
网络爬虫(网络蜘蛛)
相关学习资源:https://www.bilibili.com/video/BV12E411A7ZQ?p=16
一、爬虫的介绍
网络爬虫,是一种按照一定规律。自动获取互联网信息的程序或者脚本。根据用户需求定向抓取相关网页并分析。
二、爬虫的本质
模拟浏览器打开网页,获取网页中我们想要的那部分数据。
三、基本流程
1.准备工作:通过浏览器查看分析目标网页
2.获取数据:通过HTTP库向目标点发起请求,请求可以包含额外的header等信息,如果服务器能正常响应,会得到一个Response,便是所要获取的页面内容。
3.解析内容:得到的内容可能是HTML,json等格式,可以用页面解析库、正则表达式等进行解析
4.保存数据:可以存为文本,也可以保存到数据库,或者保存特定格式的文件

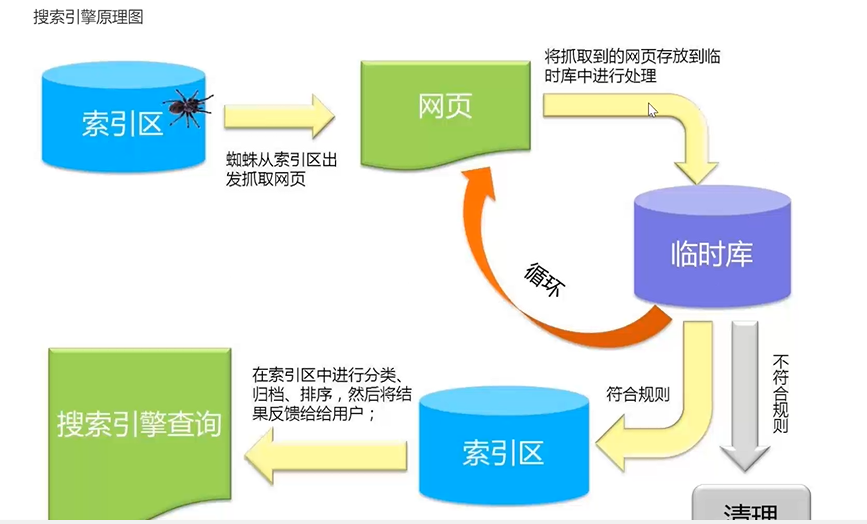
四、编写代码
1.代码规范:if__nam__="__main__"

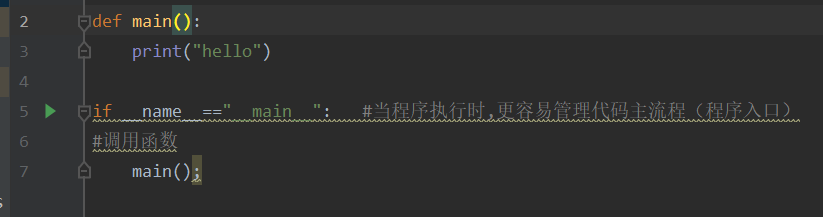
2.引入库
#引入自定义模块
#引入系统模块
#引入第三方模块

3.编写主流程(为了逻辑清晰,方便管理,将每一部分写成函数,然后在主函数中进行调用)
#爬取网页
#逐一解析网页
#保存数据
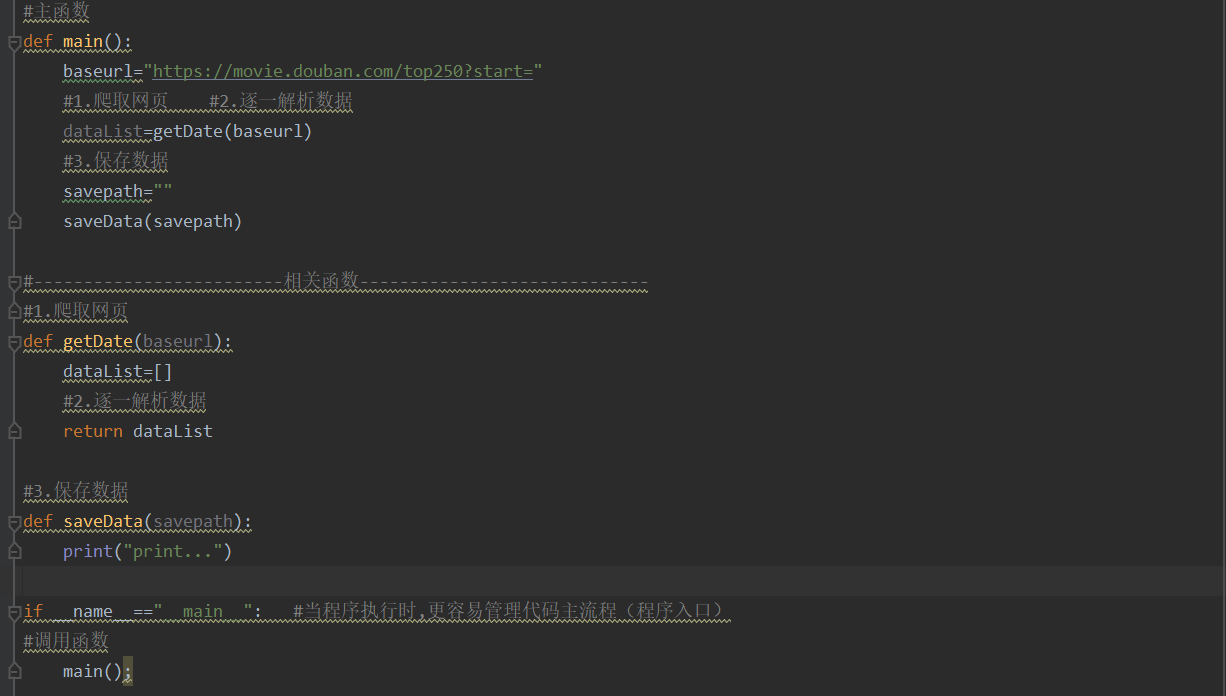
4.获取数据,逐一进行解析
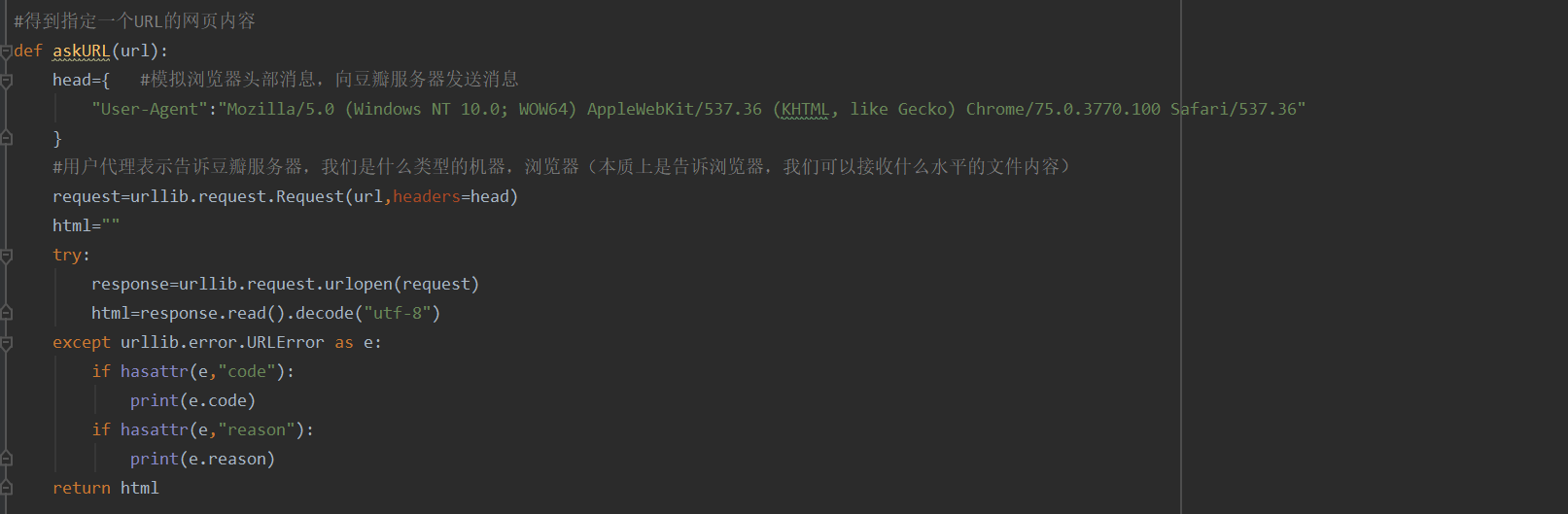
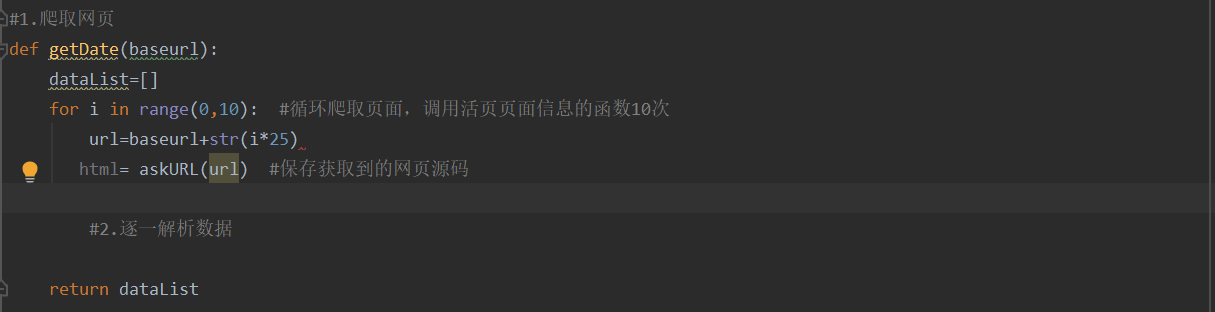
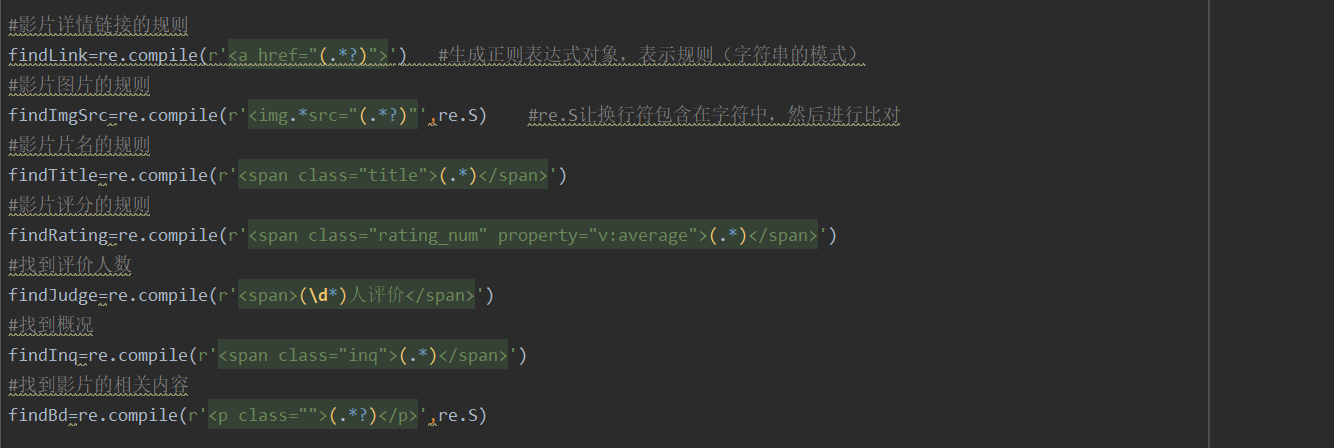
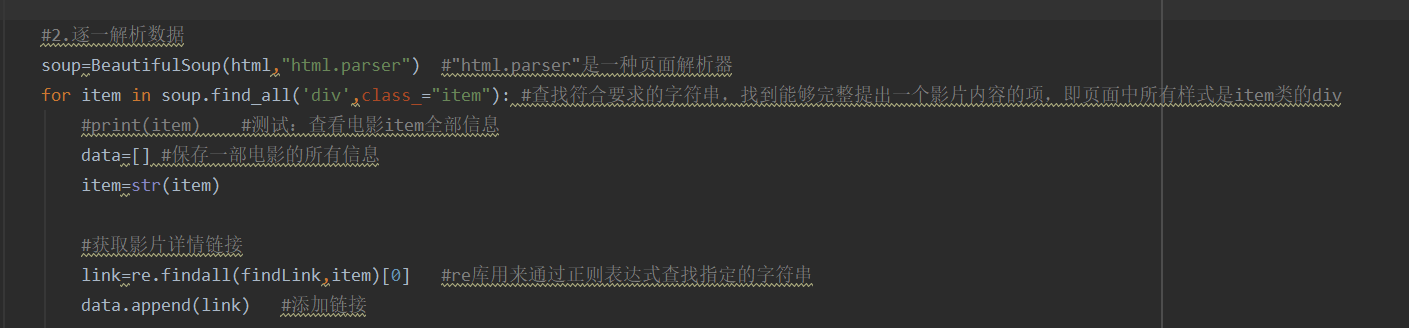
5.正则提取,解析内容
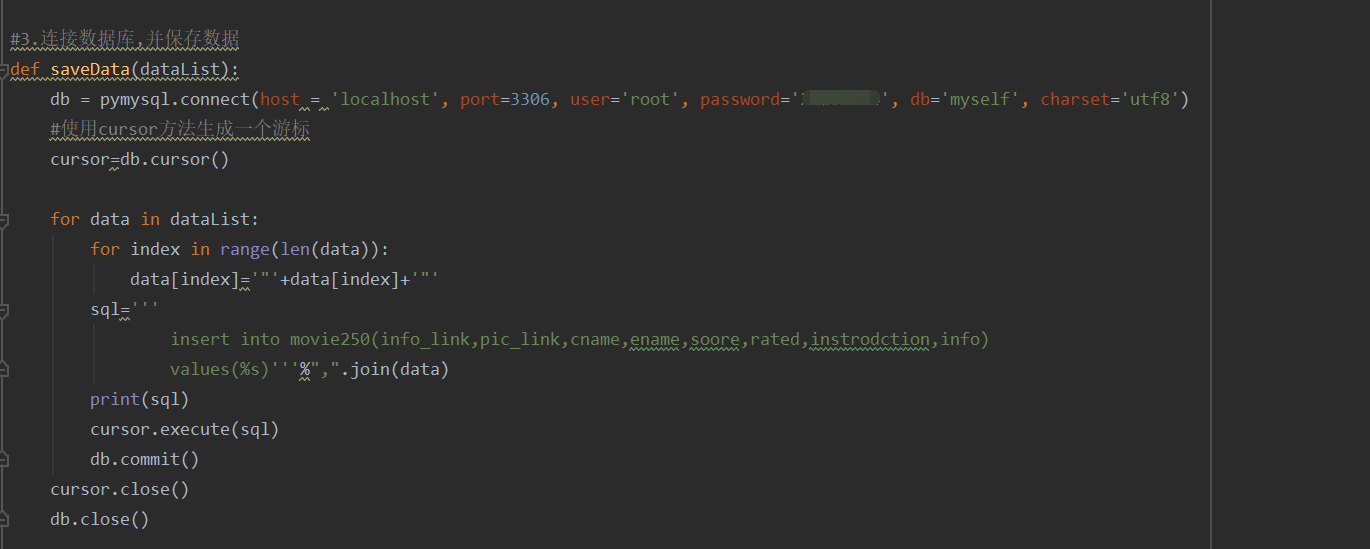
5.连接数据库,并保存数据
五、程序源码及运行截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号