,一般用于显示某一种的信息的和等
--显示每个班级的总成绩和最高成绩 select cla,sum(grade) grade,max(grade) from class group by cla --查询的参数只能是聚集函数或者group by的参数
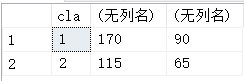
5.having :与where功能相似,但是having是用来对聚集函数进行筛选的
--筛选最大成绩大于90的 select sum(grade) ,max(grade) from class having max(grade)>90
6.多表关联查询 : 可以同时查询多个表满足条件的数据,就是把每一个表满足条件的所需要的数据查询出来
--查询每个学生的学号,姓名,学科,成绩 select a.sno,a.name,b.cname,c.grade from stu a,course b,grade c where a.sno=b.sno and a.sno=c.sno--这里要限制每一个表每次查询,否则数据就不是一一对应
7.相关子查询 : 就是限制条件不再是某一个直接给定的值,而是通过查询得到的一个或几个值,一般用来通过查询其他表来限制该表的查询。
--查询成绩低于70的学生的学号,姓名 select sno,name from stu where sno in(select sno from grade where grade<70)
8. ANY和 ALL :一般配合<或>使用
其中 ‘<>' 等价于 '!=' 一般any的语句都可以用聚集函数和having代替。
--查询非计算机系中比计算机系任意一个学生的年龄小的学生姓名年龄 select name,age from stu where age<any(select age from stu where sdept='CS') and sdept<>'CS'; --查询非计算机系中比计算机系所有学生的年龄小的学生姓名年龄 select name,age from stu where age<all(select age from stu where sdept='CS') and sdept<>'CS';
9.EXISTS谓词子查询
EXISTS类似于c++中的bool,只有'true'和'false'两种逻辑值
其实相当于遍历了每一组数据,用EXISTS判断它符不符合条件,符合就输出,不符合就不输出
--查询选修了一号课程的学生信息 select sno,name from stu where exists(select * from course where sno=stu.sno and cno='1')
8.视图
视图是由一个或几个表导出来的表,但它是一个虚表,一般用于满足查询需求。//视图的每一列列名都不能为空
1.建立视图: create view [视图名] as select [要包含的数据] from <表名> [where条件]
--建立学生学号和姓名的视图 create view view_stu as select sno,name from stu --视图同样可以多表关联建立 create view view_1 as select a.sno,a.name,b.cname,c.grade from stu a,course b,grade c --也可以使用聚集函数和group by 建立视图 create view view_2(sno,g)--括号内的表示每一列的名字,建立视图每一列都要有列名,不能为空,而聚集函数要单独赋名 as select sno,sum(grade) from grade group by sno; create view view_2--也可以这样赋名 as select sno,sum(grade) sumgrade from grade group by sno
2.视图的查询:视图查询的基本操作与表相同
视图的查询还可以与基本表相结合
--查询选修了课程1的学生信息 select a.sno,a.name from view_1 a,sc b where view_1.sno=sc.sno and sc.cno='1'
3.视图的更新:
视图可以直接用Insert往里插入数据,也可以用update 更新,与基本表相同
update <视图名> set 列名 =... where ...
insert into <视图名> values (......)
4.视图的删除
delete from <视图名> where ....
9.存储过程
存储过程就是一个预编译的SQL语句,可以随时手动执行,非常类似于一个全局函数。
1.创建存储过程: create proc <存储名> (参数) as [要执行的内容] //可以无参数
create proc solve(@a varchar(50)) as select * from stu where sno=@a --接受一个参数的存储过程,查询该学号的学生信息
2.执行存储过程: exec <存储过程名> [参数] //注意执行存储过程时,参数不需要用括号括起来
exec solve '123'
10. 回滚操作
回滚操作就是一直回退到前面的某一部分,并将从回退部分开始到后面的操作取消的操作。
create proc sa(@a int) as BEGIN TRANSACTION AddBook update stu set name='小明' where sno='123' update stu set name='小王' where sno='124' IF @a >= 2 BEGIN ROLLBACK TRANSACTION AddBook END ELSE BEGIN COMMIT TRANSACTION AddStudent END --如果@a<2则修改表中的值,否则就不执行
11.授权
1.grant : 赋予目标权限
grant <权限> on <对象类型> <对象名> on <用户>
grant可以赋予的权限种类
DDL:create、alter、drop
DML:select、insert、delete、update、index、createview、showview
全部权限: all privileges
--赋予对stu表的查询权限 grant select on table stu to u1 with grant option--这是可以让用户把该权限再给别人
2.revoke: 收回目标权限
revoke <权限> on <对象类型> <对象名> from <用户>
revoke select on table stu from u1 cascade--cascade级联,可以收回u1及u1所给予权限的用户
暂停
--延迟几秒 waitfor delay '00:00:05' print '下课了!' --到几点运行 waitfor time '00:00:05' print '下课了!'
