
一、源代码


import requests import queue import pymysql from lxml import etree import threading import re import useful_functions import fake_user_agent # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36' # } # 代理池 headers = fake_user_agent.useragent_random() # 爬取线程 class MyThread(threading.Thread): def __init__(self, url_queue): super(MyThread, self).__init__() self.url_queue = url_queue self.urls = [] # 连接Mysql数据库 self.cnn = pymysql.connect(host='127.0.0.1', user='root', password='20000604', port=3306, database='news_with_keyword', charset='utf8') self.cursor = self.cnn.cursor() self.sql = 'insert into guanchazhe(title, author, publish_time, content, url, key_word) values(%s, %s, %s, %s, %s, %s)' # 获取已爬取的url数据并写入列表,用于判断 sql = 'select url from guanchazhe' self.cursor.execute(sql) for url in self.cursor.fetchall(): self.urls.append(url[0]) def run(self): self.spider() def spider(self): while not self.url_queue.empty(): item = {} url = self.url_queue.get() if self.check_url(url): print('{url}已存在') response = requests.get(url, headers=headers) response.encoding = "utf-8" html = etree.HTML(response.text) results = html.xpath('//ul/li[contains(@class,"left left-main")]') for result in results: item['url'] = url author = result.xpath('./ul/li/div[contains(@class,author-intro)]/p/a/text()') if not author: author = html.xpath('//div[contains(@class,"time")]/span[3]/text()') if not author: self.get_news(response.text, item) continue item['author'] = author[0] item['title'] = result.xpath('./h3/text()')[0] item['publish_time'] = result.xpath('./div[contains(@class,"time")]/span[1]/text()')[0] content = result.xpath('./div[contains(@class,"content")]/p/text()') content = ''.join(content) content = re.sub('\s', '', content) item['content'] = content key_word = result.xpath("//div[@class='key-word fix mt15']/a/text()") key_word = ",".join(key_word) if not key_word: key_word = useful_functions.get_keyword_from_content(content) item['key_word'] = key_word print(key_word) self.save(item) def save(self, item): self.cursor.execute(self.sql,[item['title'], item['author'], item['publish_time'],item['content'], item['url'],item['key_word']]) self.cnn.commit() def check_url(self, url): # 查看数据库中是否存在当前爬取的url,如果存在则放弃爬取 if url in self.urls: #print({url}+'已存在') return False else: self.urls.append(url) return True def get_news(self, text, item): # 获取js渲染后的网址并请求 str = re.search('window.location.href=".*?"', text).group() link = re.split('"', str)[1] + '&page=0' response = requests.get(url=link, headers=headers) response.encoding = "utf-8" html = etree.HTML(response.text) item['author'] = \ html.xpath('//div[contains(@class,"article-content")]/div[2]/div[@class="user-main"]/h4/a/text()')[0] item['title'] = html.xpath('//div[@class="article-content"]/h1/text()')[0] item['publish_time'] = html.xpath('//span[@class="time1"]/text()')[0] content = html.xpath('//div[@class="article-txt-content"]/p/text()') content = ''.join(content) content = re.sub('\s', '', content) item['content'] = content key_word = html.xpath("//div[@class='key-word fix mt15']/a/text()") key_word = ",".join(key_word) if not key_word: key_word = useful_functions.get_keyword_from_content(content) if not key_word: key_word = '无关键词' else: key_word.append() key_word = ", ".join(key_word) item['key_word'] = key_word # 将获取到的url添加到队列中去 def add_urls(urls, queue): for url in urls: url = 'https://www.guancha.cn' + url queue.put(url) # 从观察者网首页网页中获取url def get_url(queue): url = 'https://www.guancha.cn/' response = requests.get(url, headers=headers).text html = etree.HTML(response) head_line = html.xpath("//div[(@class ='content-headline')]/a/@href") left_urls = html.xpath('//ul[contains(@class, "Review-item")]/li/a[contains(@class, "module-img")]/@href') center_right_urls = html.xpath('//ul[contains(@class, "img-List")]/li/h4[contains(@class, "module-title")]/a/@href') # right_urls = html.xpath('//ul[contains(@class, "fengwen-list")]/li/h4[contains(@class, "module-title")]/a/@href') add_urls(left_urls, queue) add_urls(center_right_urls, queue) add_urls(head_line,queue) # 从观察者网首页末尾的更多网页中获取url def get_urlFromMore(queue): for index in range(1,16): #url = 'https://www.guancha.cn/mainnews-yw/list_{'+index+'}.shtml' url = 'https://www.guancha.cn/mainnews-yw/list_' + str(index) + '.shtml' response = requests.get(url, headers=headers).text html = etree.HTML(response) more_urls = html.xpath("//div[@class = 'right fn']/h4/a/@href") add_urls(more_urls,queue) # 爬虫运行程序 def run(): threads = [] url_que = queue.Queue() get_urlFromMore(url_que) for i in range(10): thread = MyThread(url_que) threads.append(thread) thread.start() if __name__ == '__main__': run()
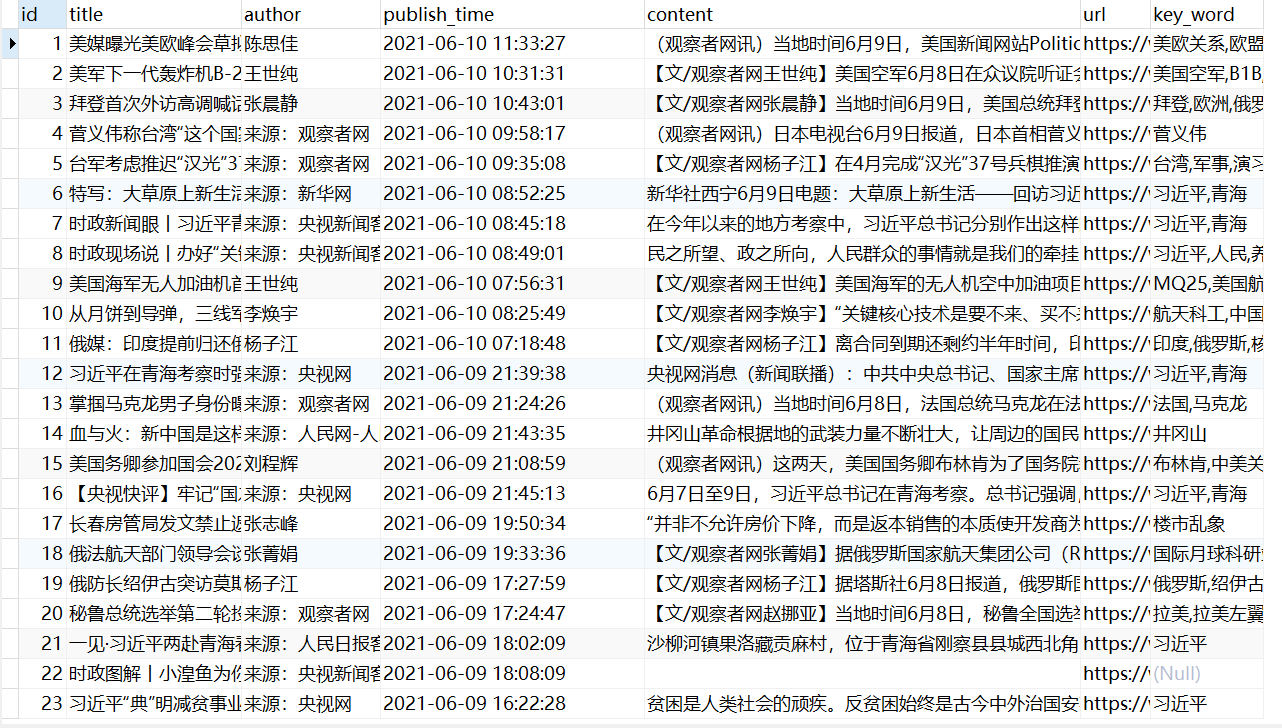
二、实验截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号