大三学习进度21
使用anaconda安装jieba十分方便
jieba是python的一个中文分词库,下面介绍它的使用方法。
安装
方式1:
pip install jieba
方式2:
先下载 http://pypi.python.org/pypi/jieba/
然后解压,运行 python setup.py install功能
下面介绍下jieba的主要功能,具体信息可参考github文档:https://github.com/fxsjy/jieba
分词
jieba常用的三种模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
可使用 jieba.cut 和 jieba.cut_for_search 方法进行分词,两者所返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语(unicode),或者直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回 list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用该方法可以自定义分词器,可以同时使用不同的词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
jieba.cut 和 jieba.lcut 可接受的参数如下:
- 需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
- cut_all:是否使用全模式,默认值为
False - HMM:用来控制是否使用 HMM 模型,默认值为
True
jieba.cut_for_search 和 jieba.lcut_for_search 接受 2 个参数:
- 需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
- HMM:用来控制是否使用 HMM 模型,默认值为
True
需要注意的是,尽量不要使用 GBK 字符串,可能无法预料地错误解码成 UTF-8。
三种分词模式的比较:
# 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']自定义词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。
用法: jieba.load_userdict(dict_path)
dict_path:为自定义词典文件的路径
词典格式如下:
一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
下面使用一个例子说明一下:
自定义字典 user_dict.txt:
大学课程
深度学习下面比较下精确匹配、全匹配和使用自定义词典的区别:
import jieba
test_sent = """
数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度',
# '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度',
# '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
jieba.add_word("尤其是")
jieba.add_word("线性代数课程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']从上面的例子中可以看出,使用自定义词典与使用默认词典的区别。
jieba.add_word():向自定义字典中添加词语
关键词提取
可以基于 TF-IDF 算法进行关键词提取,也可以基于extRank 算法。 TF-IDF 算法与 elasticsearch 中使用的算法是一样的。
使用 jieba.analyse.extract_tags() 函数进行关键词提取,其参数如下:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法的关键词抽取:
import jieba.analyse
file = "sanguo.txt"
topK = 12
content = open(file, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK)
print(tags)
# ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军']
# withWeight=True:将权重值一起返回
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True)
print(tags)
# [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849),
# ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185),
# ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038),
# ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]上面的代码是读取文件,提取出现频率最高的前12个词。
TF-IDF的原理如下:
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数)。
逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
关键词提取所使用逆向文件频率(IDF)文本语料库,当提取的结果不是我们想要的结果时,我们可以自定义IDF文本语料库。
词性标注
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
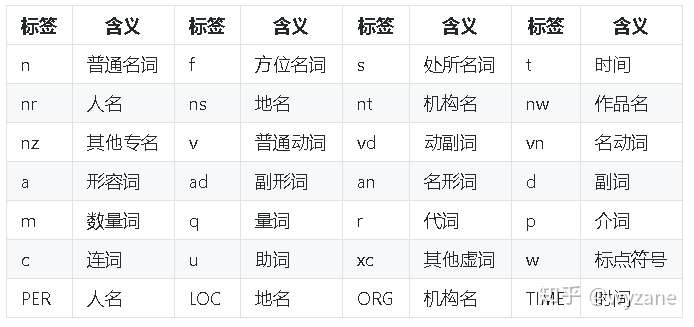
获取词语位置
将分本分词后,返回每个词和该词在原文中的起始位置,例子如下:
import jieba
result = jieba.tokenize('今天哪里都没去,在家里睡了一天')
for tk in result:
print("word:" + tk[0] +
" start:" + str(tk[1]) +
" end:" + str(tk[2]))
"""
word:华为技术有限公司 start:0 end:8
word:的 start:8 end:9
word:手机 start:9 end:11
word:品牌 start:11 end:13
"""
# 使用 search 模式
result = jieba.tokenize('华为技术有限公司的手机品牌', mode="search")
for tk in result:
print("word:" + tk[0] +
" start:" + str(tk[1]) +
" end:" + str(tk[2]))
"""
输出:
word:华为 start:0 end:2
word:技术 start:2 end:4
word:有限 start:4 end:6
word:公司 start:6 end:8
word:华为技术有限公司 start:0 end:8
word:的 start:8 end:9
word:手机 start:9 end:11
word:品牌 start:11 end:13
"""收索引擎
使用 jieba 和 whoosh 可以实现搜索引擎功能。
whoosh 是由python实现的一款全文搜索工具包,可以使用 pip 安装它:
pip install whoosh介绍 jieba + whoosh 实现搜索之前,你可以先看下文 whoosh 的简单介绍。
下面看一个简单的搜索引擎的例子:
import os
import shutil
from whoosh.fields import *
from whoosh.index import create_in
from whoosh.qparser import QueryParser
from jieba.analyse import ChineseAnalyzer
analyzer = ChineseAnalyzer()
schema = Schema(title=TEXT(stored=True),
path=ID(stored=True),
content=TEXT(stored=True,
analyzer=analyzer))
if not os.path.exists("test"):
os.mkdir("test")
else:
# 递归删除目录
shutil.rmtree("test")
os.mkdir("test")
idx = create_in("test", schema)
writer = idx.writer()
writer.add_document(
title=u"document1",
path="/tmp1",
content=u"Tracy McGrady is a famous basketball player, the elegant basketball style of him attract me")
writer.add_document(
title=u"document2",
path="/tmp2",
content=u"Kobe Bryant is a famous basketball player too , the tenacious spirit of him also attract me")
writer.add_document(
title=u"document3",
path="/tmp3",
content=u"LeBron James is the player i do not like")
writer.commit()
searcher = idx.searcher()
parser = QueryParser("content", schema=idx.schema)
for keyword in ("basketball", "elegant"):
print("searched keyword ",keyword)
query= parser.parse(keyword)
results = searcher.search(query)
for hit in results:
print(hit.highlights("content"))
print("="*50)上面代码中,使用 add_document() 把一个文档添加到了 index 中。在这些文档中,搜索含有 “basketball”和 “elegant” 的文档。
打印结果如下:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\wyzane\AppData\Local\Temp\jieba.cache
Loading model cost 0.754 seconds.
Prefix dict has been built successfully.
searched keyword basketball
McGrady is a famous <b class="match term0">basketball</b> player, the elegant...<b class="match term0">basketball</b> style of him attract me
Bryant is a famous <b class="match term0">basketball</b> player too , the tenacious
==================================================
searched keyword elegant
basketball player, the <b class="match term0">elegant</b> basketball style
==================================================更换搜索词时:
for keyword in ("LeBron", "Kobe"):
print("searched keyword ",keyword)
query= parser.parse(keyword)
results = searcher.search(query)
for hit in results:
print(hit.highlights("content"))
print("="*50)搜索结果如下:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\wyzane\AppData\Local\Temp\jieba.cache
Loading model cost 0.801 seconds.
Prefix dict has been built successfully.
searched keyword LeBron
<b class="match term0">LeBron</b> James is the player i do not like
==================================================
searched keyword Kobe
<b class="match term0">Kobe</b> Bryant is a famous basketball player too , the tenacious
==================================================上面是搜索英文,下面展示下搜索中文。
添加下面的文档数据:
writer.add_document(
title=u"document1",
path="/tmp1",
content=u"麦迪是一位著名的篮球运动员,他飘逸的打法深深吸引着我")
writer.add_document(
title=u"document2",
path="/tmp2",
content=u"科比是一位著名的篮球运动员,他坚韧的精神深深的感染着我")
writer.add_document(
title=u"document3",
path="/tmp3",
content=u"詹姆斯是我不喜欢的运动员")执行搜索:
for keyword in ("篮球", "麦迪"):
print("searched keyword ",keyword)
query= parser.parse(keyword)
results = searcher.search(query)
for hit in results:
print(hit.highlights("content"))
print("="*50)结果如下:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\wyzane\AppData\Local\Temp\jieba.cache
Loading model cost 0.780 seconds.
Prefix dict has been built successfully.
searched keyword 篮球
麦迪是一位著名的<b class="match term0">篮球</b>运动员,他飘逸的打法深深吸引着我
科比是一位著名的<b class="match term0">篮球</b>运动员,他坚韧的精神深深的感染着我
==================================================
searched keyword 麦迪
<b class="match term0">麦迪</b>是一位著名的篮球运动员,他飘逸的打法深深吸引着我
==================================================上面就简单介绍了 jieba + whoosh 实现搜索引擎的例子。其实要实现上面的搜索功能,在 elasticsearch 中可以更加简单,有兴趣的同学可以了解一下。
whoosh
下面介绍下 whoosh 的使用。
whoosh 官方文档为:https://whoosh.readthedocs.io/en/latest/
使用 whoosh 之前,需要先定义 index 对象,同时创建 schema对象 与 index 对应。schema中包含一列字段,这些字段存放在 index 中。每个字段都是文档中的一部分信息,例如标题和文本内容。字段能被搜索或者存储。
定义一个 schema,由两个字段:
from whoosh.fields import Schema, STORED, ID, KEYWORD, TEXT
schema = Schema(title=TEXT(stored=True), content=TEXT,
path=ID(stored=True), tags=KEYWORD,
icon=STORED)我们仅需要创建一次 schema,当创建索引时,schema 会被序列化并与 index 保存在一起。
当创建 schema 对象时,需要指定字段名和其对应的类型,在 whoosh.fields 下,由如下类型:
ID:该类型索引字段的整个值作为一个单位类索引,而不是拆分成多个词
TEXT:该类型适用于文本数据的正文,它为文本建立索引并存储术语位置以允许短语搜索
NUMERIC:数值类型,可以存储整数或者浮点数
BOOLEAN:Boolean类型
DATETIME:适用于 datetime 对象
KEYWORD:适用于空格或者标点分割的关键字,类型数据能被索引和搜索但是不支持短语搜索(为了节省空间)
STORED:与文档存储在一起而不是与索引,该类型的数据不能被索引和搜索schema对象创建完成后,可以使用 create_in 函数创建索引:
import os.path
from whoosh.index import create_in
from whoosh.fields import Schema, STORED, ID, KEYWORD, TEXT
schema = Schema(title=TEXT(stored=True), content=TEXT,
path=ID(stored=True), tags=KEYWORD,
icon=STORED)
if not os.path.exists("index"):
os.mkdir("index")
ix = create_in("index", schema)创建 index 时,会创建一个存储对象来保存 index 信息。
通常,存储对象都会是 FileStorage,一种使用文件来存储索引的存储介质。
创建索引后,也可以通过 open_dir() 来打开索引:
from whoosh.index import open_dir
ix = open_dir("index")创建好 index 对象后,我们可以往里面添加文档。writer() 方法会返回一个 IndexWriter 对象,使用它可以向 index 中添加文档:
writer = ix.writer()
writer.add_document(title=u"My document", content=u"This is my document!",
path=u"/a", tags=u"first short", icon=u"/icons/star.png")
writer.add_document(title=u"Second try", content=u"This is the second example.",
path=u"/b", tags=u"second short", icon=u"/icons/sheep.png")
writer.add_document(title=u"Third time's the charm", content=u"Examples are many.",
path=u"/c", tags=u"short", icon=u"/icons/book.png")
writer.commit() # 保存文档到索引中添加文档时,没有必要对所有字段都添加值;能被索引的 TEXT 字段必须要传入一个 unicode 类型的值,仅仅被存储而不用来索引的字段可以传入任何可被序列化的对象。
文档存储到 index 后,就可以进行索引了,索引之前首先要创建一个 search 对象:
searcher = ix.searcher()可以使用 with 语句,以便使 search 对象自动关闭,也可以使用 try … finally:
with ix.searcher() as searcher:
...
try:
searcher = ix.searcher()
...
finally:
searcher.close()search 对象的 search() 方法需要传入一个 Query 对象。可以直接钩爪一个 Query 对象,也可以使用QueryParse构造一个 Query 对象。将 Query 对象传入 search() 方法中,可以得到一个 Results 对象。
from whoosh.query import *
myquery = And([Term("content", u"apple"), Term("content", "bear")])
# 或者使用
from whoosh.qparser import QueryParser
parser = QueryParser("content", ix.schema)
myquery = parser.parse(querystring)
results = searcher.search(myquery)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号