
学习视频
https://www.bilibili.com/video/BV1d441127uU?from=search&seid=528108915857989527
一、基础简介
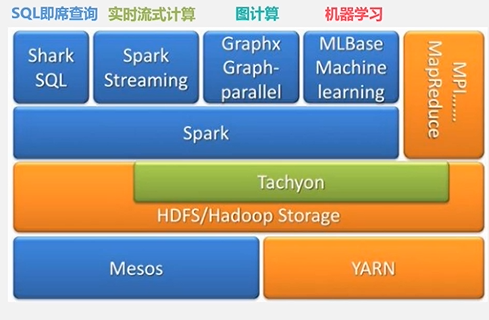
1.生态系统
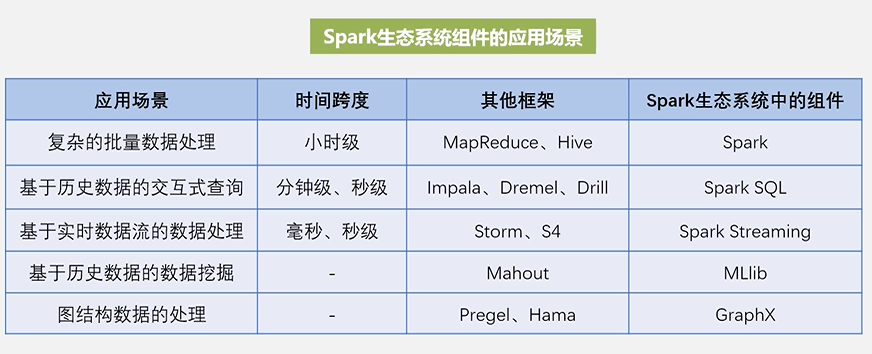
2.Spark生态系统组件的应用场景
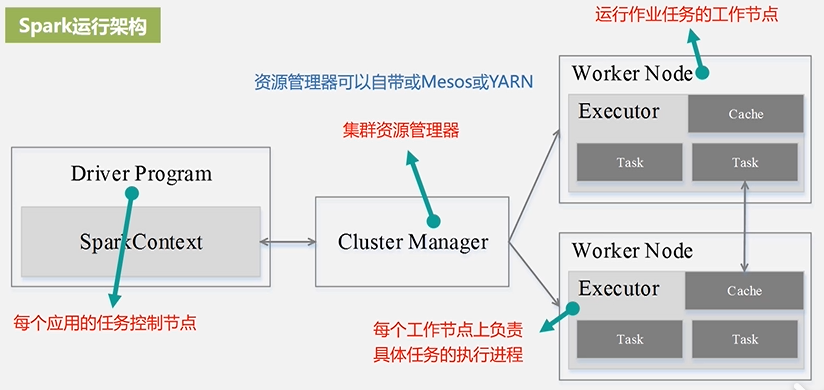
3.Spark运行架构
二、基本流程图和特点
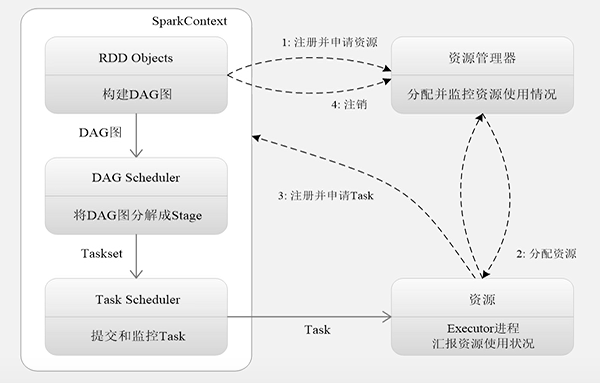
1.为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控。
2.资源管理器为Executor分配资源,并启动Executor进程
3.SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task Task Scheduler将Task发放给Executor运行并提供应用程序代码
4.Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源
特点:
1.每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task
2.Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可
3.Task采用了数据本地性和推测执行等优机化机制
三、Spark的安装、部署和应用
https://www.bilibili.com/video/av66134434?p=10
四、SparkRDD应用
1.完成转换的API(Transformation API)
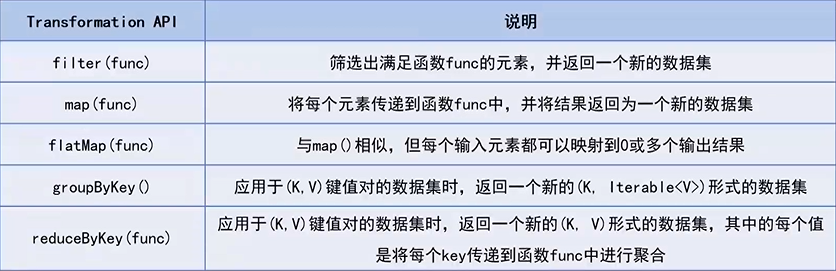
2.完成动作的API(Action API)
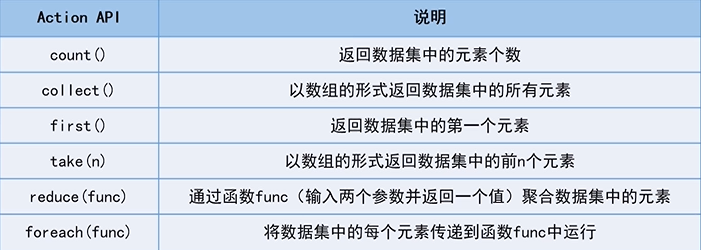
3.统计该文本文件的行数
![]()
过滤操作,筛选出只包含Spark的行

链式操作(简化代码,优化计算过程)

实现MapReduce的计算流程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号