import jieba
f=open('hlm.txt','r')
text=f.read()
notelist=list(jieba.lcut(text))
textdic={}
for i in set(notelist): #计算次数
textdic[i]=notelist.count(i)
delete={'。',' ','他',';', '的', '说', '道', '你','了',',','.',':','也','是','\n','”','“','"','我','又','\u3000','?',
'去','都','来','有','这','人','他们','不','我们','在','着','你们','便','就','还','们','那',}
for i in delete: #删除非法词汇
if i in textdic:
del textdic[i]
word = sorted(textdic.items(), key= lambda d:d[1], reverse = True) # 由大到小排序
for i in range(10): #输出词频Top10
print(word[i])
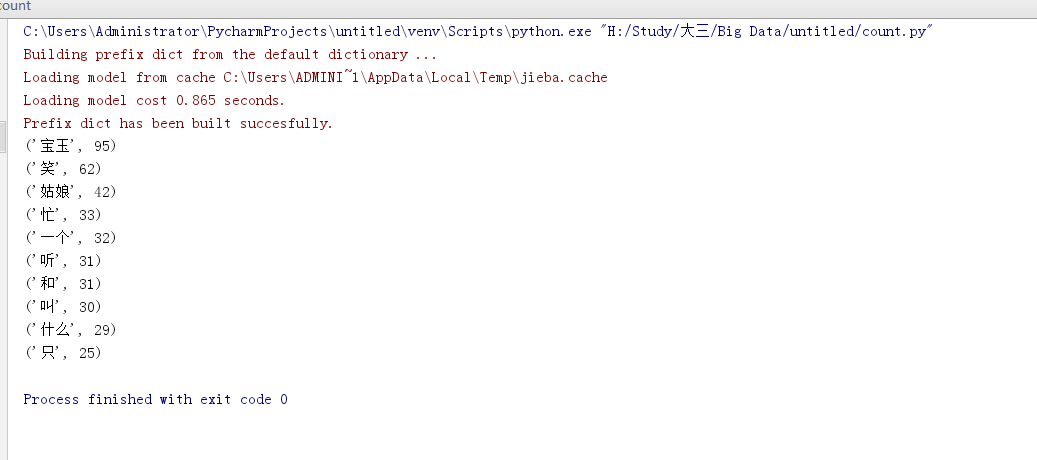
问题:使用长篇小说时候会报错,下面是使用小说部分内容进行的中文词频查询。
运行截图如下:
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号