Python---8函数(函数的参数&递归函数)
一、函数的参数
Python的函数定义非常简单,但灵活度却非常大。除了正常定义的必选参数外,还可以使用默认参数、可变参数和关键字参数,使得函数定义出来的接口,不但能处理复杂的参数,还可以简化调用者的代码。
1、位置参数 a(b,c)【b,c必须输入,不输入报错】
我们先写一个计算x2的函数:
def power(x):
return x * x
对于power(x)函数,参数x就是一个位置参数。
当我们调用power函数时,必须传入有且仅有的一个参数x:
>>> power(5)
25
>>> power(15)
225
现在,如果我们要计算x3怎么办?可以再定义一个power3函数,但是如果要计算x4、x5……怎么办?我们不可能定义无限多个函数。
你也许想到了,可以把power(x)修改为power(x, n),用来计算xn,说干就干:
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
对于这个修改后的power(x, n)函数,可以计算任意n次方:
>>> power(5, 2)
25
>>> power(5, 3)
125
修改后的power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
2、默认参数 a(a,b=1)
新的power(x, n)函数定义没有问题,但是,旧的调用代码失败了,原因是我们增加了一个参数,导致旧的代码因为缺少一个参数而无法正常调用:
>>> power(5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: power() missing 1 required positional argument: 'n'
输入:![]() 输出:
输出:![]()
 输出:
输出:
Python的错误信息很明确:调用函数power()缺少了一个位置参数n。
这个时候,默认参数就排上用场了。由于我们经常计算x2,所以,完全可以把第二个参数n的默认值设定为2:
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
这样,当我们调用power(5)时,相当于调用power(5, 2):
>>> power(5)
25
>>> power(5, 2)
25
而对于n > 2的其他情况,就必须明确地传入n,比如power(5, 3)。
输入: 输出:
输出: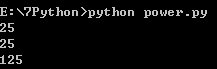
从上面的例子可以看出,默认参数可以简化函数的调用。设置默认参数时,有几点要注意:
一是必选参数在前,默认参数在后,否则Python的解释器会报错;
二是如何设置默认参数:当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
使用默认参数有什么好处?最大的好处是能降低调用函数的难度。
举个例子,我们写个一年级小学生注册的函数,需要传入name和gender两个参数:
def enroll(name, gender):
print('name:', name)
print('gender:', gender)
这样,调用enroll()函数只需要传入两个参数:
>>> enroll('Sarah', 'F')
name: Sarah
gender: F
如果要继续传入年龄、城市等信息怎么办?这样会使得调用函数的复杂度大大增加。
我们可以把年龄和城市设为默认参数:
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)
这样,大多数学生注册时不需要提供年龄和城市,只提供必须的两个参数:
>>> enroll('Sarah', 'F')
name: Sarah
gender: F
age: 6
city: Beijing
只有与默认参数不符的学生才需要提供额外的信息:
enroll('Bob', 'M', 7)
enroll('Adam', 'M', city='Tianjin')
可见,默认参数降低了函数调用的难度,而一旦需要更复杂的调用时,又可以传递更多的参数来实现。无论是简单调用还是复杂调用,函数只需要定义一个。
输入: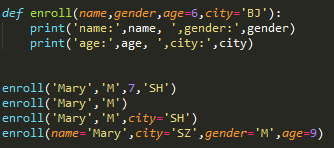 输出:
输出: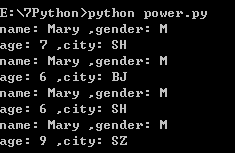
可见,默认参数降低了函数调用的难度,而一旦需要更复杂的调用时,又可以传递更多的参数来实现。无论是简单调用还是复杂调用,函数只需要定义一个。
有多个默认参数时,调用的时候,既可以按顺序提供默认参数,比如调用enroll('Bob', 'M', 7),意思是,除了name,gender这两个参数外,最后1个参数应用在参数age上,city参数由于没有提供,仍然使用默认值。
也可以不按顺序提供部分默认参数。当不按顺序提供部分默认参数时,需要把参数名写上。比如调用enroll('Adam', 'M', city='Tianjin'),意思是,city参数用传进去的值,其他默认参数继续使用默认值。
默认参数很有用,但使用不当,也会掉坑里。默认参数有个最大的坑,演示如下:
先定义一个函数,传入一个list,添加一个END再返回:
def add_end(L=[]):
L.append('END')
return L
当你正常调用时,结果似乎不错:
>>> add_end([1, 2, 3])
[1, 2, 3, 'END']
>>> add_end(['x', 'y', 'z'])
['x', 'y', 'z', 'END']
当你使用默认参数调用时,一开始结果也是对的:
>>> add_end()
['END']
但是,再次调用add_end()时,结果就不对了:
>>> add_end()
['END', 'END']
>>> add_end()
['END', 'END', 'END']
很多初学者很疑惑,默认参数是[],但是函数似乎每次都“记住了”上次添加了'END'后的list。
原因解释如下:
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
要修改上面的例子,我们可以用None这个不变对象来实现:
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L
现在,无论调用多少次,都不会有问题:
>>> add_end()
['END']
>>> add_end()
['END']
设计str、None这样的不变对象原因:不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。我们在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。
3、可变参数 a(*b)【b实际调用是list/tuple】
在Python函数中,还可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
我们以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2 + ……。
要定义出这个函数,我们必须确定输入的参数。由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
但是调用的时候,需要先组装出一个list或tuple:
>>> calc([1, 2, 3]) 14 >>> calc((1, 3, 5, 7)) 84
如果利用可变参数,调用函数的方式可以简化成这样:
>>> calc(1, 2, 3) 14 >>> calc(1, 3, 5, 7) 84
所以,我们把函数的参数改为可变参数:
def calc(*numbers): sum = 0 for n in numbers: sum = sum + n * n return sum
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数(不超过2个,超过报错),包括0个参数:
>>> calc(1, 2) 5 >>> calc() 0
如果已经有一个list或者tuple,要调用一个可变参数怎么办?可以这样做:
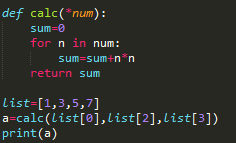
>>> nums = [1, 2, 3]
>>> calc(nums[0], nums[1], nums[2])
14

这种写法当然是可行的,问题是太繁琐,所以Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
>>> nums = [1, 2, 3]
>>> calc(*nums)
14
*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
4、关键字参数 a(**b)【b实际是dict】
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。请看示例:
def person(name, age, **kw): print('name:', name, 'age:', age, 'other:', kw)
函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数:
>>> person('Michael', 30) name: Michael age: 30 other: {}
也可以传入任意个数的关键字参数:
>>> person('Bob', 35, city='Beijing') name: Bob age: 35 other: {'city': 'Beijing'} >>> person('Adam', 45, gender='M', job='Engineer') name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
先声明一个dict
>>> extra = {'city': 'Beijing', 'job': 'Engineer'} >>> person('Jack', 24, city=extra['city'], job=extra['job']) name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
当然,上面复杂的调用可以用简化的写法:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
5、命名关键字参数 a(a,b,*,c,d)[c,d就是位置参数,必须输入dict],
a(a,b,*args,c,d)[可变参数只输入值,c,d就是位置参数,必须输入dict]
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
仍以person()函数为例,我们希望检查是否有city和job参数:
def person(name, age, **kw): if 'city' in kw: # 有city参数 pass if 'job' in kw: # 有job参数 pass print('name:', name, 'age:', age, 'other:', kw)
但是调用者仍可以传入不受限制的关键字参数:
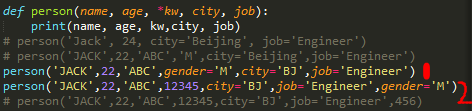
>>> person('Jack', 24, city='Beijing', addr='Chaoyang', zipcode=123456)
输出:![]()

1)如果要限制关键字参数的名字,就可以用命名关键字参数,在关键字参数前面,增加一个*参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job): print(name, age, city, job)
调用方式如下:
>>> person('Jack', 24, city='Beijing', job='Engineer')
Jack 24 Beijing Engineer
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
输入: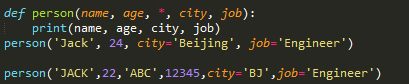
输出:
2)如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job): print(name, age, args, city, job)
输入: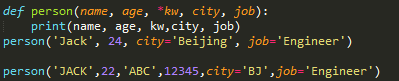
输出:
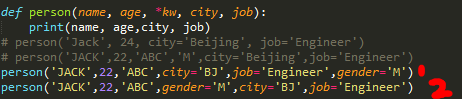
调用时,命名关键字参数必须传入参数名,形成键值对的格式,这和位置参数不同,即:city='BJ',job='Engineer'格式。
而可变参数只能输入值,不能是键值对方式,否则key未声明。
如果没有传入参数名,调用将报错:由于调用时缺少参数名city和job,Python解释器把这4个参数均视为位置参数,但person()函数仅接受2个位置参数。
>>> person('Jack', 24, 'Beijing', 'Engineer') Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: person() takes 2 positional arguments but 4 were given
====》因此,命名关键字参数可以有缺省值,从而简化调用为一个*的参数方法:
def person(name, age, *, city='Beijing', job): print(name, age, city, job)
由于命名关键字参数city具有默认值,调用时,可不传入city参数:
>>> person('Jack', 24, job='Engineer') Jack 24 Beijing Engineer
使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个*作为特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数:
def person(name, age, city, job): # 缺少 *,city和job被视为位置参数 pass
===》小结:
正确输入1:
正确输入2:
正确输入3: 
正确输出:
----------------------------------------------------------------------------------------------------------------------------------------
错误输入1: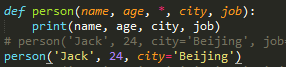
错误输出1:
错误输入2: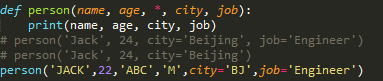
错误输出2:
错误输入3:
错误 输出3:
错误输入4: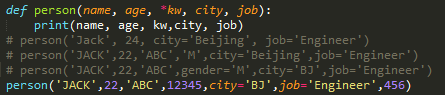
错误输出4:
6、参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw): print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw) def f2(a, b, c=0, *, d, **kw): print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
>>> f1(1, 2) a = 1 b = 2 c = 0 args = () kw = {} >>> f1(1, 2, c=3) a = 1 b = 2 c = 3 args = () kw = {} >>> f1(1, 2, 3, 'a', 'b') a = 1 b = 2 c = 3 args = ('a', 'b') kw = {} >>> f1(1, 2, 3, 'a', 'b', x=99) a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99} >>> f2(1, 2, d=99, ext=None) a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
注意:关键字参数**kw,后面不可以接别的参数。只能放在最后一项。
如输入:
输出: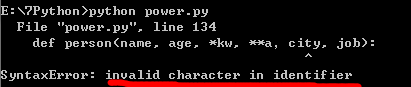
最神奇的是通过一个tuple和dict,你也可以调用上述函数:
>>> args = (1, 2, 3, 4) >>> kw = {'d': 99, 'x': '#'} >>> f1(*args, **kw) a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'} >>> args = (1, 2, 3) >>> kw = {'d': 88, 'x': '#'} >>> f2(*args, **kw) a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}
所以,对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
函数的参数
定义函数的时候,我们把参数的名字和位置确定下来,函数的接口定义就完成了。对于函数的调用者来说,只需要知道如何传递正确的参数,以及函数将返回什么样的值就够了,函数内部的复杂逻辑被封装起来,调用者无需了解。
Python的函数定义非常简单,但灵活度却非常大。除了正常定义的必选参数外,还可以使用默认参数、可变参数和关键字参数,使得函数定义出来的接口,不但能处理复杂的参数,还可以简化调用者的代码。
位置参数
我们先写一个计算x2的函数:
def power(x):
return x * x
对于power(x)函数,参数x就是一个位置参数。
当我们调用power函数时,必须传入有且仅有的一个参数x:
>>> power(5)
25
>>> power(15)
225
现在,如果我们要计算x3怎么办?可以再定义一个power3函数,但是如果要计算x4、x5……怎么办?我们不可能定义无限多个函数。
你也许想到了,可以把power(x)修改为power(x, n),用来计算xn,说干就干:
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
对于这个修改后的power(x, n)函数,可以计算任意n次方:
>>> power(5, 2)
25
>>> power(5, 3)
125
修改后的power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
默认参数
新的power(x, n)函数定义没有问题,但是,旧的调用代码失败了,原因是我们增加了一个参数,导致旧的代码因为缺少一个参数而无法正常调用:
>>> power(5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: power() missing 1 required positional argument: 'n'
Python的错误信息很明确:调用函数power()缺少了一个位置参数n。
这个时候,默认参数就排上用场了。由于我们经常计算x2,所以,完全可以把第二个参数n的默认值设定为2:
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
这样,当我们调用power(5)时,相当于调用power(5, 2):
>>> power(5)
25
>>> power(5, 2)
25
而对于n > 2的其他情况,就必须明确地传入n,比如power(5, 3)。
从上面的例子可以看出,默认参数可以简化函数的调用。设置默认参数时,有几点要注意:
一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面);
二是如何设置默认参数。
当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
使用默认参数有什么好处?最大的好处是能降低调用函数的难度。
举个例子,我们写个一年级小学生注册的函数,需要传入name和gender两个参数:
def enroll(name, gender):
print('name:', name)
print('gender:', gender)
这样,调用enroll()函数只需要传入两个参数:
>>> enroll('Sarah', 'F')
name: Sarah
gender: F
如果要继续传入年龄、城市等信息怎么办?这样会使得调用函数的复杂度大大增加。
我们可以把年龄和城市设为默认参数:
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)
这样,大多数学生注册时不需要提供年龄和城市,只提供必须的两个参数:
>>> enroll('Sarah', 'F')
name: Sarah
gender: F
age: 6
city: Beijing
只有与默认参数不符的学生才需要提供额外的信息:
enroll('Bob', 'M', 7)
enroll('Adam', 'M', city='Tianjin')
可见,默认参数降低了函数调用的难度,而一旦需要更复杂的调用时,又可以传递更多的参数来实现。无论是简单调用还是复杂调用,函数只需要定义一个。
有多个默认参数时,调用的时候,既可以按顺序提供默认参数,比如调用enroll('Bob', 'M', 7),意思是,除了name,gender这两个参数外,最后1个参数应用在参数age上,city参数由于没有提供,仍然使用默认值。
也可以不按顺序提供部分默认参数。当不按顺序提供部分默认参数时,需要把参数名写上。比如调用enroll('Adam', 'M', city='Tianjin'),意思是,city参数用传进去的值,其他默认参数继续使用默认值。
默认参数很有用,但使用不当,也会掉坑里。默认参数有个最大的坑,演示如下:
先定义一个函数,传入一个list,添加一个END再返回:
def add_end(L=[]):
L.append('END')
return L
当你正常调用时,结果似乎不错:
>>> add_end([1, 2, 3])
[1, 2, 3, 'END']
>>> add_end(['x', 'y', 'z'])
['x', 'y', 'z', 'END']
当你使用默认参数调用时,一开始结果也是对的:
>>> add_end()
['END']
但是,再次调用add_end()时,结果就不对了:
>>> add_end()
['END', 'END']
>>> add_end()
['END', 'END', 'END']
很多初学者很疑惑,默认参数是[],但是函数似乎每次都“记住了”上次添加了'END'后的list。
原因解释如下:
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
要修改上面的例子,我们可以用None这个不变对象来实现:
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L
现在,无论调用多少次,都不会有问题:
>>> add_end()
['END']
>>> add_end()
['END']
为什么要设计str、None这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。我们在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。
可变参数
在Python函数中,还可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
我们以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2 + ……。
要定义出这个函数,我们必须确定输入的参数。由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
但是调用的时候,需要先组装出一个list或tuple:
>>> calc([1, 2, 3])
14
>>> calc((1, 3, 5, 7))
84
如果利用可变参数,调用函数的方式可以简化成这样:
>>> calc(1, 2, 3)
14
>>> calc(1, 3, 5, 7)
84
所以,我们把函数的参数改为可变参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
>>> calc(1, 2)
5
>>> calc()
0
如果已经有一个list或者tuple,要调用一个可变参数怎么办?可以这样做:
>>> nums = [1, 2, 3]
>>> calc(nums[0], nums[1], nums[2])
14
这种写法当然是可行的,问题是太繁琐,所以Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
>>> nums = [1, 2, 3]
>>> calc(*nums)
14
*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数:
>>> person('Michael', 30)
name: Michael age: 30 other: {}
也可以传入任意个数的关键字参数:
>>> person('Bob', 35, city='Beijing')
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
和可变参数类似,也可以先组装出一个dict,然后,把该dict转换为关键字参数传进去:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, city=extra['city'], job=extra['job'])
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
当然,上面复杂的调用可以用简化的写法:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
仍以person()函数为例,我们希望检查是否有city和job参数:
def person(name, age, **kw):
if 'city' in kw:
# 有city参数
pass
if 'job' in kw:
# 有job参数
pass
print('name:', name, 'age:', age, 'other:', kw)
但是调用者仍可以传入不受限制的关键字参数:
>>> person('Jack', 24, city='Beijing', addr='Chaoyang', zipcode=123456)
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job):
print(name, age, city, job)
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
调用方式如下:
>>> person('Jack', 24, city='Beijing', job='Engineer')
Jack 24 Beijing Engineer
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job):
print(name, age, args, city, job)
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错:
>>> person('Jack', 24, 'Beijing', 'Engineer')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: person() takes 2 positional arguments but 4 were given
由于调用时缺少参数名city和job,Python解释器把这4个参数均视为位置参数,但person()函数仅接受2个位置参数。
命名关键字参数可以有缺省值,从而简化调用:
def person(name, age, *, city='Beijing', job):
print(name, age, city, job)
由于命名关键字参数city具有默认值,调用时,可不传入city参数:
>>> person('Jack', 24, job='Engineer')
Jack 24 Beijing Engineer
使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个*作为特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数:
def person(name, age, city, job):
# 缺少 *,city和job被视为位置参数
pass
参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
>>> f1(1, 2)
a = 1 b = 2 c = 0 args = () kw = {}
>>> f1(1, 2, c=3)
a = 1 b = 2 c = 3 args = () kw = {}
>>> f1(1, 2, 3, 'a', 'b')
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
>>> f1(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
>>> f2(1, 2, d=99, ext=None)
a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
最神奇的是通过一个tuple和dict,你也可以调用上述函数:
>>> args = (1, 2, 3, 4)
>>> kw = {'d': 99, 'x': '#'}
>>> f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
>>> args = (1, 2, 3)
>>> kw = {'d': 88, 'x': '#'}
>>> f2(*args, **kw)
a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}
所以,对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
小结
Python的函数具有非常灵活的参数形态,既可以实现简单的调用,又可以传入非常复杂的参数。
默认参数一定要用不可变对象,如果是可变对象,程序运行时会有逻辑错误!
要注意定义可变参数和关键字参数的语法:
*args是可变参数,args接收的是一个tuple;
**kw是关键字参数,kw接收的是一个dict。
以及调用函数时如何传入可变参数和关键字参数的语法:
可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过*args传入:func(*(1, 2, 3));
关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过**kw传入:func(**{'a': 1, 'b': 2})。
使用*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符*,否则定义的将是位置参数。
二、递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
举个例子,我们来计算阶乘n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示,可以看出:
fact(n) = n! = 1 x 2 x 3 x ... x (n-1) x n = (n-1)! x n = fact(n-1) x n
所以,fact(n)可以表示为n x fact(n-1),只有n=1时需要特殊处理。
于是,fact(n)用递归的方式写出来就是:
def fact(n): if n==1: return 1 return n * fact(n - 1)
上面就是一个递归函数。可以试试:
>>> fact(1) 1 >>> fact(5) 120 >>> fact(100) 93326215443944152681699238856266700490715968264381621468592963895217599993229915608941463976156518286253697920827223758251185210916864000000000000000000000000
如果我们计算fact(5),可以根据函数定义看到计算过程如下:
===> fact(5) ===> 5 * fact(4) ===> 5 * (4 * fact(3)) ===> 5 * (4 * (3 * fact(2))) ===> 5 * (4 * (3 * (2 * fact(1)))) ===> 5 * (4 * (3 * (2 * 1))) ===> 5 * (4 * (3 * 2)) ===> 5 * (4 * 6) ===> 5 * 24 ===> 120
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。可以试试fact(1000):
>>> fact(1000) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 4, in fact ... File "<stdin>", line 4, in fact RuntimeError: maximum recursion depth exceeded in comparison
解决递归调用栈溢出的方法是通过尾递归优化,事实上尾递归和循环的效果是一样的,所以,把循环看成是一种特殊的尾递归函数也是可以的。
尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
上面的fact(n)函数由于return n * fact(n - 1)引入了乘法表达式,所以就不是尾递归了。要改成尾递归方式,需要多一点代码,主要是要把每一步的乘积传入到递归函数中:
def fact(n): return fact_iter(n, 1) def fact_iter(num, product): if num == 1: return product return fact_iter(num - 1, num * product)
可以看到,return fact_iter(num - 1, num * product)仅返回递归函数本身,num - 1和num * product在函数调用前就会被计算,不影响函数调用。
fact(5)对应的fact_iter(5, 1)的调用如下:
===> fact_iter(5, 1) ===> fact_iter(4, 5) ===> fact_iter(3, 20) ===> fact_iter(2, 60) ===> fact_iter(1, 120) ===> 120
尾递归调用时,如果做了优化,栈不会增长,因此,无论多少次调用也不会导致栈溢出。
遗憾的是,大多数编程语言没有针对尾递归做优化,Python解释器也没有做优化,所以,即使把上面的fact(n)函数改成尾递归方式,也会导致栈溢出。
小结
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。
Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号