深度学习复习
1.深度学习的那些大牛们
- ”约书亚·本吉奥(Yoshua Bengio)、杰弗里·辛顿(Geoffrey Hinton)和杨乐昆(Yann LeCun)
https://baijiahao.baidu.com/s?id=1629243641618010999 - Hinton
https://zhuanlan.zhihu.com/p/22405961 - Yann LeCun:
https://blog.csdn.net/hacker_long/article/details/89609367 - Yoshua Bengio(约书亚·本吉奥)
http://www.techwalker.com/2017/1225/3102141.shtml - Jürgen Schmidhuber
http://www.elecfans.com/d/902176.html - 中美人工智能高被引学者Top 50榜单:孙剑、何恺明、李飞飞进前5
https://zhuanlan.zhihu.com/p/77252344 - 孙剑
- 任少卿
https://www.d1ev.com/news/qiye/123231 - 张祥雨
- 何恺明
https://baike.baidu.com/item/何恺明/22863446?fr=aladdin - 李飞飞
备注:
各个知识点大家需要掌握其定义(概念),作用,优缺点
2.全连接网络 第4章
需要掌握的知识:
重点:
PPT: week08神经网络入门.pdf 或 Python神经网络编程高清版.pdf
前向传播过程:
在神经网络中,信息从上一个神经元直接流转到下一个神经元,直到输出,依据每一个神经元的输入并根据相应规则可以计算出输出,最终得到在当前参数下的损失函数的过程,称为前向传播。
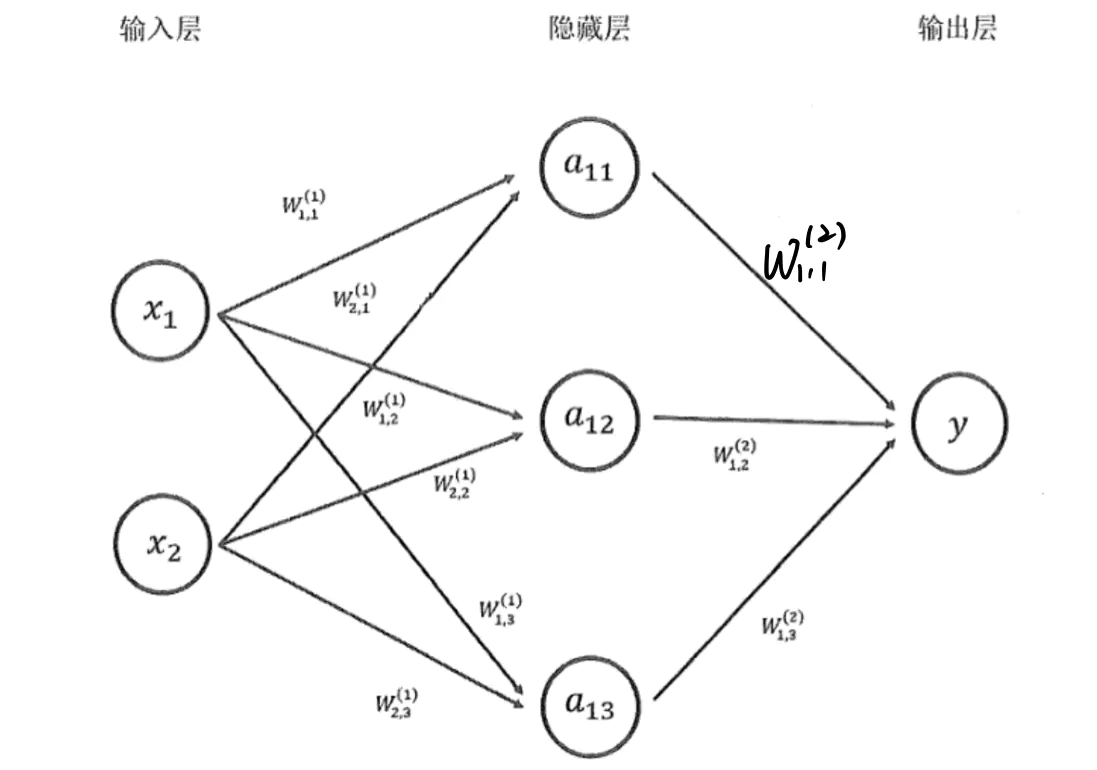
反向传播过程:
反向传播算法是在前向传播算法的基础上,从神经网络的输出层向输入层依次计算损失函数对于各个参数的梯度,并在给定学习率下更新相关参数。
利用前向传播算法和反向传播算法不断更新损失函数的值和参数,直到损失函数下降到指定的阈值(或者最小值),即完成神经网络的训练
教材
P75-78
激活函数
在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。 那么激活函数应该具有什么样的性质呢?
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate
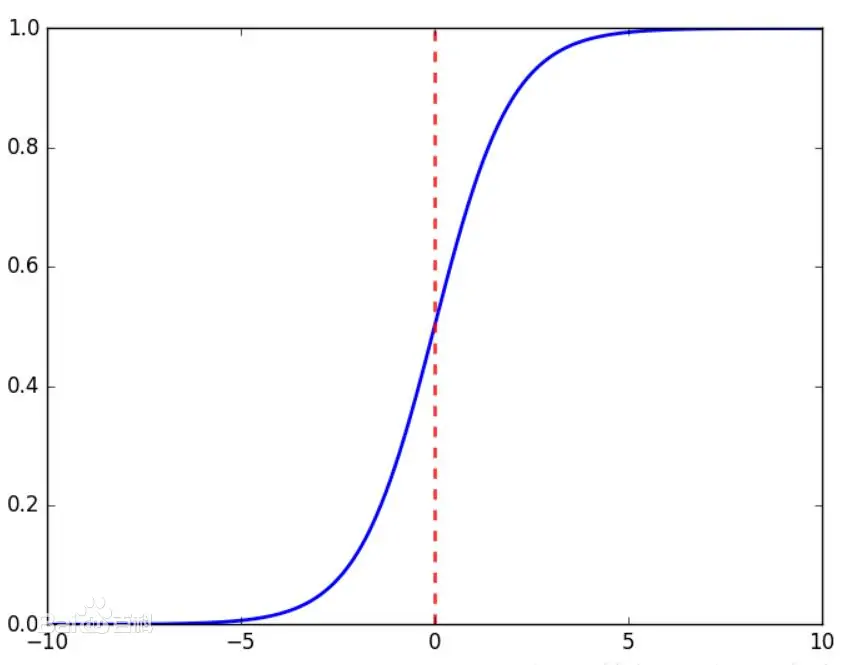
sigmod
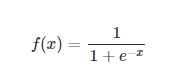
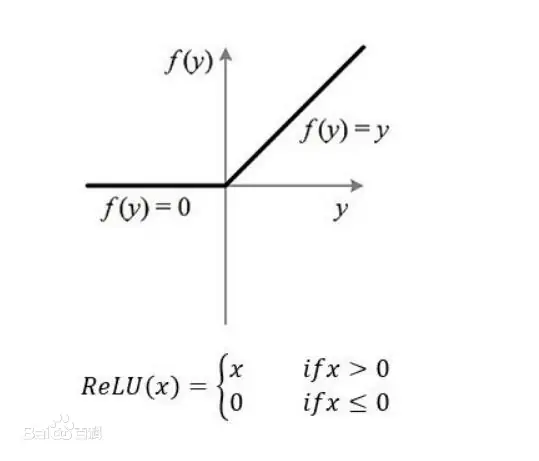
relu
Relu激活函数(The Rectified Linear Unit),用于隐层神经元输出。公式如下
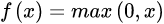
P85~P104
损失函数
在神经网络中,衡量预测网络与真实值y之间差别的指标成为损失函数;损失函数越小,表示神经网络的预测结果越接近真实值
神经网络的调整就是调整权重W和偏置b使得损失函数值尽可能地小。神经网络解决的问题主要分为分类问题和回归问题
分类是输出变量为有限个离散变量的预测问题,目的是寻找决策边界。
回归问题是输入变量与输出变量均为连续变量的预测问题,目的是寻找最优的拟合方法。
分类损失包括
分类损失函数
负对数似然损失
交叉熵损失
回归类损失
均方误差
平均绝对值误差
均方对数误差
Huber损失
Log—Cosh损失函数
学习率:梯度下降的步长
4.4 提升神经网络训练的技巧
4.4.1参数更新方法
SGD 1
随机梯度下降
批量梯度下降(BGD)
Momentum 2
动量
使得梯度在方向不变的维度上速度变快,方向有所改变的维度上的更新速度变慢,这样就可以加快收敛减小震荡
Adagrad 4
自适应的算法可以根据参数更新的频率来调整他们更新的速度,对低频的参数作较大的更新,对高频的参数做较小的更新,适用于一些数据分布不均匀的任务,可以更好的平衡参数更新的量,提升模型的能力
RMSprop 6
RMS中用于滑动平均的方法还解决Adagrad中学习率急剧下降的问题,RMSProp希望梯度的积累项G按一定的比率衰减,因此使用一个滑动窗口限制G。
他的提出者Hinton建议设定平衡因子为0.9,学习率为0.001
Adam 7
自适应矩阵估计结合了基于动量的优化方法与基于自适应学习率的优化方法,保存了过去梯度的指数衰减平均值,将其作为动量与过去梯度的平方的指数的衰减平均值来构造学习率自适应因子
4.4.2数据预处理
归一化
提高深度学习算法的效率
三种常用的数据预处理方法
0均值:所有样本减去总体数据的平均值,适用于各维度分布相同的数据
缩放:将不同维度差异较大的数据缩放到统一的尺度以利于模型处理
归一化:各维度数据减去各维度的均值后除以各维度的标准差
4.4.4 正则化
正则化用于解决有些模型因强大的表征能力而产生测试数据过拟合等现象,通过避免训练数据完美拟合数据样本的模型来加强算法的泛化能力
可以避免数据过拟合
常见方法以及作用
1.数据增强
数据增强是提升算法性能满足深度学习模型对大量数据需求的重要工具。过拟合可以认为是模型对数据集中噪声和细节的过度捕捉,防止过拟合的最简单有效的方法就是增大训练数据量,标记成本的成本较高,因此数据增强通过向训练数据添加转换或扰动来人工增加训练数据集。
2.权重衰减
L1
L1指一范数,长写为绝对值和的形式
L2
L2指二范数,长写为平方和的形式
L1,L2正则化通过修改损失函数实现
3.Dropout
指暂时丢弃一部分神经元及其连接,通过修改网络结构实现
Dropout可以看作是多种神经网络的集成
4.提前停止
限制模型最小化代价函数所需要的训练迭代次数
防止训练中过拟合的模型泛化性能差
4.5深度学习框架
4.5.1
易用性
高效性
4.5.2常见的深度学习框架
飞浆:易学,易用,安全,高效
tensorFlow
caffe
kares
4.5.3飞桨的概述
3.卷积神经网络-第5章
5.1什么是卷积神经网络(yann LeCun)
http://aix.51cto.com/blog/71445.html
CNN 是一种具有局部链接,权重共享等特性的前馈神经网络
前馈神经网络:
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。是目前应用最广泛、发展最迅速的人工神经网络之一。
5.2卷积神经网络的整体结构
卷积层,池化层,全连接层
卷积神经网络中输入/输出数据称之为特征图
5.3卷积层
卷积层会对输入的特征图进行卷积操作,输出卷积后产生的特征图。卷积层是卷积神经网络的核心部分,卷积层的加入使得神经网络能够共享权重,能够进行局部感知,并开始层次化的对图像进行抽象理解
掌握卷积的计算
给你输入计算输出大小
卷积 空洞卷积
5.4池化层
了解常见的池化层
最大池化
平均池化
5.7典型的卷积神经网络
包括网络背景,特点
LeNet
AlexNet
GooleNet
VGG
ResNet
4.循环神经网络-第6章
为什么自然语音处理需要循环神经网络
RNN
描绘RNN的基本结构,并说明特点
LSTM
描绘LSTM的基本结构,并说明特点
GRU
描绘GRU的基本结构,并说明特点
Seq2Seq
描绘Seq2Seq的基本结构,并说明特点
Attention
描绘Attention的基本结构,并说明特点
transform 和 Bert
自己选择看
5.计算机视觉-第8章
计算机视觉的应用场景及其代表网络,及其网络特点
6.自然语言处理NLP-第9章
NLP的基本过程
P242-P253
NLP的应用场景
7.代码实践
python实现神经网络
https://aistudio.baidu.com/aistudio/projectdetail/1840078
中草药识别
https://aistudio.baidu.com/aistudio/projectdetail/1917643
