Elasticsearch从入门到熟练使用
搜索引擎原理
一、搜索引擎核心概念
索引原理:对列值创建排序存储,数据结构={索引,行地址},在有序类表中就可以利用二分查找等方式快速找到要查找的行的地址,再根据行地址直接取数据。
索引排序原理:数值列和时间列直接按大小排序,文本列按文本对应的字符编码大小进行排序,依次对每个字符进行排序。
数据库特点:数据库适合结构化数据的精确查询,不适合半结构化、非结构化的的模糊查询及灵活搜索(特别是大数据量),针对数据表量不大的情况下模糊查询 可以使用mysql分词索引技术。
正向索引:由id到关键词
反向索引:关键词到id,反向索引大小是有限的
索引设计:关键词,标题还有关键词文章id,内容包含关键词文章id,其他列包含关键词文章id。索引中可以记录关键词出现的位置和频率,用于短语查询、高亮
建立索引:分词器,常用中文分词器IKAnalyzer mmseg4j
搜索:搜索是对输入进行分词,分别搜索然后合并结果
排序:排序按照相关性来排,相关性可以基于出现次数、标题和内容中权重不同
索引更新:先删后加
搜索引擎作用:支持全文检索,必须支持精确查询
二、lucene
lucene是java开源的搜索引擎开发工具包,sola及es均是在此基础上的二次开发,我们也可以利用lucene实现自己的搜索引擎,下面给出lucene使用demo
1、lucene 创建索引
public static void createIndex(String indexDir) {
IndexWriter writer = null;
try {
//准备目录
Directory directory = FSDirectory.open(Paths.get((indexDir)));
//准备分词器
Analyzer analyzer = new StandardAnalyzer();
//准备config
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
//创建索引的实例
writer = new IndexWriter(directory, iwConfig);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2、lucene 索引文档
public static void indexDoc(String indexDir, String jsonDoc) {
IndexWriter writer = null;
try {
//准备目录
Directory directory = FSDirectory.open(Paths.get((indexDir)));
//准备分词器
Analyzer analyzer = new StandardAnalyzer();
//准备config
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
//创建索引的实例
writer = new IndexWriter(directory, iwConfig);
Document doc = json2Doc(jsonDoc);
writer.addDocument(doc);
System.out.println("indexed doc suc...");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static Document json2Doc(String strDoc) {
Document doc = new Document();
JSONObject jsonDoc = JSONObject.parseObject(strDoc);
Set<String> keys = jsonDoc.keySet();
for (String key : keys) {
doc.add(new TextField(key, jsonDoc.getString(key), Field.Store.YES));
}
return doc;
}
3、lucene搜索
public static String query(String indexDir, String queryStr) {
String result = "";
IndexReader reader = null;
try {
//准备目录
Directory directory = FSDirectory.open(Paths.get((indexDir)));
//拿到reader
reader = DirectoryReader.open(directory);
//创建indexSearcher实例
IndexSearcher searcher = new IndexSearcher(reader);
//准备分词器
Analyzer analyzer = new StandardAnalyzer();
//创建解析器
QueryParser parser = new QueryParser("songName", analyzer);
Query query = parser.parse(queryStr);
TopDocs hits = searcher.search(query, 10);
System.out.println("hits.size:" + hits.totalHits);
for (ScoreDoc scoreDoc : hits.scoreDocs) {
//拿到文档实例
Document doc = searcher.doc(scoreDoc.doc);
//拿到所有文档字段
List<IndexableField> fields = doc.getFields();
//处理文档字段
for (IndexableField f : fields) {
result += f.name() + ":" + f.stringValue() + ",\r\n";
}
System.out.println(result);
}
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return result;
}
ES安装及核心概念
一、ES架构设计
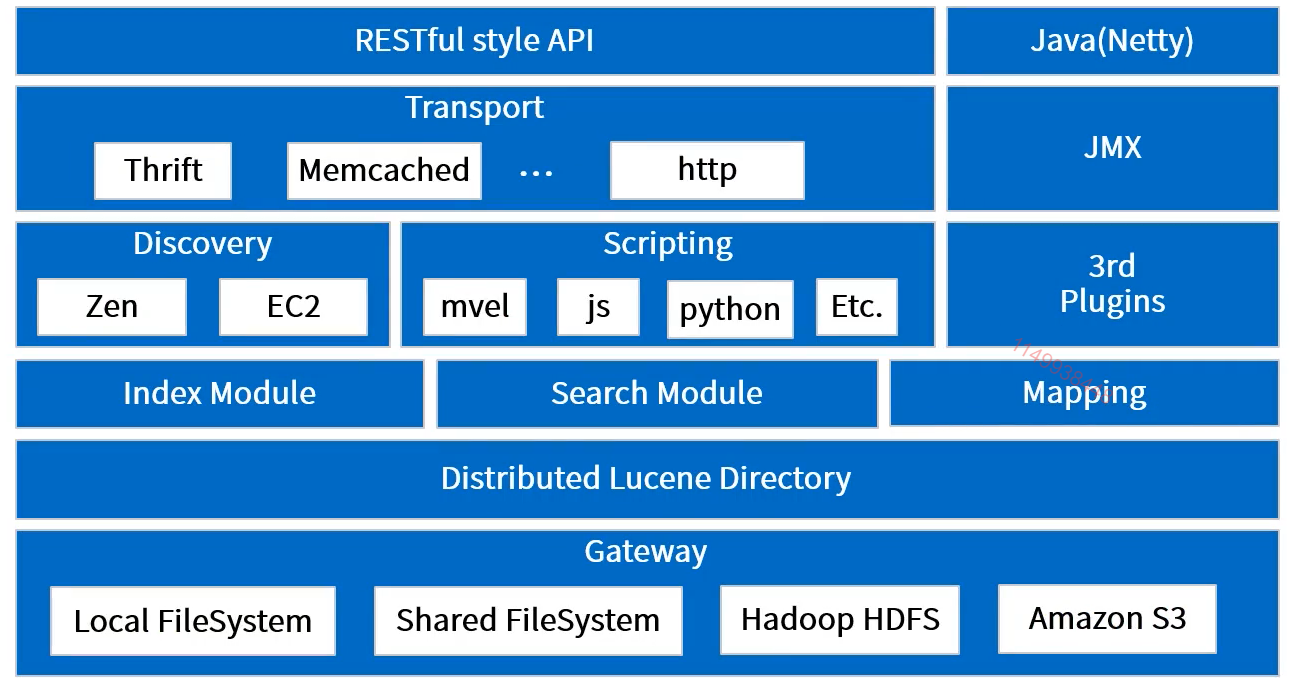
1、Gateway
即Elasticsearch支持的索引数据的存储格式,当Elasticsearch关闭再启动的时候,它就会从这个gateway里面读取索引数据;支持的格式有:本地的Local FileSystem、分布式的Shared FileSystem、Hadoop的文件系统HDFS等。
2、Lucene框架
Elasticsearch 的底层 API 是 由 Lucene 提供的,每一个 Elasticsearch 节点上都有一个 Lucene 引擎的支持 。
3、Elasticsearch数据的加工处理方式
Index Module(创建Index模块)、Search Module(搜索模块)、Mapping(映射)、River(运行在Elasticsearch集群内部的一个插件,主要用来从外部获取获取异构数据,然后在Elasticsearch里创建索引,常见的插件有RabbitMQ River、Twitter River,在2.x之后已经不再使用)。
4、Elasticsearch发现机制、脚本
Discovery 是Elasticsearch自动发现节点的机制;Zen是用来实现节点自动发现、Master节点选举用;(Elasticsearch是基于P2P的系统,它首先通过广播的机制寻找存在的节点,然后再通过多播协议来进行节点间的通信,同时也支持点对点的交互)。Scripting 是脚本执行功能,有这个功能能很方便对查询出来的数据进行加工处理。3rd Plugins 表示Elasticsearch支持安装很多第三方的插件,例如elasticsearch-ik分词插件、elasticsearch-sql sql插件。
5、Elasticsearch 的传输模块和 JMX 。
传输模块支持 Thrift, Memcached 、 HTTP,默认使用 HTTP 传输 。 JMX 是 Java 的管理框架,用来管理 Elasticsearch 应用 。
6、 Elasticsearch的API支持模式
通过RESTful API 和 Elasticsearch 集群进行交互。
二、ES单机安装
添加es用户
useradd es
passwd es
vi /etc/sysctl.conf,在文件最后面添加内容:
vm.max_map_count=262144 #es对内存有要求,最低为262144
vi /etc/security/limits.conf,添加如下内容
* hard nofile 65536 #一个进程最多可以打开多少个文件
* soft nofile 65536
* soft nproc 2048 #一个操作系统用户可以创建多少个进程
* hard nproc 4096
vi /etc/security/limits.d/90-nproc.conf,修改 * soft nproc 1024为
* soft nproc 4096
es下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz
安装jdk
修改es配置文件,没有就添加,有的话就放开注释或者修改
cluster.name: my-application
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
进入es 目录
bin/elasticsearch
访问9200端口,查看是否安装成功
安装kibana
解压后进入config目录,修改kibana.yml
server.port:5601
server.host:0.0.0.0
elasticsearch.url:"http://192.168.1.125:9200"
kibana.index:".kibana"
进入kibana目录,启动kibana
ES Document APIs
在ES最初设计中,index被当作DB,能够对数据进行物理隔离,type相当于数据库中表,对数据进行逻辑划分,document相当于一条数据,在ES5.6版本后逐渐弱化type概念,直至移除。
1、索引操作
#简单创建索引
PUT /songs_V3
#删除索引
DELETE /songs_v4
#创建索引,并配置shards、replicas
PUT /songs_v4
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 2
}
}
#获取settings
GET /songs_v4/_settings
#修改配置信息,index的配置分为两类:
static: index.number_of_shards、index.shard.check_on_startup #index正常工作不能修改
dynamic:index.number_of_replicas#index工作时可以修改
#修改settings,可以正确执行
PUT /songs_v4/_settings
{
"number_of_replicas": 2
}
#下面直接修改会报错,需先关闭index
PUT /songs_v4/_settings
{
"index.shard.check_on_startup" : true
}
关闭索引
POST /songs_v1/_close
开启索引
POST /songs_v1/_open
获取mappings,不支持修改
GET /songs_v1/_mappings
#索引文档,显示指定文档id
PUT /songs_v4/popular/5
{
"songName" : "could this be love",
"singer" : "Jennifer Lopez",
"lyrics" : "Could This Be love,Woke Up "
}
#索引文档,随机生成文档id
POST /songs_v4/popular
{
"songName" : "could this be love",
"singer" : "Jennifer Lopez",
"lyrics" : "Could This Be love"
}
#更新文档:
PUT /songs_v4/popular/5
{
"songName" : "could this be love",
"singer" : "Jennifer Lopez1111",
"lyrics" : "Could This"
}
#根据id,明确查询某条数据
GET /songs_v4/popular/5
#删除文档:
DELETE /songs_v4/popular/5
#再次查询,不再有id为5的文档
GET /songs_v4/popular/5
#搜索document:
GET /songs_v4/_search?q=singer:Jennifer
#创建index后,指定Mapping
PUT /books
PUT /books/_mapping/science
{
"properties": {
"bookName" : {"type": "text"},
"content" : {"type": "text"}
}
}
#创建index时指定mapping
PUT test
{
"mappings" : {
"type1" : {
"properties" : {
"field1" : { "type" : "text" }
}
}
}
}
#修改mapping,添加author字段
PUT /books/_mapping/science
{
"properties":{
"author":{"type":"text"}
}
}
#ES支持动态映射和静态映射,通过dynamic来指定动态映射效果,dynamic有三种值
true:(默认值) MApping会动态更新
false:MApping不会动态更新,_source字段会存储新字段
strict:直接报错
#动态映射,会发现字段会自动匹配类型
GET /books/_mappings
POST /books/science
{
"content" : "this is the content of the book"
}
POST /books/science
{
"for_child" : true
}
POST /books/science
{
"publish_date" : "2018-01-01"
}
#关闭 自动时间类型匹配
PUT /books/_mapping/science
{
"date_detection":false
}
2、别名使用
#指定别名
PUT /songs_v1/_alias/songs
#通过别名查询数据
GET /songs/_search?q=songName:your
#创建新的索引
PUT /songs_v2
#并将数据同步到这个新的 index(略)
#将alias指向新的 index
POST /_aliases
{
"actions": [
{
"add": {
"index": "songs_v2",
"alias": "songs"
}
},
{
"remove": {
"index": "songs_v1",
"alias": "songs"
}
}
]
}
#索引一条数据到songs_v2(略)
#songs alias已经指向了songs_v2,可以让它同时也指向songs_v1
POST /_aliases
{
"actions": [
{
"add": {
"index": "songs_v1",
"alias": "songs"
}
}
]
}
#把alias当视图使用
POST /_aliases
{
"actions": [
{
"add": {
"index": "songs_v1",
"alias": "songs_james",
"filter": {
"match":{
"singer" : "James"
}
}
}
}
]
}
ES字段类型及属性
参考官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
映射参数属性设置要点:
利用fields属性定义多重字段,既可以全文检索,又可以关键词排序聚合等。
利用doc_values创建正向索引,用于排序、聚合和脚本操作, 作用于不分词的字段,默认开启
设置一个字段store属性为true,ES会单独保存这个字段,用于大文本字段(source不存储)或者_source属性为false时
ES java client
Java low level REST client,低级别REST客户端,通过http与es交互,需要自己编组json字符串及解析响应字符串
Java high level REST client,高级别REST客户端,基于low level REST client,其中的操作和java client大部分是一样的。
java client 在7.0版本之后将开始废弃TransportClient,取而带之的是high level REST client。
基于java client的demo
maven依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.4.0</version>
</dependency>
InitDemo
public class InitDemo {
private static TransportClient client;
public static TransportClient getClient() throws UnknownHostException {
if(client == null) {
//client = new PreBuiltTransportClient(Settings.EMPTY)
// 连接集群的设置
Settings settings = Settings.builder()
.put("cluster.name", "elasticsearch") //如果集群的名字不是默认的elasticsearch,需指定
.put("client.transport.sniff", true) //自动嗅探
//.put("xpack.security.user", "elastic:123456")
.build();
client = new PreBuiltTransportClient(settings)
//client = new PreBuiltXPackTransportClient(settings)
.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.100.112"), 9300));
//可用连接设置参数说明
/*
cluster.name
指定集群的名字,如果集群的名字不是默认的elasticsearch,需指定。
client.transport.sniff
设置为true,将自动嗅探整个集群,自动加入集群的节点到连接列表中。
client.transport.ignore_cluster_name
Set to true to ignore cluster name validation of connected nodes. (since 0.19.4)
client.transport.ping_timeout
The time to wait for a ping response from a node. Defaults to 5s.
client.transport.nodes_sampler_interval
How often to sample / ping the nodes listed and connected. Defaults to 5s.
*/
}
return client;
}
}
CreateIndexDemo
public class CreateIndexDemo {
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
// 1、创建 创建索引request
CreateIndexRequest request = new CreateIndexRequest("mess");
// 2、设置索引的settings
request.settings(Settings.builder().put("index.number_of_shards", 3) // 分片数
.put("index.number_of_replicas", 2) // 副本数
.put("analysis.analyzer.default.tokenizer", "ik_smart") // 默认分词器
);
// 3、设置索引的mappings
request.mapping("_doc",
" {\n" +
" \"_doc\": {\n" +
" \"properties\": {\n" +
" \"message\": {\n" +
" \"type\": \"text\"\n" +
" }\n" +
" }\n" +
" }\n" +
" }",
XContentType.JSON);
// 4、 设置索引的别名
request.alias(new Alias("mmm"));
// 5、 发送请求
CreateIndexResponse createIndexResponse = client.admin().indices()
.create(request).get();
// 6、处理响应
boolean acknowledged = createIndexResponse.isAcknowledged();
boolean shardsAcknowledged = createIndexResponse
.isShardsAcknowledged();
System.out.println("acknowledged = " + acknowledged);
System.out.println("shardsAcknowledged = " + shardsAcknowledged);
// listener方式发送请求
/*ActionListener<CreateIndexResponse> listener = new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(
CreateIndexResponse createIndexResponse) {
// 6、处理响应
boolean acknowledged = createIndexResponse.isAcknowledged();
boolean shardsAcknowledged = createIndexResponse
.isShardsAcknowledged();
System.out.println("acknowledged = " + acknowledged);
System.out.println(
"shardsAcknowledged = " + shardsAcknowledged);
}
@Override
public void onFailure(Exception e) {
System.out.println("创建索引异常:" + e.getMessage());
}
};
client.admin().indices().create(request, listener);
*/
} catch (IOException | InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
IndexDocumentDemo
public class IndexDocumentDemo {
private static Logger logger = LogManager.getRootLogger();
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
// 1、创建索引请求
IndexRequest request = new IndexRequest(
"mess", //索引
"_doc", // mapping type
"11"); //文档id
// 2、准备文档数据
// 方式一:直接给JSON串
String jsonString = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
request.source(jsonString, XContentType.JSON);
// 方式二:以map对象来表示文档
/*
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("user", "kimchy");
jsonMap.put("postDate", new Date());
jsonMap.put("message", "trying out Elasticsearch");
request.source(jsonMap);
*/
// 方式三:用XContentBuilder来构建文档
/*
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("user", "kimchy");
builder.field("postDate", new Date());
builder.field("message", "trying out Elasticsearch");
}
builder.endObject();
request.source(builder);
*/
// 方式四:直接用key-value对给出
/*
request.source("user", "kimchy",
"postDate", new Date(),
"message", "trying out Elasticsearch");
*/
//3、其他的一些可选设置
/*
request.routing("routing"); //设置routing值
request.timeout(TimeValue.timeValueSeconds(1)); //设置主分片等待时长
request.setRefreshPolicy("wait_for"); //设置重刷新策略
request.version(2); //设置版本号
request.opType(DocWriteRequest.OpType.CREATE); //操作类别
*/
//4、发送请求
IndexResponse indexResponse = null;
try {
//方式一: 用client.index 方法,返回是 ActionFuture<IndexResponse>,再调用get获取响应结果
indexResponse = client.index(request).get();
//方式二:client提供了一个 prepareIndex方法,内部为我们创建IndexRequest
/*IndexResponse indexResponse = client.prepareIndex("mess","_doc","11")
.setSource(jsonString, XContentType.JSON)
.get();*/
//方式三:request + listener
//client.index(request, listener);
} catch(ElasticsearchException e) {
// 捕获,并处理异常
//判断是否版本冲突、create但文档已存在冲突
if (e.status() == RestStatus.CONFLICT) {
logger.error("冲突了,请在此写冲突处理逻辑!\n" + e.getDetailedMessage());
}
logger.error("索引异常", e);
}catch (InterruptedException | ExecutionException e) {
logger.error("索引异常", e);
}
//5、处理响应
if(indexResponse != null) {
String index = indexResponse.getIndex();
String type = indexResponse.getType();
String id = indexResponse.getId();
long version = indexResponse.getVersion();
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) {
System.out.println("新增文档成功,处理逻辑代码写到这里。");
} else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) {
System.out.println("修改文档成功,处理逻辑代码写到这里。");
}
// 分片处理信息
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
}
// 如果有分片副本失败,可以获得失败原因信息
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
String reason = failure.reason();
System.out.println("副本失败原因:" + reason);
}
}
}
//listener 方式
/*ActionListener<IndexResponse> listener = new ActionListener<IndexResponse>() {
@Override
public void onResponse(IndexResponse indexResponse) {
}
@Override
public void onFailure(Exception e) {
}
};
client.index(request, listener);
*/
} catch (IOException e) {
e.printStackTrace();
}
}
}
BulkDemo
public class BulkDemo {
private static Logger logger = LogManager.getRootLogger();
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
// 1、创建批量操作请求
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("mess", "_doc", "1")
.source(XContentType.JSON,"field", "foo"));
request.add(new IndexRequest("mess", "_doc", "2")
.source(XContentType.JSON,"field", "bar"));
request.add(new IndexRequest("mess", "_doc", "3")
.source(XContentType.JSON,"field", "baz"));
/*
request.add(new DeleteRequest("mess", "_doc", "3"));
request.add(new UpdateRequest("mess", "_doc", "2")
.doc(XContentType.JSON,"other", "test"));
request.add(new IndexRequest("mess", "_doc", "4")
.source(XContentType.JSON,"field", "baz"));
*/
// 2、可选的设置
/*
request.timeout("2m");
request.setRefreshPolicy("wait_for");
request.waitForActiveShards(2);
*/
//3、发送请求
// 同步请求
BulkResponse bulkResponse = client.bulk(request).get();
//4、处理响应
if(bulkResponse != null) {
for (BulkItemResponse bulkItemResponse : bulkResponse) {
DocWriteResponse itemResponse = bulkItemResponse.getResponse();
if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX
|| bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) {
IndexResponse indexResponse = (IndexResponse) itemResponse;
//TODO 新增成功的处理
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) {
UpdateResponse updateResponse = (UpdateResponse) itemResponse;
//TODO 修改成功的处理
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) {
DeleteResponse deleteResponse = (DeleteResponse) itemResponse;
//TODO 删除成功的处理
}
}
}
//异步方式发送批量操作请求
/*
ActionListener<BulkResponse> listener = new ActionListener<BulkResponse>() {
@Override
public void onResponse(BulkResponse bulkResponse) {
}
@Override
public void onFailure(Exception e) {
}
};
client.bulkAsync(request, listener);
*/
} catch (IOException | InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
GetDocumentDemo
public class GetDocumentDemo {
private static Logger logger = LogManager.getRootLogger();
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
// 1、创建获取文档请求
GetRequest request = new GetRequest(
"mess", //索引
"_doc", // mapping type
"11"); //文档id
// 2、可选的设置
//request.routing("routing");
//request.version(2);
//request.fetchSourceContext(new FetchSourceContext(false)); //是否获取_source字段
//选择返回的字段
String[] includes = new String[]{"message", "*Date"};
String[] excludes = Strings.EMPTY_ARRAY;
FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);
//也可写成这样
/*String[] includes = Strings.EMPTY_ARRAY;
String[] excludes = new String[]{"message"};
FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);*/
// 取stored字段
/*request.storedFields("message");
GetResponse getResponse = client.get(request);
String message = getResponse.getField("message").getValue();*/
//3、发送请求
GetResponse getResponse = null;
try {
getResponse = client.get(request).get();
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
logger.error("没有找到该id的文档" );
}
if (e.status() == RestStatus.CONFLICT) {
logger.error("获取时版本冲突了,请在此写冲突处理逻辑!" );
}
logger.error("获取文档异常", e);
}catch (InterruptedException | ExecutionException e) {
logger.error("索引异常", e);
}
//4、处理响应
if(getResponse != null) {
String index = getResponse.getIndex();
String type = getResponse.getType();
String id = getResponse.getId();
if (getResponse.isExists()) { // 文档存在
long version = getResponse.getVersion();
String sourceAsString = getResponse.getSourceAsString(); //结果取成 String
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap(); // 结果取成Map
byte[] sourceAsBytes = getResponse.getSourceAsBytes(); //结果取成字节数组
logger.info("index:" + index + " type:" + type + " id:" + id);
logger.info(sourceAsString);
} else {
logger.error("没有找到该id的文档" );
}
}
//异步方式发送获取文档请求
/*
ActionListener<GetResponse> listener = new ActionListener<GetResponse>() {
@Override
public void onResponse(GetResponse getResponse) {
}
@Override
public void onFailure(Exception e) {
}
};
client.getAsync(request, listener);
*/
} catch (IOException e) {
e.printStackTrace();
}
}
}
HighlightDemo
public class HighlightDemo {
private static Logger logger = LogManager.getRootLogger();
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
// 1、创建search请求
SearchRequest searchRequest = new SearchRequest("hl_test");
// 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//构造QueryBuilder
QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "lucene solr");
sourceBuilder.query(matchQueryBuilder);
//分页设置
/*sourceBuilder.from(0);
sourceBuilder.size(5); ;*/
// 高亮设置
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.requireFieldMatch(false).field("title").field("content")
.preTags("<strong>").postTags("</strong>");
//不同字段可有不同设置,如不同标签
/*HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title");
highlightTitle.preTags("<strong>").postTags("</strong>");
highlightBuilder.field(highlightTitle);
HighlightBuilder.Field highlightContent = new HighlightBuilder.Field("content");
highlightContent.preTags("<b>").postTags("</b>");
highlightBuilder.field(highlightContent).requireFieldMatch(false);*/
sourceBuilder.highlighter(highlightBuilder);
searchRequest.source(sourceBuilder);
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest).get();
//4、处理响应
if(RestStatus.OK.equals(searchResponse.status())) {
//处理搜索命中文档结果
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
//取_source字段值
//String sourceAsString = hit.getSourceAsString(); //取成json串
Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // 取成map对象
//从map中取字段值
/*String title = (String) sourceAsMap.get("title");
String content = (String) sourceAsMap.get("content"); */
logger.info("index:" + index + " type:" + type + " id:" + id);
logger.info("sourceMap : " + sourceAsMap);
//取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField highlight = highlightFields.get("title");
if(highlight != null) {
Text[] fragments = highlight.fragments(); //多值的字段会有多个值
if(fragments != null) {
String fragmentString = fragments[0].string();
logger.info("title highlight : " + fragmentString);
//可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用
//sourceAsMap.put("title", fragmentString);
}
}
highlight = highlightFields.get("content");
if(highlight != null) {
Text[] fragments = highlight.fragments(); //多值的字段会有多个值
if(fragments != null) {
String fragmentString = fragments[0].string();
logger.info("content highlight : " + fragmentString);
//可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用
//sourceAsMap.put("content", fragmentString);
}
}
}
}
} catch (IOException | InterruptedException | ExecutionException e) {
logger.error(e);
}
}
}
AggregationDemo
package es.search;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.BucketOrder;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.avg.Avg;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
public class AggregationDemo {
private static Logger logger = LogManager.getRootLogger();
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
// 1、创建search请求
SearchRequest searchRequest = new SearchRequest("bank");
// 2、用SearchSourceBuilder来构造查询请求体(请仔细查看它的方法,构造各种查询的方法都在这)
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0);
//添加聚合(做terms聚合,按照age分组,聚合后的名称为by_age,分组按照average_balance排序)
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_age")
.field("age").order(BucketOrder.aggregation("average_balance", true));
//指定下级聚合(聚合类型为avg、按照balance取平均值、聚合后的名称为average_balance)
aggregation.subAggregation(AggregationBuilders.avg("average_balance")
.field("balance"));
sourceBuilder.aggregation(aggregation);
searchRequest.source(sourceBuilder);
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest).get();
//4、处理响应
if(RestStatus.OK.equals(searchResponse.status())) { //获取搜索结果状态
Aggregations aggregations = searchResponse.getAggregations(); //获取response中所有聚合结果
Terms byAgeAggregation = aggregations.get("by_age"); //获取by_age聚合
logger.info("aggregation by_age 结果");
logger.info("docCountError: " + byAgeAggregation.getDocCountError());
logger.info("sumOfOtherDocCounts: " + byAgeAggregation.getSumOfOtherDocCounts());
logger.info("------------------------------------");
for(Bucket buck : byAgeAggregation.getBuckets()) {
logger.info("key: " + buck.getKeyAsNumber());
logger.info("docCount: " + buck.getDocCount());
//logger.info("docCountError: " + buck.getDocCountError());
//取子聚合
Avg averageBalance = buck.getAggregations().get("average_balance");
logger.info("average_balance: " + averageBalance.getValue());
logger.info("------------------------------------");
}
//直接用key 来去分组
/*Bucket elasticBucket = byCompanyAggregation.getBucketByKey("24");
Avg averageAge = elasticBucket.getAggregations().get("average_age");
double avg = averageAge.getValue();*/
}
} catch (IOException | InterruptedException | ExecutionException e) {
logger.error(e);
}
}
}
SearchDemo
public class SearchDemo {
public static void main(String args[]) throws UnknownHostException {
//配置信息
Settings settings = Settings.builder()
.put("cluster.name", "es-study") //指定集群名称
.put("client.transport.sniff", true) //自动嗅探
.build();
/**
嗅探:客户端只需要指定一个ES服务端节点连接信息,连接上之后,如果开启了嗅探机制,
就会自动拉取服务端各节点的信息到客户端,从而避免我们需要配置一长串服务端连接信息
*/
//构建client
TransportClient client = new PreBuiltTransportClient(settings);
//指定ip、port
client.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.90.131"), 9300)); //9300为TCP通信端口
try {
//构建request
SearchRequest request = new SearchRequest();
request.indices("music");
request.types("songs");
//构建搜索
SearchSourceBuilder search = new SearchSourceBuilder();
search.query(QueryBuilders.matchQuery("songName", "take me to your heart"));
search.timeout(new TimeValue(60, TimeUnit.SECONDS));
//search放入到request中
request.source(search);
//执行搜索
SearchResponse response = client.search(request).get();
//获取命中的文档
SearchHits hits = response.getHits();
SearchHit[] hitArr = hits.getHits();
System.out.println("搜索到" + hits.totalHits + "个文档");
//处理命中的文档
for (SearchHit hit : hitArr){
//打印元信息
System.out.println(hit.getType() + "," + hit.getScore());
//打印原文档
String sourceAsStrig = hit.getSourceAsString();
System.out.println(sourceAsStrig);
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
client.close();
}
}
}
SuggestDemo
public class SuggestDemo {
private static Logger logger = LogManager.getRootLogger();
public static void termSuggest(TransportClient client) {
// 1、创建search请求
//SearchRequest searchRequest = new SearchRequest();
SearchRequest searchRequest = new SearchRequest("mess");
// 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0);
//做查询建议
//词项建议
SuggestionBuilder termSuggestionBuilder =
SuggestBuilders.termSuggestion("user").text("kmichy");
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder);
sourceBuilder.suggest(suggestBuilder);
searchRequest.source(sourceBuilder);
try{
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest).get();
//4、处理响应
//搜索结果状态信息
if(RestStatus.OK.equals(searchResponse.status())) {
// 获取建议结果
Suggest suggest = searchResponse.getSuggest();
TermSuggestion termSuggestion = suggest.getSuggestion("suggest_user");
for (TermSuggestion.Entry entry : termSuggestion.getEntries()) {
logger.info("text: " + entry.getText().string());
for (TermSuggestion.Entry.Option option : entry) {
String suggestText = option.getText().string();
logger.info(" suggest option : " + suggestText);
}
}
}
} catch (InterruptedException | ExecutionException e) {
logger.error(e);
}
/*
"suggest": {
"my-suggestion": [
{
"text": "tring",
"offset": 0,
"length": 5,
"options": [
{
"text": "trying",
"score": 0.8,
"freq": 1
}
]
},
{
"text": "out",
"offset": 6,
"length": 3,
"options": []
},
{
"text": "elasticsearch",
"offset": 10,
"length": 13,
"options": []
}
]
}*/
}
public static void completionSuggester(TransportClient client) {
// 1、创建search请求
//SearchRequest searchRequest = new SearchRequest();
SearchRequest searchRequest = new SearchRequest("music");
// 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0);
//做查询建议
//自动补全
/*POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "lucene s",
"completion" : {
"field" : "suggest" ,
"skip_duplicates": true
}
}
}
}*/
SuggestionBuilder termSuggestionBuilder =
SuggestBuilders.completionSuggestion("suggest").prefix("lucene s")
.skipDuplicates(true);
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("song-suggest", termSuggestionBuilder);
sourceBuilder.suggest(suggestBuilder);
searchRequest.source(sourceBuilder);
try {
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest).get();
//4、处理响应
//搜索结果状态信息
if(RestStatus.OK.equals(searchResponse.status())) {
// 获取建议结果
Suggest suggest = searchResponse.getSuggest();
CompletionSuggestion termSuggestion = suggest.getSuggestion("song-suggest");
for (CompletionSuggestion.Entry entry : termSuggestion.getEntries()) {
logger.info("text: " + entry.getText().string());
for (CompletionSuggestion.Entry.Option option : entry) {
String suggestText = option.getText().string();
logger.info(" suggest option : " + suggestText);
}
}
}
} catch (InterruptedException | ExecutionException e) {
logger.error(e);
}
}
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
termSuggest(client);
logger.info("--------------------------------------");
completionSuggester(client);
} catch (IOException e) {
logger.error(e);
}
}
}
AggregationDemo
public class AggregationDemo {
private static Logger logger = LogManager.getRootLogger();
public static void main(String[] args) {
try (TransportClient client = InitDemo.getClient();) {
// 1、创建search请求
SearchRequest searchRequest = new SearchRequest("bank");
// 2、用SearchSourceBuilder来构造查询请求体(请仔细查看它的方法,构造各种查询的方法都在这)
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0);
//添加聚合(做terms聚合,按照age分组,聚合后的名称为by_age,分组按照average_balance排序)
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_age")
.field("age").order(BucketOrder.aggregation("average_balance", true));
//指定下级聚合(聚合类型为avg、按照balance取平均值、聚合后的名称为average_balance)
aggregation.subAggregation(AggregationBuilders.avg("average_balance")
.field("balance"));
sourceBuilder.aggregation(aggregation);
searchRequest.source(sourceBuilder);
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest).get();
//4、处理响应
if(RestStatus.OK.equals(searchResponse.status())) { //获取搜索结果状态
Aggregations aggregations = searchResponse.getAggregations(); //获取response中所有聚合结果
Terms byAgeAggregation = aggregations.get("by_age"); //获取by_age聚合
logger.info("aggregation by_age 结果");
logger.info("docCountError: " + byAgeAggregation.getDocCountError());
logger.info("sumOfOtherDocCounts: " + byAgeAggregation.getSumOfOtherDocCounts());
logger.info("------------------------------------");
for(Bucket buck : byAgeAggregation.getBuckets()) {
logger.info("key: " + buck.getKeyAsNumber());
logger.info("docCount: " + buck.getDocCount());
//logger.info("docCountError: " + buck.getDocCountError());
//取子聚合
Avg averageBalance = buck.getAggregations().get("average_balance");
logger.info("average_balance: " + averageBalance.getValue());
logger.info("------------------------------------");
}
//直接用key 来去分组
/*Bucket elasticBucket = byCompanyAggregation.getBucketByKey("24");
Avg averageAge = elasticBucket.getAggregations().get("average_age");
double avg = averageAge.getValue();*/
}
} catch (IOException | InterruptedException | ExecutionException e) {
logger.error(e);
}
}
}
Java high level REST client 实战
gitbub地址:https://github.com/junlin-2019/es-learn.git
ES 搜索
参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-request-body.html
1、from/size分页
from/size分页 会有深分页问题,替代方案:Scroll 比较消耗资源 search after 通过max sort
#用search after解决深分页性能问题
#第一页
GET /bank/_search
{
"size": 10,
"sort": [
{
"account_number": {
"order": "asc"
}
}
]
}
#第二页
GET /bank/_search
{
"size": 10,
"sort": [
{
"account_number": {
"order": "asc"
}
}
],
"search_after" : [13]
}
2、collapse 折叠
collapse 折叠,按照某个字段每种类型只返回一条数据
GET /music_v11/_search
{
"collapse": {
"field": "songName.keyword"
}
}
#两级折叠
GET /music_v11/_search
{
"collapse": {
"field": "songName.keyword",
"inner_hits" : {
"name" : "singers",
"collapse" : {
"field" : "singer.keyword"
},
"size" : 5
}
}
}
3、_souce
_souce 指定返回的字段
# true\false 指定是否返回_source
GET /bank/_search?size=5
{
"query": {
"match_all": {}
},
"_source": true
}
#明确指定要返回的字段
GET /bank/_search
{
"_source": ["address", "balance"]
}
#将两个字段排除在外
GET /bank/_search
{
"_source": {
"excludes": ["address", "balance"]
}
}
4、stored_fields
stored_fields 返回指定store属性的字段,对于非store字段,没有任何意义
GET /songs_v20/_search
{
"_source": true,
"query": {
"match_all": {}
},
"stored_fields": ["songName", "singer", "lyrics"]
}
5、version
version 返回版本信息
GET /bank/account/_search
{
"query": {
"term": {
"_id": {
"value": "20"
}
}
},
"version": true
}
6、script field
script field 将字段计算后返回
GET /bank/_search
{
"_source": true,
"query": {
"term": {
"_id": {
"value": "20"
}
}
},
"script_fields": {
"age_2year_later": {
"script" : {
"lang": "painless",
"source" : "doc['age'].value + 2"
}
},
"age_2year_before" : {
"script" : {
"lang": "painless",
"source" : "doc['age'].value - 2"
}
}
}
}
7、min_score
min_score 去掉评分低的
GET /songs_v1/_search
{
"query": {
"match": {
"lyrics": "so many people all around world"
}
},
"min_score" : 1
}
8、sort mode
多值字段排序
GET /numbers/_search
{
"sort": [
{
"numbers": {
"order": "asc",
"mode": "min"
}
}
]
}
9、sort script value
GET /numbers/_search
{
"sort": [
{
"_script" : {
"type" : "number",
"script" : {
"lang" : "painless",
"source" : "doc['numbers'].length"
},
"order": "desc"
}
}
]
}
10、全文检索
全文检索完全匹配,必须包含分词后的所有词
GET /songs_v1/_search
{
"query": {
"match": {
"lyrics": {
"query": "All I need is someone who makes me wanna sing",
"operator": "and"
}
}
}
}
全文检索完全匹配,可以指定模糊匹配的字符数量
GET /songs_v1/_search
{
"query": {
"match": {
"lyrics": {
"query": "All I need is somene who makes me wanna sing",
"operator": "and",
"fuzziness": 1 # 可以允许有一个字符不匹配
}
}
}
}
11、match_phrase
match_phrase 短语相对位置匹配
GET /songs_v1/_search
{
"query": {
"match_phrase": {
"lyrics": "take me" #必须take在前,me在后
}
}
}
match_phrase 短语完全匹配
GET /songs_v1/popular/_search
{
"query": {
"match_phrase": {
"songName": {
"query": "take your ",
"slop": 1 #允许隔开的单词数
}
}
}
}
match_phrase 前缀查询
GET /songs_v1/_search
{
"query": {
"match_phrase_prefix": {
"songName": "take me"
}
}
}
12、多字段匹配
GET /songs_v1/_search
{
"query": {
"multi_match": {
"query": "take me to your heart",
"fields": ["songName", "lyrics"]
}
}
}
13、模糊匹配
GET /bank/_search
{
"query": {
"simple_query_string" : {
"fields" : ["address"],
"query" : "street*"
}
}
}
14、term query
不会对查询短语分词
GET /bank/_search
{
"query": {
"term": {
"_id": {
"value": "50"
}
}
}
}
GET /bank/_search
{
"query": {
"term": {
"firstname.keyword": { #需设置mapping是对text字段再分词
"value": "Aurelia"
}
}
}
}
GET /bank/_search
{
"query": {
"terms": { #多值匹配
"age": [
40,
33
]
}
}
}
15、Terms lookup
#select * from bank where age = {select age from bank where id =6}
GET /bank/_search
{
"query": {
"terms": {
"age":{
"index" : "bank",
"type" : "account",
"id" : "6",
"path" : "age"
}
}
}
}
16、range query
GET /bank/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}
高级查询
一、查询建议
官网参考:https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-suggesters.html
term suggester
post /bolgs/_search
{
"suggest":{
"MY SUGGEST":{
"text":"华润玩家",
"term":{
"field":"projectName",
"suggest_mode":"missing"
}
}
}
}
二、聚合分析
1、指标聚合
# select max(age) from bank
POST /bank/_search
{
"size": 0,
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
# select count(age) from bank
POST /bank/_count
{
"query" : {
"match" : {
"age" : 24
}
}
}
--------------
POST /bank/_search
{
"query": {
"term": {
"age": {
"value": 24
}
}
},
"aggs": {
"age_count": {
"value_count": {
"field": "age"
}
}
}
}
POST /bank/_search
{
"aggs": {
"age_count": {
"cardinality": { #去重后计数
"field": "age",
"missing":0 缺失值
}
}
}
}
#聚合 脚本值
POST /bank/_search?size=0
{
"aggs": {
"avg_age_yearlater": {
"avg": {
"script": "doc.age.value + 1"
}
}
}
}
#指定field,用value取值
POST /bank/_search?size=0
{
"aggs": {
"max_age": {
"avg": {
"field": "age",
"script": {
"source" : "_value * 2"
}
}
}
}
}
#percentile_ranks 统计各个年龄段占比
GET /bank/_search?size=0
{
"aggs": {
"TEST_NAME": {
"percentile_ranks": {
"field": "age",
"values": [
10,
24,
40
]
}
}
}
}
#Percentiles 统计各个占比对应的年龄,例如占比25的年龄在多少之下
GET /bank/_search?size=0
{
"aggs": {
"TEST_NAME": {
"percentiles": {
"field": "age",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}
2、桶聚合
terms 对散列值进行group
filter 对指定的数据值进行过滤分组
filters 对多个指定的数据值进行分组
range 对连续指标进行分组
date_range 时间字段分组
#平均年龄最年轻的10种状态 terms agg 组内再聚合
GET /bank/_search?size=0
{
"aggs": {
"state_agg": {
"terms": {
"field": "state.keyword",
"order": {
"avg_age": "asc"
},
"size": 10
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
#平均年龄小于30岁的状态 分组过滤 bucket_selector
GET /bank/_search?size=0
{
"aggs": {
"state_agg": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
},
"having" : {
"bucket_selector": {
"buckets_path": {
"avg_age" : "avg_age"
},
"script": "params.avg_age < 30"
}
}
}
}
}
}
#年龄为25岁的用户,男生、女生分别有多少人
POST /bank/_search?size=0
{
"aggs": {
"25yearold": {
"filter": {
"term": {
"age": 25
}
},
"aggs": {
"male_count": {
"filter": {
"term": {
"gender.keyword": "M"
}
}
},
"female_count" : {
"filter": {
"term": {
"gender.keyword": "F"
}
}
}
}
}
}
}
#年龄为20、21、22岁的用户,分别有多少人
GET /bank/_search?size=0
{
"aggs": {
"20_21_22": {
"filters": {
"filters": {
"21": {"term": {
"age": 21
}},
"22" : {"term": {
"age": 22
}},
"23" : { "term": {
"FIELD": 23
}}
}
}
}
}
}
#每个年龄段的男生用户多,还是女生用户多
GET /bank/_search?size=0
{
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [
{"from": 10, "to": 20},
{"from": 20, "to": 30},
{"from": 30, "to": 40},
{"from": 40, "to": 50}
]
},
"aggs": {
"genders": {
"terms": {
"field": "gender.keyword"
}
}
}
}
}
}
#最近一个月,注册了多少用户
POST /bank/_search?size=0
{
"aggs": {
"month_recent": {
"date_range": {
"field": "registered",
"ranges": [
{
"from": "now-1M/M",
"to": "now"
}
]
}
}
}
}
#每个月注册用户量的曲线图
POST /bank/_search?size=0
{
"aggs": {
"MY_NAME": {
"date_histogram": {
"field": "registered",
"interval": "month"
}
}
}
}
ES集群
一、集群规模
数据量、增长规模、机器配置
推算依据:ES JVM heap最大32G 大概可以处理10T数据量
二、集群规划
节点角色:
1、master node 主节点:通过设置node.master:true 指定可作为主节点,具体需要通过选举,mater节点不处理数据,仅作为集群管理和协调
2、DataNode 数据节点: 通过设置node.data:true,执行数据的crud,消耗cpu和内存
3、Ingest node: 默认情况下都是预处理节点,配置node.ingest:false禁用
4、Coordinate Node: 协调节点,将node.data和node.ingest则仅作协调
每个物理节点都可同时担任多个角色,小集群不需要区分,中大集群需要职责明确
三、避免脑裂
出现多个mater节点,网络故障时易出现,成为脑裂,数据不一致
master 节点数为奇数
设置选举发现数量:discovery.zen.minimum_master_nodes:(master资格节点数/2)+1
延长ping master 等待时间:discovery.zen.ping_timeout:30
四、索引分片数量
五、副本数量
六、集群安装
Elasticsearch的安装很简单,下载下来解压即可;Elasticsearch 要求不能使用超级用户root运行,所以我们建立一个elastic账号,并把软件的权限赋予elastic账号并使用elastic账号运行Elasticsearch。
系统环境:CentOS 7
软件版本:
jdk1.8
Elasticsearch-6.4
elasticsearch-head-master:最新版
集群机器列表:
192.168.1.100
192.168.1.101
192.168.1.102
1.解压到/usr/local/
tar -zxvf elasticsearch-6.4.0.tar.gz -C /usr/local/
2.创建账号并设置密码
adduser elastic
passwd elastic
3.给elastic用户elasticsearch目录的授权。
chown -R elastic:elastic /usr/local/elasticsearch-6.4.0/
4.配置elasticsearch环境变量
修改第一台机器es环境变量
进入配置文件目录:
cd /usr/local/elasticsearch-6.4.0/config
编辑文件:
vi elasticsearch.yml
内容配置如下:
cluster.name:elasticsearch #集群名称
node.name:node-1 #节点名称
network.host:192.168.1.100
http.port:9200
discovery.zen.ping.unicast.hosts:["192.168.1.101","192.168.1.102"]
discovery.zen.minimum_master_nodes: 2
修改第二台机器es环境变量
node.name:node-2 #节点名称
network.host: 192.168.1.101
其他不变,保存退出
配置第三台的环境,参照配置配置第二台的步骤
node.name:node-3 #节点名称
network.host: 192.168.1.102
其他不变,保存退出
5.切换至elasticsearch目录,并以elastic用户运行
cd /usr/local/elasticsearch-6.4.0/
su elastic
./bin/elasticsearch
./bin/elasticsearch -d 后台运行es
6.验证成功
查看节点信息
http://192.168.1.100:9200/
7.查看集群状态
http://192.168.1.100:9200/_cluster/health?pretty
8.查看节点列表
http://192.168.1.100:9200/_cat/nodes?v
集群说明,当有多台相同集群名称的ElasticSearch启动后,ElasticSearch会自动去选择将哪台机器作为master,假如在使用过程中,原来选定的master被移除,此时ElasticSearch会重新选择一个节点作为master 。
可能遇到问题
问题一

出现该错误表示内存不够,可以修改config下的jvm.options文件把内存改小。
问题二

解决办法:
切换到root用户修改配置/etc/sysctl.conf
su root
vim /etc/sysctl.conf
加入
vm.max_map_count=655360
然后使其生效
sysctl -p
问题三

文件描述符太低,解决办法:
切换到root用户修改/etc/security/limits.conf
su root
vim /etc/security/limits.conf
加入
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
ES 监控
x-pack 安全防护、监控,6.3后已经集成到es核心
开启试用
POST /_xpack/license/start_trial?acknowledge=true
es开启security
xpack.security.enabled: true
设置内指用户密码
bin/elasticsearch-setup-passwords interactive
配置kibana访问ES
elasticsearch.username: "elastic"
elasticsearch.password: "elastic"
xpack.security.enabled: true
xpack.security.encryptionKey: "4297f44b13955235245b2497399d7a93"
ELK
一、filebeat安装测试
安装:解压后,即可使用
input配置:https://www.elastic.co/guide/en/beats/filebeat/6.5/filebeat-input-log.html
启动:./filebeat -e -c filebeat.yml -d "publish"
递归获取文件:
/var/log/*/*.log #会获取/var/log 下所有 .log 文件
内存控制:
获取某一个文件的harvester的buffer大小
harvester_buffer_size 16384(16kb)
一条消息的最大size:
max_bytes 默认值10MB (10485760)
添加字段:
filebeat.inputs:
- type: log
. . .
fields:
app_id: query_engine_12
fields_under_root: true
多行解析:
#官网地址https://www.elastic.co/guide/en/beats/filebeat/6.5/multiline-examples.html#multiline
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
Output到Logstash:
output.logstash:
hosts:[“192.168.1.137:5044”]
index: customname
负载均衡配置
output.logstash:
hosts: ["es01:5044","es02:5044"]
loadbalance: true
二、logstash安装测试
安装:
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.5.3.zip
unzip logstash-6.5.3.zip
测试:
cd logstash-6.5.3/bin/
./logstash -e 'input { stdin { } } output { stdout {} }'
配置filebeat输入:
https://www.elastic.co/guide/en/logstash/6.5/advanced-pipeline.html
配置ES输出:
https://www.elastic.co/guide/en/logstash/6.5/plugins-outputs-elasticsearch.html
配置日志解析:
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
启动logstash:
bin/logstash -f config/beats2es.conf --config.reload.automatic

 浙公网安备 33010602011771号
浙公网安备 33010602011771号