Bash-正则表达式
一.正则表达式与通配符
通配符:用来匹配符合条件的文件名(完全匹配),ls、find、cp这些命令不支持正则表达式,所以只能用通配符
正则表达式:用来匹配符合条件的字符串(包含匹配),grep、awk、sed等命令支持正则表达式
常用通配符:*(任意字符重复任意多次)、?、[]
二.基础正则表达式
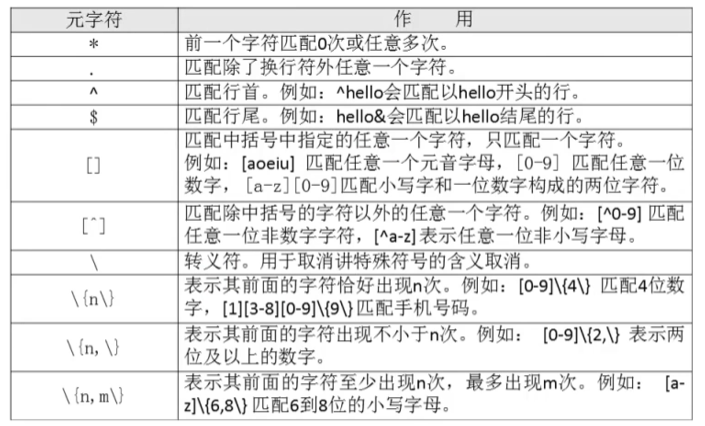
* (匹配前一个字符0或任意多次)例子
- grep "a*" xxx.txt #匹配xxx文件中所有内容,包括空白行(没有任何意义)
- grep "aa*" xxx.txt #匹配xxx文件中至少包含一个a的行
- grep "aaa*" xxx.txt #匹配xxx文件中至少包含有两个连续a的行
- grep "aaaaa" xxx.txt #匹配xxx文件中至少包含有4个连续a的行
.(匹配除了换行符外任意一个字符)例子
- grep "s..d" xxx.txt #"s..d"会匹配在s和d这两个字母之间一定有两个字符的单词
- grep "s.*d" xxx.txt #匹配在s和d字母之间有任意字符
- grep ".*" xxx.txt #匹配所有内容
^(匹配行首)$(匹配行尾)例子
- grep "^M" xxx.txt #匹配以大写"M"开头的行
- grep "n$" xxx.txt #匹配以小写"n"结尾的行
- grep -n "^$" xxx.txt #匹配空白行
[ ](匹配括号中指定任意一个字符,只匹配一个字符)
- grep "s[ao]id" xxx.txt #匹配s和i字母中,要不是a就是o
- grep "[0-9]" xxx.txt #匹配任意一个数字
- grep "^[a-z]" xxx.txt #匹配用小写字母开头的行
[^](匹配除中括号的字符以外的任意一个字符)
- grep "^[^a-z]" xxx.txt #匹配不用小写字母开头的行
- grep "^[^a-zA-Z]" xxx.txt #匹配不用字母开头的行
\(转义符)
- grep "\.$" xxx.txt #匹配使用"."结尾的行
\{n\}(表示其前面的字符恰好出现n次)
- grep "a\{3\}" xxx,txt #匹配a字母连续出现三次的字符串
- grep "[0-9]\{3\}" xxx.txt #匹配包含连续的三个数字的字符串
\{n,m\}(匹配其前面的字符至少出现n次,最多出现m次)
- grep "sa\{1,3\}i" xxx.txt #匹配字母s和字母i之间,出现1-3个字符a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号