
深入理解TCP协议及其源代码——网络程序设计课第五次作业
本次实验,我们以tcp的三次握手为例,跟踪并分析tcp协议中相关内核处理函数从而加深对tcp协议三次握手这项机制的理解。
环境:linux-5.0.1内核 ,32位系统的MenuOS
首先,弄清楚三次握手的具体流程:

1.client端发起主动连接,向服务器端发送一个SYN被置1的报文表示请求连接
2.server端收到后向client发送ACK和SYN均置为1的数据包,表示收到请求并同意建立连接
3.client收到后向server端发送ACK置为1的数据包,表示接收到了该数据包。自此,三次握手完毕,连接建立成功。
一、自顶向下逐级追踪
通过上次的socket实验,我们已经搞清楚在replyhi(server端)和hello(client端)建立通讯这一过程中(从socket的创建后到tcp连接的建立)分别按序涉及到以下的linux socket api的调用:
server端:bind、listen、accept
client端:connect
将以上的api置于三次握手的时序图中:

按照先启动server再启动client的顺序,在我们启动server端并完成server socket的建立后,按序执行了bind和listen,他们分别完成了将socket绑定到某一端口和设置此socket能够处理的请求排队的最大长度的工作。
完成上述操作后执行accept,它会一致阻塞直到有客户端的socket发起连接。
启动client后,同样在先完成socket的建立后我们执行了connect这个阻塞函数,它发起和server的主动连接,连接成功后返回。
也就是说,三次握手的具体过程发生在accept和connect之间。
对于这一结论,我们可以研究bind、listen、accept和connect等api涉及到的内核处理函数的细节来验证(即看看这些内核处理函数是否调用了数据包发送的相关的底层函数),也可以用相关的抓包软件来验证——
我们分别把断点打在这些函数调用处,看看运行它们后是否引起了三次握手中相关数据包的发送就能达到我们的目的,本来计划用gdb直接调试内核,发现wireshark抓不到qemu产生的数据包,因此我们在用户态下用gdb
调试tcp通信的程序(不影响对结论的验证)。
在用户态下,为了能捕捉到断点,我们自己再写四个函数,break_bind, break_listen, break_accept和break_connect。这四个函数什么都不做,只是起到gdb能捕捉到这个断点的作用。然后分别在对应的linux socket api
调用之前调用它们,如:

其他三个函数也是在类似的对应位置调用。编译完成后,用gdb在这四处打上断点并跟踪,同时运行wireshark:
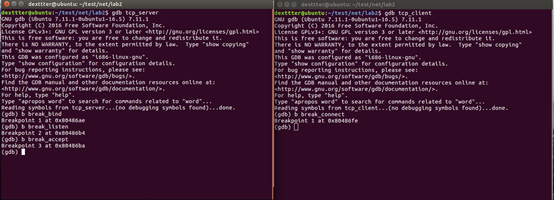 、
、
当我们运行server直到断点break_accept处时(此时,bind和listen已经执行完毕,accept尚未执行),如下图所示:

并未抓取到任何三次握手的数据包
继续执行到accept,server端处于continue状态,陷入阻塞。此时开始运行client:
在connect运行前也是没有产生三次握手的数据包:
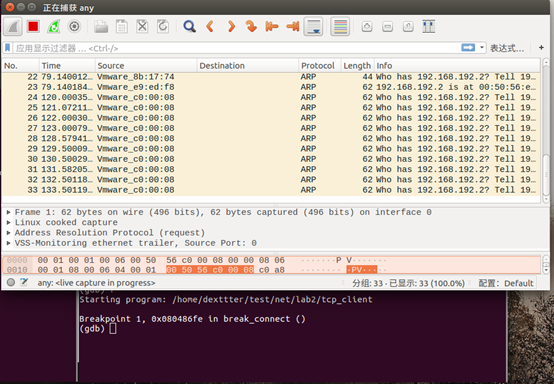
直到我们运行完成connect:


三次握手的数据包已经产生。且此时server端显示:

accept client 127.0.0.1。完全与我们前面所说的三次握手的具体过程发生在accept和connect之间,且accept会在connect完成后返回这一描述一致。
知道了这一点后,我们分析三次握手的流程就能聚焦到connect和accept这两个函数之中。从上次的实验我们已经知道accept和connect最终调用了__sys_accept4和__sys_connect这两个内核处理函数,检查其源码我们发现,
这俩函数核心是通过sock->opt->connect和sock->opt->accept这两个函数指针调用了某个函数。
其中sock是struct socket类型的,为了追踪下去我们还得找到struct socket这个结构体的定义。
这里,顺便一提,为了找linux内核代码中的某个结构体的定义我们可以在源码根目录下的include目录(所有的系统预定义的结构体都在内核源代码的/include下有定义)中使用正则表达式搜寻,如:find -name "*.h" | xargs grep "struct socket {" -rn
struct socket的定义在include/net.h中
struct socket {
socket_state state;
short type;
unsigned long flags;
struct socket_wq *wq;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};
从上面的定义我们知道了,ops是struct proro_ops类型,接着找。
同样在include/net.h中:
struct proto_ops {
int family;
struct module *owner;
int (*release) (struct socket *sock);
int (*bind) (struct socket *sock,
struct sockaddr *myaddr,
int sockaddr_len);
int (*connect) (struct socket *sock,
struct sockaddr *vaddr,
int sockaddr_len, int flags);
int (*socketpair)(struct socket *sock1,
struct socket *sock2);
int (*accept) (struct socket *sock,
struct socket *newsock, int flags, bool kern);
int (*getname) (struct socket *sock,
struct sockaddr *addr,
int peer);
__poll_t (*poll) (struct file *file, struct socket *sock,
struct poll_table_struct *wait);
int (*ioctl) (struct socket *sock, unsigned int cmd,
unsigned long arg);
#ifdef CONFIG_COMPAT
int (*compat_ioctl) (struct socket *sock, unsigned int cmd,
unsigned long arg);
#endif
int (*listen) (struct socket *sock, int len);
int (*shutdown) (struct socket *sock, int flags);
int (*setsockopt)(struct socket *sock, int level,
int optname, char __user *optval, unsigned int optlen);
int (*getsockopt)(struct socket *sock, int level,
int optname, char __user *optval, int __user *optlen);
#ifdef CONFIG_COMPAT
int (*compat_setsockopt)(struct socket *sock, int level,
int optname, char __user *optval, unsigned int optlen);
int (*compat_getsockopt)(struct socket *sock, int level,
int optname, char __user *optval, int __user *optlen);
#endif
int (*sendmsg) (struct socket *sock, struct msghdr *m,
size_t total_len);
int (*recvmsg) (struct socket *sock, struct msghdr *m,
size_t total_len, int flags);
int (*mmap) (struct file *file, struct socket *sock,
struct vm_area_struct * vma);
ssize_t (*sendpage) (struct socket *sock, struct page *page,
int offset, size_t size, int flags);
ssize_t (*splice_read)(struct socket *sock, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len, unsigned int flags);
int (*set_peek_off)(struct sock *sk, int val);
int (*peek_len)(struct socket *sock);
int (*read_sock)(struct sock *sk, read_descriptor_t *desc,
sk_read_actor_t recv_actor);
int (*sendpage_locked)(struct sock *sk, struct page *page,
int offset, size_t size, int flags);
int (*sendmsg_locked)(struct sock *sk, struct msghdr *msg,
size_t size);
int (*set_rcvlowat)(struct sock *sk, int val);
};
根据以上代码:accept和connect都是函数指针,我们还得知道这个结构体是在哪里始化的,初始化的过程中给accept和connect指针分别绑定到了哪个函数上去。
原来struct proto tcp_prot的初始化设定了TCP协议栈的访问接口函数,socket接口层里sock->opt->connect和sock->opt->accept对应的接口函数即是在这里制定:
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.unhash = inet_unhash,
.get_port = inet_csk_get_port,
.enter_memory_pressure = tcp_enter_memory_pressure,
.leave_memory_pressure = tcp_leave_memory_pressure,
.stream_memory_free = tcp_stream_memory_free,
.sockets_allocated = &tcp_sockets_allocated,
.orphan_count = &tcp_orphan_count,
.memory_allocated = &tcp_memory_allocated,
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem),
.max_header = MAX_TCP_HEADER,
.obj_size = sizeof(struct tcp_sock),
.slab_flags = SLAB_TYPESAFE_BY_RCU,
.twsk_prot = &tcp_timewait_sock_ops,
.rsk_prot = &tcp_request_sock_ops,
.h.hashinfo = &tcp_hashinfo,
.no_autobind = true,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_tcp_setsockopt,
.compat_getsockopt = compat_tcp_getsockopt,
#endif
.diag_destroy = tcp_abort,
};
代码中标黄的部分已经告诉我们的sock->opt->connect指针绑定到了 tcp_v4_connect函数,sock->opt->accept指针绑定到了inet_csk_accept函数。
OK,有了这个认识后,接下来我们就依次来查看tcp_v4_connect和inet_csk_accept。
1.tcp_v4_connect:
根据老师ppt所指出的,tcp_v4_connect函数的主要作用就是发起一个TCP连接,生一个包含SYN标志和一个32位的序号的连接请求包,并发送给服务器端,这是TCP三次握手的第一步。
tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(tcp_death_row, sk); if (err) goto failure; sk_set_txhash(sk); rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL; goto failure;
并通过:
tcp_set_state(sk, TCP_SYN_SENT)把套接字的状态从CLOSE切换到SYN_SENT,并进一步调用了 tcp_connect(sk)来实际构造SYN并发送出去。然后调用inet_hash_connect(&tcp_death_row, sk)和
ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk),为套接字绑定一个端口,并记录在TCP的哈希表中。
总的来说,整个过程的函数调用关系是这样的:
tcp_v4_connect -> tcp_connect_init -> tcp_transmit_skb -> icsk->icsk_af_ops->send_check (tcp_v4_send_check)-> icsk->icsk_af_ops->queue_xmit (ip_queue_xmit)-> inet_csk_reset_xmit_timer
2.inet_csk_accept:
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
lock_sock(sk);
/* We need to make sure that this socket is listening,
* and that it has something pending.
*/
error = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don't sleep */
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
if (sk->sk_protocol == IPPROTO_TCP &&
tcp_rsk(req)->tfo_listener) {
spin_lock_bh(&queue->fastopenq.lock);
if (tcp_rsk(req)->tfo_listener) {
/* We are still waiting for the final ACK from 3WHS
* so can't free req now. Instead, we set req->sk to
* NULL to signify that the child socket is taken
* so reqsk_fastopen_remove() will free the req
* when 3WHS finishes (or is aborted).
*/
req->sk = NULL;
req = NULL;
}
spin_unlock_bh(&queue->fastopenq.lock);
}
out:
release_sock(sk);
if (req)
reqsk_put(req);
return newsk;
out_err:
newsk = NULL;
req = NULL;
*err = error;
goto out;
}
在上面的代码中,我们重点关注这一部分:
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don't sleep */
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
一个分支语句:当reqsk_queue不空时我们调用reqsk_queue_remove函数从队列中取出某个连接请求。而当reqsk_queue为空时,我们调用了inet_csk_wait_for_connect,来看看这个函数的实现(在net/ipv4/inet_connection_sock.c中):
inet_csk_wait_for_connect:
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
release_sock(sk);
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
sched_annotate_sleep();
lock_sock(sk);
err = 0;
if (!reqsk_queue_empty(&icsk->icsk_accept_queue))
break;
err = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
break;
err = sock_intr_errno(timeo);
if (signal_pending(current))
break;
err = -EAGAIN;
if (!timeo)
break;
}
finish_wait(sk_sleep(sk), &wait);
return err;
}
原来核心是一个for(;;)的死循环,难怪我们说accept是阻塞的,原因在这里。只有当一个连接请求发过来时才会跳出循环。也就是说:

整个过程大概是这个样子:client通过conncet调用tcp协议中的tcp_v4_connect函数,server通过accept调用inet_csk_wait_for_connect函数来监听连接请求的队列,一旦有请求发来就跳出循环,否则一直阻塞。这其中,
tcp协议栈负责写入队列,而inet_csk_wait_for_connec负责监听队列并将请求从队列中读出。也就是说当协议栈往队列中写入请求,accept读出请求的时候就是三次握手的完成之时。那么协议栈是怎么写入的呢?
二、自底向上分析tcp的接收过程
以上都是我们按照函数调用的一层层关系自顶向下了解到的三次握手的流程。反过来,自底向上的,底层所抓到或产生的数据是如何通知上层的?也就是上面所提出的问题协议栈是怎么写入的呢?是tcp_v4_rcv,ip层在收到数据后就会通过函数指针回调tcp_v4_rcv函数。
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
上面初始化的过程中,函数指针handler绑定到了tcp_v4_rcv。tcp_v4_rcv函数为TCP的总入口,数据包从IP层传递上来,进入该函数(也就是说它是自底向上进入tcp的入口)。而入口函数tcp_v4_rcv又做了什么,查询有关资料后,我找到了这张流程图,
它大概地梳理了这一过程:
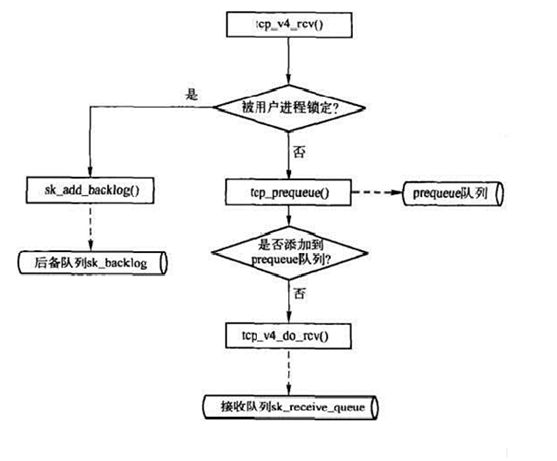
具体的过程,下面这篇博客已经讲的很完善了:
https://blog.csdn.net/xiaoyu_750516366/article/details/85539495
简而言之,tcp从ip接收数据的过程总共维护了prequeue、receive以及backlog这三个队列。由于协议栈对输入数据包的处理实际上都是中断中进行的,出于性能的考虑,我们总是期望中断能够快速的结束
当我们调用tcp_v4_rcv时首先会检查传输控制块TCB,如果它被用户进程锁定,就将数据包放入到backlog队列中,这类数据包的真正处理是在用户进程释放TCB时进行的;如果TCB没有被进程锁定,那么首先尝试将数据包放入prequeue队列,这类数据包的处理是在用户进程读数据过程中处理的;如果没有被进程锁定,prequeue队列也没有接受该数据包(出于性能考虑,比如prequeue队列不能无限制增大),那么必须在中断中对数据包进行处理,处理完毕后将数据包加入到receive队列中。放入receive队列的数据包都是已经被TCP处理过的数据包,比如校验、回ACK等动作都已经完成了,这些数据包等待用户空间程序读即可;相反,放入backlog队列和prequeue队列的数据包都还需要TCP处理,实际上,这些数据包也都是在合适的时机通过tcp_v4_do_rcv()处理的。
明白了从ip层往上到tcp层的入口函数是tcp_v4_rcv之后,我们再来看看三次握手中每一次的tcp_v4_rcv之中的函数调用关系是怎样的。
先给出结论:
1.客户端发送SYN
tcp_v4_connect() -> tcp_connect() -> tcp_transmit_skb() -> ip_queue_xmit()
2.服务器端接收SYN,并返回SYN和ACK
tcp_v4_rcv() -> tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_rcv_synsent_state_process() -> tcp_send_ack()
3.客户端发送ACK
tcp_send_ack() -> tcp_transmit_skb() -> ip_queue_xmit()
涉及到的内容很多,钻研代码的细节的话很费功夫,因此我们只关注了个别函数,窥见其一斑 。
1.tcp_rcv_state_process
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { ... switch (sk->sk_state) { case TCP_CLOSE:
... goto discard; case TCP_LISTEN: ...goto discard; case TCP_SYN_SENT: ...return 0; } ...switch (sk->sk_state) { case TCP_SYN_RECV: ... tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); break; case TCP_FIN_WAIT1: {
... } case TCP_CLOSING: ...break; case TCP_LAST_ACK: ... } break; } tcp_urg(sk, skb, th); switch (sk->sk_state) { case TCP_CLOSE_WAIT: case TCP_CLOSING: case TCP_LAST_ACK: if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) break; case TCP_FIN_WAIT1: case TCP_FIN_WAIT2: case TCP_ESTABLISHED: tcp_data_queue(sk, skb); queued = 1; break; } if (sk->sk_state != TCP_CLOSE) { tcp_data_snd_check(sk); tcp_ack_snd_check(sk); } if (!queued) { discard: tcp_drop(sk, skb); } return 0; }
以上是tcp_rcv_state_process这个函数删减了一部分后的内容,我们看到,这里头通过几个switch语句块包含了所有的socket的状态:
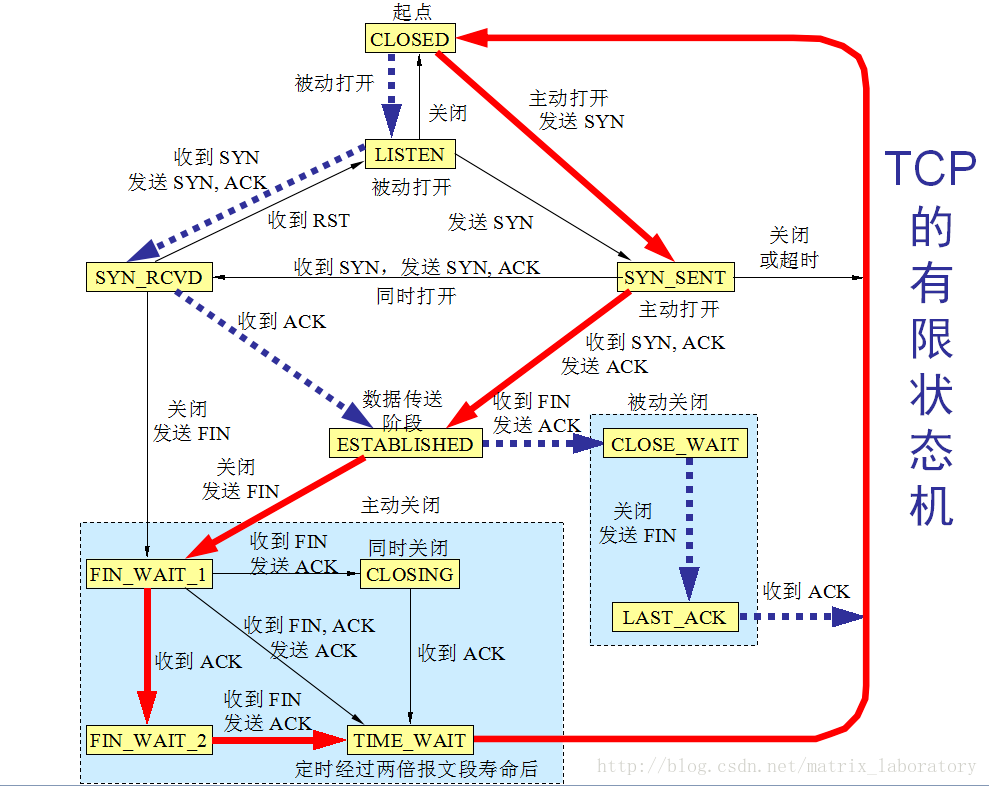
也就是说这个函数实通过switch语句使得各个状态的socket找到对应的分支从而进行不同的操作转换到不同的状态,也即它是实现tcp自动机的入口函数。
2.tcp_transmit_skb
tcp_transmit_skb的作用是复制或者拷贝skb,构造skb中的tcp首部,并将调用网络层的发送函数发送skb;在发送前,首先需要克隆或者复制skb,因为在成功发送到网络设备之后,skb会释放,而tcp层不能真正的释放,是需要等到对该数据段的ack才可以释放;然后构造tcp首部和选项;最后调用网络层提供的发送回调函数发送skb,ip层的回调函数为ip_queue_xmit;
参考自:https://www.cnblogs.com/wanpengcoder/p/11755347.html
总结:第一部分我们自顶向下地追踪和通过抓包分析,明白了三次握手的过程发生在accept和connect之间。再通过第二部分自底向上研究了从ip层进入tcp,也即tcp接收处理的过程。


