PTA练习题

L2难度
7-14 集合相似度
给定两个整数集合,它们的相似度定义为:N**c/N**t×100%。其中N**c是两个集合都有的不相等整数的个数,N**t是两个集合一共有的不相等整数的个数。你的任务就是计算任意一对给定集合的相似度。
输入格式:
输入第一行给出一个正整数N(≤50),是集合的个数。随后N行,每行对应一个集合。每个集合首先给出一个正整数M(≤104),是集合中元素的个数;然后跟M个[0,109]区间内的整数。
之后一行给出一个正整数K(≤2000),随后K行,每行对应一对需要计算相似度的集合的编号(集合从1到N编号)。数字间以空格分隔。
输出格式:
对每一对需要计算的集合,在一行中输出它们的相似度,为保留小数点后2位的百分比数字。
输入样例:
3
3 99 87 101
4 87 101 5 87
7 99 101 18 5 135 18 99
2
1 2
1 3
输出样例:
50.00%
33.33%
思路:
- 用STL的容器set来储存集合元素,set自动去重,可以省去判断去重的操作。
- 调用find函数直接查找集合中某个值是否存在,如果存在两集合相同元素就ans加1,即为Nc,那么两集合元素相加减去一个ans即为Nt,最后算答案是记得转换浮点数。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <set>
using namespace std;
const int N = 55;
int n, m, k;
set<int> a[N];
int main()
{
scanf("%d", &n);
for(int i = 1; i <= n; i ++ )
{
scanf("%d", &m);
while(m -- )
{
int x;
scanf("%d", &x);
a[i].insert(x);
}
}
scanf("%d", &k);
while(k -- )
{
int ans = 0;
int x, y;
scanf("%d%d", &x, &y);
// 遍历STL容器的一种方法
// for(auto it = a[x].begin(); it != a[x].end(); it ++ )
for(auto it : a[x])
{
if(a[y].find(it) != a[y].end())
ans ++;
}
double res = 100.0 * ans / (a[x].size() + a[y].size() - ans);
printf("%.2lf%\n", res);
}
return 0;
}
7-20悄悄关注
新浪微博上有个“悄悄关注”,一个用户悄悄关注的人,不出现在这个用户的关注列表上,但系统会推送其悄悄关注的人发表的微博给该用户。现在我们来做一回网络侦探,根据某人的关注列表和其对其他用户的点赞情况,扒出有可能被其悄悄关注的人。
输入格式:
输入首先在第一行给出某用户的关注列表,格式如下:
人数N 用户1 用户2 …… 用户N
其中N是不超过5000的正整数,每个用户i(i=1, ..., N)是被其关注的用户的ID,是长度为4位的由数字和英文字母组成的字符串,各项间以空格分隔。
之后给出该用户点赞的信息:首先给出一个不超过10000的正整数M,随后M行,每行给出一个被其点赞的用户ID和对该用户的点赞次数(不超过1000),以空格分隔。注意:用户ID是一个用户的唯一身份标识。题目保证在关注列表中没有重复用户,在点赞信息中也没有重复用户。
输出格式:
我们认为被该用户点赞次数大于其点赞平均数、且不在其关注列表上的人,很可能是其悄悄关注的人。根据这个假设,请你按用户ID字母序的升序输出可能是其悄悄关注的人,每行1个ID。如果其实并没有这样的人,则输出“Bing Mei You”。
输入样例1:
10 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao
8
Magi 50
Pota 30
LLao 3
Ammy 48
Dave 15
GAO3 31
Zoro 1
Cath 60
输出样例1:
Ammy
Cath
Pota
输入样例2:
11 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao Pota
7
Magi 50
Pota 30
LLao 48
Ammy 3
Dave 15
GAO3 31
Zoro 29
输出样例2:
Bing Mei You
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <set>
#include <map>
#include <vector>
using namespace std;
const int N = 5010, M = 10010;
int n, m;
set<string> gz;
map<string, int> dz;
vector<string> res;
int main()
{
scanf("%d", &n);
for(int i = 1; i <= n; i ++ )
{
string s;
cin >> s;
gz.insert(s);
}
scanf("%d", &m);
int sum = 0;
for(int i = 1; i <= m; i ++ )
{
string s;
int t;
cin >> s >> t;
sum += t;
dz.insert({s, t});
}
float avg = 1.0 * sum / m;
for(auto k : dz)
{
string s = k.first;
int t = k.second;
if(t > avg)
if(gz.find(s) == gz.end())
res.push_back(s);
}
if(res.empty())
{
cout << "Bing Mei You";
}
else
{
int flag = 1;
sort(res.begin(), res.end());
for(int i = 0; i < res.size(); i ++ )
{
if(flag)
cout << res[i], flag = 0;
else
cout << endl << res[i];
}
}
return 0;
}
7-21
7-22 重排链表
给定一个单链表 L1→L2→⋯→L**n−1→L**n,请编写程序将链表重新排列为 L**n→L1→L**n−1→L2→⋯。例如:给定L为1→2→3→4→5→6,则输出应该为6→1→5→2→4→3。
输入格式:
每个输入包含1个测试用例。每个测试用例第1行给出第1个结点的地址和结点总个数,即正整数N (≤105)。结点的地址是5位非负整数,NULL地址用−1表示。
接下来有N行,每行格式为:
Address Data Next
其中Address是结点地址;Data是该结点保存的数据,为不超过105的正整数;Next是下一结点的地址。题目保证给出的链表上至少有两个结点。
输出格式:
对每个测试用例,顺序输出重排后的结果链表,其上每个结点占一行,格式与输入相同。
输入样例:
00100 6
00000 4 99999
00100 1 12309
68237 6 -1
33218 3 00000
99999 5 68237
12309 2 33218
输出样例:
68237 6 00100
00100 1 99999
99999 5 12309
12309 2 00000
00000 4 33218
33218 3 -1
思路:
- 用结构体储存链表的值和下一个的地址,用数组下标来表示地址。
- 先把原顺序链表找出按地址值储存在数组中。
- 再按题目要求将重排后的链表地址的值储存在数组中。
- 按题目要求输出答案即可,记得处理最后一个结点的next值为-1。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010;
struct Node
{
int data;
int next;
}p[N];
int head, n;
int add1[N], add2[N];
int main()
{
scanf("%d%d", &head, &n);
for(int i = 0; i < n; i ++ )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
p[a].data = b;
p[a].next = c;
}
// 处理顺序链表
int k = 0;
while(head != -1)
{
add1[k ++] = head;
head = p[head].next;
}
// 有效地址的个数 t
int t = k;
k = 0;
// 重排链表地址
for(int i = 0, j = t - 1; i <= j; i ++, j -- )
{
if(i != j)
{
add2[k ++] = add1[j];
add2[k ++] = add1[i];
}
else
add2[k ++] = add1[i];
}
// 处理输出
for(int i = 0; i < k - 1; i ++ )
{
if(!i)
printf("%05d %d %05d", add2[i], p[add2[i]].data, add2[i + 1]);
else
printf("\n%05d %d %05d", add2[i], p[add2[i]].data, add2[i + 1]);
}
printf("\n%05d %d -1", add2[k - 1], p[add2[k - 1]].data);
return 0;
}
7-23图着色问题
图着色问题是一个著名的NP完全问题。给定无向图G=(V,E),问可否用K种颜色为V中的每一个顶点分配一种颜色,使得不会有两个相邻顶点具有同一种颜色?
但本题并不是要你解决这个着色问题,而是对给定的一种颜色分配,请你判断这是否是图着色问题的一个解。
输入格式:
输入在第一行给出3个整数V(0<V≤500)、E(≥0)和K(0<K≤V),分别是无向图的顶点数、边数、以及颜色数。顶点和颜色都从1到V编号。随后E行,每行给出一条边的两个端点的编号。在图的信息给出之后,给出了一个正整数N(≤20),是待检查的颜色分配方案的个数。随后N行,每行顺次给出V个顶点的颜色(第i个数字表示第i个顶点的颜色),数字间以空格分隔。题目保证给定的无向图是合法的(即不存在自回路和重边)。
输出格式:
对每种颜色分配方案,如果是图着色问题的一个解则输出Yes,否则输出No,每句占一行。
输入样例:
6 8 3
2 1
1 3
4 6
2 5
2 4
5 4
5 6
3 6
4
1 2 3 3 1 2
4 5 6 6 4 5
1 2 3 4 5 6
2 3 4 2 3 4
输出样例:
Yes
Yes
No
No
思路:
-
邻接矩阵储存边,用BFS遍历每个结点相连的点,如果相连则比较一下起点和终点的颜色是否相同,如果相同则不是合法答案。
-
有一个点就是会去卡颜色个数,我用set去储存所有颜色的值,再用size()函数得到颜色个数,如果不等于k则不合法。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <set>
using namespace std;
const int N = 1010;
int n, m, k, T;
int g[N][N];
int h[N];
int main()
{
scanf("%d%d%d", &n, &m, &k);
while(m -- )
{
int a, b;
scanf("%d%d", &a, &b);
g[a][b] = 1;
g[b][a] = 1;
}
scanf("%d", &T);
while(T -- )
{
set<int> se;
int res = 0;
for(int i = 1; i <= n; i ++ )
{
int x;
scanf("%d", &x);
h[i] = x;
se.insert(x);
}
if(se.size() == k) res = 1;
for(int i = 1; i <= n; i ++ )
{
for(int j = 1; j <= n; j ++ )
{
if(g[i][j])
{
if(h[i] == h[j])
res = 0;
}
}
}
if(res) printf("Yes\n");
else printf("No\n");
}
return 0;
}
7-24月饼
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注意:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
输入格式:
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
输出格式:
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
输入样例:
3 20
18 15 10
75 72 45
输出样例:
94.50
思路:
- 有点类似背包问题。
- 贪心,维护一个月饼单价的数组,然后按照月饼单价去排序,再贪心的去按照市场需求去选择贵的。
- 如果当前市场需求大于最贵的库存,直接加入答案,再减去v[i]。
- 如果当前市场需求小于最贵的库存,用除法去取出剩余量的月饼,并把答案加上这些月饼的收益。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010;
int n, m;
double v[N], w[N], a[N];
void quick_sort(int l, int r)
{
if(l >= r) return;
int i = l - 1, j = r + 1;
double x = a[(l + r) / 2];
while(i < j)
{
do i ++; while(a[i] > x);
do j --; while(a[j] < x);
if(i < j)
{
swap(a[i], a[j]);
swap(v[i], v[j]);
swap(w[i], w[j]);
}
}
quick_sort(l, j);
quick_sort(j + 1, r);
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i ++ )
scanf("%lf", &v[i]);
for(int i = 1; i <= n; i ++ )
{
scanf("%lf", &w[i]);
a[i] = w[i] / v[i];
}
quick_sort(1, n);
double res = 0;
for(int i = 1; i <= n; i ++ )
{
if(m >= v[i])
{
res += w[i];
m -= v[i];
}
else
{
res += (w[i] * m / v[i]);
m -= v[i];
break;
}
}
printf("%.2lf\n", res);
return 0;
}
7-25小字辈
本题给定一个庞大家族的家谱,要请你给出最小一辈的名单。
输入格式:
输入在第一行给出家族人口总数 N(不超过 100 000 的正整数) —— 简单起见,我们把家族成员从 1 到 N 编号。随后第二行给出 N 个编号,其中第 i 个编号对应第 i 位成员的父/母。家谱中辈分最高的老祖宗对应的父/母编号为 -1。一行中的数字间以空格分隔。
输出格式:
首先输出最小的辈分(老祖宗的辈分为 1,以下逐级递增)。然后在第二行按递增顺序输出辈分最小的成员的编号。编号间以一个空格分隔,行首尾不得有多余空格。
输入样例:
9
2 6 5 5 -1 5 6 4 7
输出样例:
4
1 9
思路:
- 有点像并查集,去查找祖宗结点顺便把辈分储存。
- 遍历每个点一遍,去看他的辈分,维护一个最小辈分。
- 遍历第二遍,把每一个辈分和最小辈分相同的点输出。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010;
int n;
// p储存每个点的父结点,b储存每个点的辈分。
int p[N], b[N];
// 找到辈分,并返回。
int f(int x)
{
if(p[x] == -1)
{
b[x] = 1;
return b[x];
}
// 如果辈分不存在,返回它父亲结点的辈分并加一,如果存在直接返回。
if(b[x] == 0)
{
b[x] = f(p[x]) + 1;
return b[x];
}
else return b[x];
}
int main()
{
memset(b, 0, sizeof b);
scanf("%d", &n);
for(int i = 1;i <= n; i ++ )
scanf("%d", &p[i]);
int mb = 1;
for(int i = 1; i <= n; i ++ )
{
int m = f(i);
mb = max(mb, m);
}
printf("%d\n", mb);
int flag = 0;
for(int i = 1; i <= n; i ++ )
{
if(b[i] == mb)
{
if(flag) printf(" ");
flag = 1;
printf("%d", i);
}
}
printf("\n");
return 0;
}
7-26名人堂与代金券
对于在中国大学MOOC(http://www.icourse163.org/ )学习“数据结构”课程的学生,想要获得一张合格证书,总评成绩必须达到 60 分及以上,并且有另加福利:总评分在 [G, 100] 区间内者,可以得到 50 元 PAT 代金券;在 [60, G) 区间内者,可以得到 20 元PAT代金券。全国考点通用,一年有效。同时任课老师还会把总评成绩前 K 名的学生列入课程“名人堂”。本题就请你编写程序,帮助老师列出名人堂的学生,并统计一共发出了面值多少元的 PAT 代金券。
输入格式:
输入在第一行给出 3 个整数,分别是 N(不超过 10 000 的正整数,为学生总数)、G(在 (60,100) 区间内的整数,为题面中描述的代金券等级分界线)、K(不超过 100 且不超过 N 的正整数,为进入名人堂的最低名次)。接下来 N 行,每行给出一位学生的账号(长度不超过15位、不带空格的字符串)和总评成绩(区间 [0, 100] 内的整数),其间以空格分隔。题目保证没有重复的账号。
输出格式:
首先在一行中输出发出的 PAT 代金券的总面值。然后按总评成绩非升序输出进入名人堂的学生的名次、账号和成绩,其间以 1 个空格分隔。需要注意的是:成绩相同的学生享有并列的排名,排名并列时,按账号的字母序升序输出。
输入样例:
10 80 5
cy@zju.edu.cn 78
cy@pat-edu.com 87
1001@qq.com 65
uh-oh@163.com 96
test@126.com 39
anyone@qq.com 87
zoe@mit.edu 80
jack@ucla.edu 88
bob@cmu.edu 80
ken@163.com 70
输出样例:
360
1 uh-oh@163.com 96
2 jack@ucla.edu 88
3 anyone@qq.com 87
3 cy@pat-edu.com 87
5 bob@cmu.edu 80
5 zoe@mit.edu 80
思路:
- 排序。
- 代金券的支出可以在读入数据时判断,如果在区间内直接加上相应的就好。
- 注意的是账号和成绩是同步排序的,如果成绩相同按照账号升序排列。
- 输出时注意的是名次的处理。
AC代码:
O(n^2)这个提交超时了一个测试点。
#include <iostream>
#include <algorithm>
#include <cstring>
#include <string>
using namespace std;
const int N = 10010;
int n, m, k;
int grade[N];
char id[N][20];
void mysort()
{
for(int i = 1; i <= n - 1; i ++ )
{
for(int j = 1; j <= n - i; j ++ )
{
if(grade[j] < grade[j + 1])
{
swap(grade[j], grade[j + 1]);
swap(id[j], id[j + 1]);
}
else if(grade[j] == grade[j + 1])
{
if(strcmp(id[j], id[j + 1]) > 0)
{
swap(grade[j], grade[j + 1]);
swap(id[j], id[j + 1]);
}
}
}
}
}
int main()
{
int res = 0;
scanf("%d%d%d", &n, &m, &k);
for(int i = 1; i <= n; i ++ )
{
scanf("%s%d", id[i], &grade[i]);
if(grade[i] >= m)
res += 50;
else if(grade[i] >= 60)
res += 20;
}
mysort();
// 处理名次
for(int i = k; i <= n; i ++ )
{
if(grade[i] == grade[i + 1])
k ++;
else
break;
}
// 答案输出
printf("%d\n", res);
if(k > 0)
{
int t = 1;
printf("%d %s %d\n", t, id[t], grade[t]);
for(int i = 2; i <= k; i ++ )
{
if(grade[i] == grade[t])
{
printf("%d %s %d\n", t, id[i], grade[i]);
}
else
{
t = i;
printf("%d %s %d\n", t, id[i], grade[i]);
}
}
}
return 0;
}
用结构体和sort排序优化时间,不过结构体排序需要重载小于号或者手写cmp函数。
参考文章:https://www.cnblogs.com/junbaobei/p/10776066.html
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 10010;
struct grade
{
char id[20];
int g;
}p[N];
int n, m, k;
int res = 0;
bool cmp(grade a, grade b)
{
if(a.g == b.g)
{
return strcmp(a.id, b.id) < 0;
return a.g > b.g;
}
else
{
return a.g > b.g;
}
}
int main()
{
scanf("%d%d%d", &n, &m, &k);
for(int i = 1; i <= n; i ++ )
{
scanf("%s%d", &p[i].id, &p[i].g);
if(p[i].g >= m) res += 50;
else if(p[i].g >= 60)
res += 20;
}
sort(p + 1, p + 1 + n, cmp);
// 处理名次
for(int i = k; i <= n; i ++ )
{
if(p[i].g == p[i + 1].g)
k ++;
else break;
}
// 答案输出
printf("%d\n", res);
if(k > 0)
{
int t = 1;
printf("%d %s %d\n", t, p[t].id, p[t].g);
for(int i = 2; i <= k; i ++ )
{
if(p[i].g == p[t].g)
{
printf("%d %s %d\n", t, p[i].id, p[i].g);
}
else
{
t = i;
printf("%d %s %d\n", t, p[i].id, p[i].g);
}
}
}
return 0;
}
7-27 用扑克牌计算24点
一副扑克牌的每张牌表示一个数(J、Q、K 分别表示 11、12、13,两个司令都表示 6)。任取4 张牌,即得到 4 个 1~13 的数,请添加运算符(规定为加+ 减- 乘* 除/ 四种)使之成为一个运算式。每个数只能参与一次运算,4 个数顺序可以任意组合,4 个运算符任意取 3 个且可以重复取。运算遵从一定优先级别,可加括号控制,最终使运算结果为 24。请输出一种解决方案的表达式,用括号表示运算优先。如果没有一种解决方案,则输出 -1 表示无解。
输入格式:
输入在一行中给出 4 个整数,每个整数取值在 [1, 13]。
输出格式:
输出任一种解决方案的表达式,用括号表示运算优先。如果没有解决方案,请输出 -1。
输入样例:
2 3 12 12
输出样例:
((3-2)*12)+12
思路:
- 由题目可知数字有4个,符号4选3,括号有两对。
- 可以看出括号组合只有5种情况,可以列出来,然后暴力枚举数字和符号的组合,判断运算值是否为24
-
- ((a op b) op c) op d;
- (a op (b op c)) op d;
- a op ((b op c) op d);
- a op (b op (c op d));
- (a op b) op (c op d);
- ((a op b) op c) op d;
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 10;
int p[N];
char op[] = {'+', '-', '*', '/'};
float fun(float a, float b, char op)
{
if(op == '+')
return a + b;
else if(op == '-')
return a - b;
else if(op == '*')
return a * b;
else
return a / b;
}
float f1(float a, float b, float c, float d, char op1, char op2, char op3)
{
// ((a + b) + c) + d
float x, y, z;
x = fun(a, b, op1);
y = fun(x, c, op2);
z = fun(y, d ,op3);
return z;
}
float f2(float a, float b, float c, float d, char op1, char op2, char op3)
{
// (a + (b + c)) + d
float x, y, z;
x = fun(b, c, op2);
y = fun(a, x, op1);
z = fun(y, d ,op3);
return z;
}
float f3(float a, float b, float c, float d, char op1, char op2, char op3)
{
// a + ((b + c) + d)
float x, y, z;
x = fun(b, c, op2);
y = fun(x, d, op3);
z = fun(a, y, op1);
return z;
}
float f4(float a, float b, float c, float d, char op1, char op2, char op3)
{
// a + (b + (c + d))
float x, y, z;
x = fun(c, d, op3);
y = fun(b, x, op2);
z = fun(a, y, op1);
return z;
}
float f5(float a, float b, float c, float d, char op1, char op2, char op3)
{
// (a + b) + (c + d)
float x, y, z;
x = fun(a, b, op1);
y = fun(c, d, op3);
z = fun(x, y, op2);
return z;
}
// 遍历符号组合
int cal(int a, int b, int c, int d)
{
int flag = 0;
for(int i = 0; i < 4; i ++ )
{
for(int j = 0; j < 4; j ++ )
{
for(int k = 0; k < 4; k ++ )
{
if(f1(a, b, c, d, op[i], op[j], op[k]) == 24)
{
printf("((%d%c%d)%c%d)%c%d\n", a, op[i], b, op[j], c, op[k], d);
flag = 1;
break;
}
if(f2(a, b, c, d, op[i], op[j], op[k]) == 24)
{
printf("(%d%c(%d%c%d))%c%d\n", a, op[i], b, op[j], c, op[k], d);
flag = 1;
break;
}
if(f3(a, b, c, d, op[i], op[j], op[k]) == 24)
{
printf("%d%c((%d%c%d)%c%d)\n", a, op[i], b, op[j], c, op[k], d);
flag = 1;
break;
}
if(f4(a, b, c, d, op[i], op[j], op[k]) == 24)
{
printf("%d%c(%d%c(%d%c%d))\n", a, op[i], b, op[j], c, op[k], d);
flag = 1;
break;
}
if(f5(a, b, c, d, op[i], op[j], op[k]) == 24)
{
printf("(%d%c%d)%c(%d%c%d)\n", a, op[i], b, op[j], c, op[k], d);
flag = 1;
break;
}
}
if(flag) break;
}
if(flag) break;
}
if(flag) return 1;
return 0;
}
int main()
{
scanf("%d%d%d%d", &p[0], &p[1], &p[2], &p[3]);
// 遍历数字组合
int flag = 0;
for(int i = 0; i < 4; i ++ )
{
for(int j = 0; j < 4; j ++ )
{
if(i == j) continue;
for(int k = 0; k < 4; k ++ )
{
if(i == k || j == k) continue;
for(int t = 0; t < 4; t ++ )
{
if(i == t || j == t || k == t) continue;
int a, b, c, d;
a = p[i], b = p[j], c = p[k], d = p[t];
flag = cal(a, b, c, d);
if(flag) return 0;
}
}
}
}
if(!flag) printf("-1\n");
return 0;
}
7-28 单身狗
“单身狗”是中文对于单身人士的一种爱称。本题请你从上万人的大型派对中找出落单的客人,以便给予特殊关爱。
输入格式:
输入第一行给出一个正整数 N(≤50000),是已知夫妻/伴侣的对数;随后 N 行,每行给出一对夫妻/伴侣——为方便起见,每人对应一个 ID 号,为 5 位数字(从 00000 到 99999),ID 间以空格分隔;之后给出一个正整数 M(≤10000),为参加派对的总人数;随后一行给出这 M 位客人的 ID,以空格分隔。题目保证无人重婚或脚踩两条船。
输出格式:
首先第一行输出落单客人的总人数;随后第二行按 ID 递增顺序列出落单的客人。ID 间用 1 个空格分隔,行的首尾不得有多余空格。
输入样例:
3
11111 22222
33333 44444
55555 66666
7
55555 44444 10000 88888 22222 11111 23333
输出样例:
5
10000 23333 44444 55555 88888
思路:
- 刚看到还以为就是看客人中谁没伴侣,写完以后一试,样例没过,才发现是题目看错了。要找的是客人中有没有和伴侣一起来的人。
- 每个人的ID可以用数组下标来表示,然后用 f 数组来储存每个人的伴侣。
- 输入时用 a 数组储存每个人出现的次数,如果有伴侣则同时把伴侣的次数加1。
- 最后再次遍历一遍客人,看出现次数不为 2 的就是没有带伴侣的人。
- 用 vector 储存答案,排序输出即可。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N = 100010;
int n, m;
// f储存情侣, p储存客人,
int f[N], p[N], a[N];
vector<int> dogs;
int main()
{
scanf("%d", &n);
for(int i =0; i < n; i ++ )
{
int a, b;
scanf("%d%d", &a, &b);
f[a] = b;
f[b] = a;
}
scanf("%d", &m);
for(int i = 0; i < m; i ++ )
{
int x;
scanf("%d", &x);
p[i] = x;
a[x] ++;
a[f[x]] ++;
}
for(int i = 0; i < m; i ++ )
{
if(a[p[i]] != 2)
dogs.push_back(p[i]);
}
sort(dogs.begin(), dogs.end());
// 答案输出
int flag = 0;
printf("%d\n", dogs.size());
for(int i = 0; i < dogs.size(); i ++ )
{
if(flag) printf(" ");
flag = 1;
printf("%05d", dogs[i]);
}
return 0;
}
7-29 冰岛人
2018年世界杯,冰岛队因1:1平了强大的阿根廷队而一战成名。好事者发现冰岛人的名字后面似乎都有个“松”(son),于是有网友科普如下:

冰岛人沿用的是维京人古老的父系姓制,孩子的姓等于父亲的名加后缀,如果是儿子就加 sson,女儿则加 sdottir。因为冰岛人口较少,为避免近亲繁衍,本地人交往前先用个 App 查一下两人祖宗若干代有无联系。本题就请你实现这个 App 的功能。
输入格式:
输入首先在第一行给出一个正整数 N(1<N≤105),为当地人口数。随后 N 行,每行给出一个人名,格式为:名 姓(带性别后缀),两个字符串均由不超过 20 个小写的英文字母组成。维京人后裔是可以通过姓的后缀判断其性别的,其他人则是在姓的后面加 m 表示男性、f 表示女性。题目保证给出的每个维京家族的起源人都是男性。
随后一行给出正整数 M,为查询数量。随后 M 行,每行给出一对人名,格式为:名1 姓1 名2 姓2。注意:这里的姓是不带后缀的。四个字符串均由不超过 20 个小写的英文字母组成。
题目保证不存在两个人是同名的。
输出格式:
对每一个查询,根据结果在一行内显示以下信息:
- 若两人为异性,且五代以内无公共祖先,则输出
Yes; - 若两人为异性,但五代以内(不包括第五代)有公共祖先,则输出
No; - 若两人为同性,则输出
Whatever; - 若有一人不在名单内,则输出
NA。
所谓“五代以内无公共祖先”是指两人的公共祖先(如果存在的话)必须比任何一方的曾祖父辈分高。
输入样例:
15
chris smithm
adam smithm
bob adamsson
jack chrissson
bill chrissson
mike jacksson
steve billsson
tim mikesson
april mikesdottir
eric stevesson
tracy timsdottir
james ericsson
patrick jacksson
robin patricksson
will robinsson
6
tracy tim james eric
will robin tracy tim
april mike steve bill
bob adam eric steve
tracy tim tracy tim
x man april mikes
输出样例:
Yes
No
No
Whatever
Whatever
NA
思路:
- 维京人可以通过姓来判断性别,普通人则需要看最后是m,或者 f。
- 用map来储存每个人的名字,性别,父亲。
- 把性别和父亲储存在一个pair里面。
- 结果输出有三种:不存在、同性、异性。
- 前两种直接可以通过查找名字和性别直接得出,如果是异性,则需要去判断5代之内是否有血缘关系。
- 把每个人的祖先找到,然后遍历5代内的祖先,是否有血缘关系。
-
- 有可能出现的情况包括:A的6代祖先是B的3代祖先。
- A和B的共同祖先在5代之外,不过遍历有可能会超时,所以要判断在超过5代时,然后break。
- 有可能出现的情况包括:A的6代祖先是B的3代祖先。
AC代码:
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
#include <map>
#define x first
#define y second
using namespace std;
typedef pair<char, string> PSS;
int n, m;
map<string, PSS> ma;
vector<string> d1, d2;
int main()
{
// 处理输入
cin >> n;
for(int i = 0; i < n; i ++ )
{
string a, b;
cin >> a >> b;
if(b[b.size() - 1] == 'n')
ma[a] = {'m', b.substr(0, b.size() - 4)};
else if(b[b.size() - 1] == 'r')
ma[a] = {'f', b.substr(0, b.size() - 7)};
else ma[a].x = b[b.size() - 1];
}
// 处理询问
cin >> m;
while(m -- )
{
int flag = 1;
string a1, a2, b1, b2;
cin >> a1 >> a2 >> b1 >> b2;
// 不存在
if(ma.find(a1) == ma.end() || ma.find(b1) == ma.end())
puts("NA");
// 同性
else if(ma[a1].x == ma[b1].x)
puts("Whatever");
// 异性
else
{
string A, B;
A = a1, B = b1;
for(int i = 1; !A.empty(); i ++ )
{
// cout << "i = " << i << endl;
B = b1;
for(int j = 1; !B.empty(); j ++ )
{
// cout << A << ' ' << B << endl;
if(i >= 5 && j >= 5) break;
if(A == B && (i < 5 || j < 5))
{
flag = 0;
break;
}
B = ma[B].y;
}
if(!flag) break;
A = ma[A].y;
}
if(flag) puts("Yes");
else puts("No");
}
}
return 0;
}
7-30 深入虎穴
著名的王牌间谍 007 需要执行一次任务,获取敌方的机密情报。已知情报藏在一个地下迷宫里,迷宫只有一个入口,里面有很多条通路,每条路通向一扇门。每一扇门背后或者是一个房间,或者又有很多条路,同样是每条路通向一扇门…… 他的手里有一张表格,是其他间谍帮他收集到的情报,他们记下了每扇门的编号,以及这扇门背后的每一条通路所到达的门的编号。007 发现不存在两条路通向同一扇门。
内线告诉他,情报就藏在迷宫的最深处。但是这个迷宫太大了,他需要你的帮助 —— 请编程帮他找出距离入口最远的那扇门。
输入格式:
输入首先在一行中给出正整数 N(<105),是门的数量。最后 N 行,第 i 行(1≤i≤N)按以下格式描述编号为 i 的那扇门背后能通向的门:
K D[1] D[2] ... D[K]
其中 K 是通道的数量,其后是每扇门的编号。
输出格式:
在一行中输出距离入口最远的那扇门的编号。题目保证这样的结果是唯一的。
输入样例:
13
3 2 3 4
2 5 6
1 7
1 8
1 9
0
2 11 10
1 13
0
0
1 12
0
0
输出样例:
12
思路:
- 并查集,dfs和bfs应该也可以做。
- 可以看出来的是答案肯定在k = 0 的门里面,用vector储存这些点。
- 定义两个数组,一个用来存这个点到1号点的距离,另一个来存这个点的前一个点,也就是可以通向这个门的门,题目给出不存在两条路通向同一个门。
- 遍历vector里面储存的点,去找他们到1号点的距离,如果大于就直接更新一下最远距离和最远距离的点,最后直接输出答案。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N = 100010;
int n;
int p[N], dist[N];
vector<int> res;
// 向上查找起点
int f(int x)
{
if(dist[x] != -1) return dist[x];
if(x == 1) return 1;
if(!x) return -1;
dist[x] = f(p[x]) + 1;
return dist[x];
}
int main()
{
memset(dist, -1, sizeof dist);
scanf("%d", &n);
for(int i = 1; i <= n; i ++ )
{
int k;
scanf("%d", &k);
if(!k) res.push_back(i);
for(int j = 1; j <= k; j ++ )
{
int x;
scanf("%d", &x);
p[x] = i;
}
}
int mre = 0, mx = 1;
dist[1] = 0;
for(int i = 0; i < res.size(); i ++ )
{
int x = res[i];
dist[x] = f(p[x]);
if(dist[x] > mre)
{
mre = dist[x];
mx = x;
}
}
printf("%d\n", mx);
return 0;
}
7-31 最大子序列之和
题目大意:
给一个序列,求序列的最大子序列之和,并输出最大值为多少、子序列的起点和终点的数。数据范围是10000。
Maximum Subsequence Sum
Given a sequence of K integers { N1, N2, ..., N**K }. A continuous subsequence is defined to be { N**i, N**i+1, ..., N**j } where 1≤i≤j≤K. The Maximum Subsequence is the continuous subsequence which has the largest sum of its elements. For example, given sequence { -2, 11, -4, 13, -5, -2 }, its maximum subsequence is { 11, -4, 13 } with the largest sum being 20.
Now you are supposed to find the largest sum, together with the first and the last numbers of the maximum subsequence.
Input Specification:
Each input file contains one test case. Each case occupies two lines. The first line contains a positive integer K (≤10000). The second line contains K numbers, separated by a space.
Output Specification:
For each test case, output in one line the largest sum, together with the first and the last numbers of the maximum subsequence. The numbers must be separated by one space, but there must be no extra space at the end of a line. In case that the maximum subsequence is not unique, output the one with the smallest indices i and j (as shown by the sample case). If all the K numbers are negative, then its maximum sum is defined to be 0, and you are supposed to output the first and the last numbers of the whole sequence.
Sample Input:
10
-10 1 2 3 4 -5 -23 3 7 -21
Sample Output:
10 1 4
思路:
- 暴力枚举出来所有的子序列,并求和。
- 如果和大于m就更新一下m和右端点。
- 最后直接输出最大值m和左右端点即可。
- 注:有一个点就是左端点的更新,每次循环的时候置t = 1,如果从这个 i 开始的子序列的和大于前面的以后更新一下 L ,然后置 t = 0,在这层循环里当再次更新时只需要更新右端点即可。
- 也可以用动态规划,f[i] 表示以第 i 个数字结尾的子序列的和的最大值。状态转移只有这个数字选和不选,f[i] = max(f[i], a[i]);
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 10010;
int n;
int a[N];
int main()
{
int flag = 1;
scanf("%d", &n);
for(int i = 0; i < n; i ++ )
{
scanf("%d", &a[i]);
if(a[i] >= 0) flag = 0;
}
int l = 0, r = 0, m = -1e9;
int t = 1;
for(int i = 0; i < n; i ++ )
{
int sum = 0;
t = 1;
for(int j = i; j < n; j ++ )
{
sum += a[j];
if(sum > m)
{
if(t)
{
l = i;
t = 0;
}
m = sum;
r = j;
}
}
}
if(flag) printf("0 %d %d\n", a[0], a[n - 1]);
else
{
printf("%d %d %d\n", m, a[l], a[r]);
}
return 0;
}
7-32 链表翻转
题目大意:
给定长度为L 的链表,翻转每K个长度的链表,再输出重排以后的链表。
比如1234567890,K = 4,翻转之后应该为4321876590。
Reversing Linked List
Given a constant K and a singly linked list L, you are supposed to reverse the links of every K elements on L. For example, given L being 1→2→3→4→5→6, if K=3, then you must output 3→2→1→6→5→4; if K=4, you must output 4→3→2→1→5→6.
Input Specification:
Each input file contains one test case. For each case, the first line contains the address of the first node, a positive N (≤105) which is the total number of nodes, and a positive K (≤N) which is the length of the sublist to be reversed. The address of a node is a 5-digit nonnegative integer, and NULL is represented by -1.
Then N lines follow, each describes a node in the format:
Address Data Next
where Address is the position of the node, Data is an integer, and Next is the position of the next node.
Output Specification:
For each case, output the resulting ordered linked list. Each node occupies a line, and is printed in the same format as in the input.
Sample Input:
00100 6 4
00000 4 99999
00100 1 12309
68237 6 -1
33218 3 00000
99999 5 68237
12309 2 33218
Sample Output:
00000 4 33218
33218 3 12309
12309 2 00100
00100 1 99999
99999 5 68237
68237 6 -1
思路:
- 这个题目和 7-22 一样,用数组下标看作地址,储存结点的值和next值。
- 通过next和初始地址找出原链表。
- 按题意翻转链表,输出结果即可,注意最后一个结点的next是- 1。
- 注:有一个卡的点是会出现不在原链表中的点,所以找到原链表后要更新一下需要操作的次数,即 n = cnt。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010;
struct Node
{
int data;
int next;
}p[N];
int add, n, k;
int add1[N], add2[N];
int main()
{
// 处理输入
scanf("%d%d%d", &add, &n, &k);
for(int i = 0; i < n; i ++ )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
p[a].data = b;
p[a].next = c;
}
// 找出原序列
int cnt = 0;
while(add != -1)
{
add1[++ cnt] = add;
add = p[add].next;
}
// 翻转序列
int t = 0, tem = k;
n = cnt; // 在链表上的点的数量
cnt = 0;
while(tem <= n)
{
for(int i = tem; i >= t + 1; i -- )
add2[++ cnt] = add1[i];
t = tem;
tem += k;
}
for(int i = t + 1; i <= n; i ++ )
add2[++ cnt] = add1[i];
// 输出答案
int flag = 0;
for(int i = 1; i < cnt; i ++ )
{
if(flag) printf("\n");
flag = 1;
printf("%05d %d %05d", add2[i], p[add2[i]], add2[i + 1]);
}
if(flag) printf("\n");
printf("%05d %d -1", add2[cnt], p[add2[cnt]]);
return 0;
}
7-33 判断出栈序列
题目大意:
给定一个长度为n的序列按123···n入栈,判断出栈序列是否成立,m是栈的大小,k是询问数量。
Pop Sequence
Given a stack which can keep M numbers at most. Push N numbers in the order of 1, 2, 3, ..., N and pop randomly. You are supposed to tell if a given sequence of numbers is a possible pop sequence of the stack. For example, if M is 5 and N is 7, we can obtain 1, 2, 3, 4, 5, 6, 7 from the stack, but not 3, 2, 1, 7, 5, 6, 4.
Input Specification:
Each input file contains one test case. For each case, the first line contains 3 numbers (all no more than 1000): M (the maximum capacity of the stack), N (the length of push sequence), and K (the number of pop sequences to be checked). Then K lines follow, each contains a pop sequence of N numbers. All the numbers in a line are separated by a space.
Output Specification:
For each pop sequence, print in one line "YES" if it is indeed a possible pop sequence of the stack, or "NO" if not.
Sample Input:
5 7 5
1 2 3 4 5 6 7
3 2 1 7 5 6 4
7 6 5 4 3 2 1
5 6 4 3 7 2 1
1 7 6 5 4 3 2
Sample Output:
YES
NO
NO
YES
NO
思路:
- 用栈去模拟序列入栈出栈。
- 用数组来储存询问的序列,然后按123·····n的顺序依次入栈,每次入栈以后判断栈的大小是否符合,然后判断栈顶元素是否等于数组下标元素,如果等于就弹出栈顶再把下标加一,最后判断栈是否为空,不为空,则不是正确的序列。
AC代码:
#include <iostream>
#include <algorithm>
#include <stack>
using namespace std;
const int N = 1010;
int n, m, k;
int a[N];
int main()
{
scanf("%d%d%d", &m, &n, &k);
while(k -- )
{
stack<int> stk;
int j = 1, flag = 1;
for(int i = 1; i <= n; i ++ )
scanf("%d", &a[i]);
for(int i = 1; i <= n; i ++ )
{
stk.push(i);
// 判断栈的大小
if(stk.size() > m)
{
flag = 0;
break;
}
// 判断是否出栈
if(!stk.empty())
{
while(!stk.empty())
{
if(a[j] == stk.top())
{
stk.pop();
j ++;
}
else break;
}
}
}
// 判断栈是否为空
if(!stk.empty()) flag = 0;
if(flag) puts("YES");
else puts("NO");
}
return 0;
}
7-34 树的同构
给定两棵树T1和T2。如果T1可以通过若干次左右孩子互换就变成T2,则我们称两棵树是“同构”的。例如图1给出的两棵树就是同构的,因为我们把其中一棵树的结点A、B、G的左右孩子互换后,就得到另外一棵树。而图2就不是同构的。
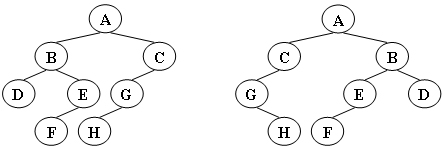 |
|---|
| 图1 |
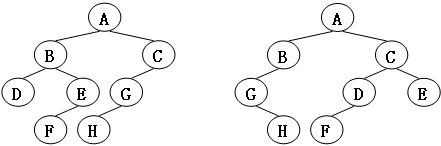 |
| 图2 |
现给定两棵树,请你判断它们是否是同构的。
输入格式:
输入给出2棵二叉树树的信息。对于每棵树,首先在一行中给出一个非负整数N (≤10),即该树的结点数(此时假设结点从0到N−1编号);随后N行,第i行对应编号第i个结点,给出该结点中存储的1个英文大写字母、其左孩子结点的编号、右孩子结点的编号。如果孩子结点为空,则在相应位置上给出“-”。给出的数据间用一个空格分隔。注意:题目保证每个结点中存储的字母是不同的。
输出格式:
如果两棵树是同构的,输出“Yes”,否则输出“No”。
输入样例1(图1):
8
A 1 2
B 3 4
C 5 -
D - -
E 6 -
G 7 -
F - -
H - -
8
G - 4
B 7 6
F - -
A 5 1
H - -
C 0 -
D - -
E 2 -
输出样例1:
Yes
输入样例2(图2):
8
B 5 7
F - -
A 0 3
C 6 -
H - -
D - -
G 4 -
E 1 -
8
D 6 -
B 5 -
E - -
H - -
C 0 2
G - 3
F - -
A 1 4
输出样例2:
No
思路:
- 用结构体储存树的结点,维护一个p数组去判断树是否是合法的树,并返回树根的结点编号。
- 递归处理去判断树是否同构:
-
- 1、两个数都不存在即根节点编号为-1,肯定是同构的。
- 2、一个存在一个不存在,不同构。
- 3、两个根节点的值不一样,不同构。
- 4、如果结点值相同:
- - 1、左子树如果都不存在,返回右子树是否同构。
- 2、左子树存在并且左两个左子树值相等,判断左子树的左子树和右子树是否同构。
- 3、交叉判断,左子树存在但值不相等,判断(T1的左子树和T2的右子树)和(T2的右子树和T1的左子树)是否同时同构。
- 1、两个数都不存在即根节点编号为-1,肯定是同构的。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 20;
struct Tree
{
char data;
int l;
int r;
}T1[N], T2[N];
int build(Tree T[])
{
int n;
int root = -1, p[N];
memset(p, 0, sizeof p);
scanf("%d", &n);
getchar();
for(int i = 0; i < n; i ++ )
{
char x;
int t = 3;
while(t)
{
scanf("%c", &x);
getchar();
if(t == 3) T[i].data = x;
else if(t == 2)
{
if(x == '-')
T[i].l = -1;
else
{
T[i].l = x - '0';
p[T[i].l] = 1;
}
}
else
{
if(x == '-')
T[i].r = -1;
else
{
T[i].r = x - '0';
p[T[i].r] = 1;
}
}
t --;
}
}
for(int i = 0; i < n; i ++ )
if(!p[i]) return i;
return root;
}
int isSame(int t1, int t2)
{
if(t1 == -1 && t2 == -1) return 1;
if((t1 == -1 && t2 != -1) || (t1 != -1 && t2 == -1)) return 0;
if(T1[t1].data != T2[t2].data) return 0;
if(T1[t1].l == -1 && T2[t2].l == -1)
return isSame(T1[t1].r, T2[t2].r);
if(T1[t1].l != -1 && T2[t2].l != -1 && T1[T1[t1].l].data == T2[T2[t2].l].data)
return (isSame(T1[t1].l, T2[t2].l) && isSame(T1[t1].r, T2[t2].r));
return isSame(T1[t1].l, T2[t2].r) && isSame(T1[t1].r, T2[t2].l);
}
int main()
{
int t1, t2;
t1 = build(T1);
t2 = build(T2);
if(isSame(t1, t2))
puts("Yes");
else
puts("No");
return 0;
}
7-35 输出叶子结点
题目大意:
给定一颗树,按照从上到下从左到右的顺序输出所有的叶子结点,
List Leaves
Given a tree, you are supposed to list all the leaves in the order of top down, and left to right.
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N (≤10) which is the total number of nodes in the tree -- and hence the nodes are numbered from 0 to N−1. Then N lines follow, each corresponds to a node, and gives the indices of the left and right children of the node. If the child does not exist, a "-" will be put at the position. Any pair of children are separated by a space.
Output Specification:
For each test case, print in one line all the leaves' indices in the order of top down, and left to right. There must be exactly one space between any adjacent numbers, and no extra space at the end of the line.
Sample Input:
8
1 -
- -
0 -
2 7
- -
- -
5 -
4 6
Sample Output:
4 1 5
思路:
- 用 p 数组储存结点是否有父结点,然后遍历返回得到树的根节点。
- BFS遍历树,用队列储存结点,每次拿出队头,判断是否为叶子结点,如果是就直接输出,如果不是看左右孩子是否存在,若存在就加入队列。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int N = 20;
struct Tree
{
int data;
int l;
int r;
}T[N];
int n;
int p[N];
queue<int> q;
int main()
{
scanf("%d", &n);
getchar();
for(int i = 0; i < n; i ++ )
{
T[i].data = i;
char xl,xr;
scanf("%c %c", &xl, &xr);
getchar();
if(xl == '-')
T[i].l = -1;
else
{
T[i].l = xl - '0';
p[T[i].l] = 1;
}
if(xr == '-')
T[i].r = -1;
else
{
T[i].r = xr - '0';
p[T[i].r] = 1;
}
}
int root = -1;
for(int i = 0; i < n; i ++ )
if(!p[i]) root = i;
int flag = 0;
q.push(root);
while(!q.empty())
{
int t = q.front();
q.pop();
if(T[t].l == -1 && T[t].r == -1)
{
if(flag) printf(" ");
flag = 1;
printf("%d", t);
}
if(T[t].l != -1)
q.push(T[t].l);
if(T[t].r != -1)
q.push(T[t].r);
}
return 0;
}
7-36 后序遍历
题目大意:
按栈的操作输入弹出遍历一棵树的中序遍历,输出该树的后序遍历。
Tree Traversals Again
An inorder binary tree traversal can be implemented in a non-recursive way with a stack. For example, suppose that when a 6-node binary tree (with the keys numbered from 1 to 6) is traversed, the stack operations are: push(1); push(2); push(3); pop(); pop(); push(4); pop(); pop(); push(5); push(6); pop(); pop(). Then a unique binary tree (shown in Figure 1) can be generated from this sequence of operations. Your task is to give the postorder traversal sequence of this tree.
Figure 1
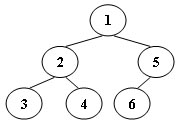
Input Specification:
Each input file contains one test case. For each case, the first line contains a positive integer N (≤30) which is the total number of nodes in a tree (and hence the nodes are numbered from 1 to N). Then 2N lines follow, each describes a stack operation in the format: "Push X" where X is the index of the node being pushed onto the stack; or "Pop" meaning to pop one node from the stack.
Output Specification:
For each test case, print the postorder traversal sequence of the corresponding tree in one line. A solution is guaranteed to exist. All the numbers must be separated by exactly one space, and there must be no extra space at the end of the line.
Sample Input:
6
Push 1
Push 2
Push 3
Pop
Pop
Push 4
Pop
Pop
Push 5
Push 6
Pop
Pop
Sample Output:
3 4 2 6 5 1
思路:
- 刚看到在想怎么构造出原树,后来发现题目的入栈序列是前序遍历,弹出顺序是中序遍历,那么这个题目就转换成了由前序和中序推出后序遍历序列。
- 由前序和中序推后序序列,前序的第一个即为根节点,遍历中序序列找到该点,该点的左边为左子树,右边为右子树,递归处理左右子树再倒序输出。
- 参考:https://blog.csdn.net/qq_44622401/article/details/104064901
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <stack>
using namespace std;
const int N = 40;
int n, cnt1 = 1, cnt2 = 1;
int pre[N], in[N];
stack<int> stk;
int flag = 0;
// 后序序列
void lastprintf(int root, int l, int r)
{
if(l > r) return ;
int i = l;
while(i < r && in[i] != pre[root]) i ++;
// 遍历左子树
lastprintf(root + 1, l, i - 1);
// 遍历右子树
lastprintf(root + 1 + i - l, i + 1, r);
if(flag) printf(" ");
flag = 1;
printf("%d", pre[root]);
}
int main()
{
scanf("%d", &n);
for(int i = 1; i <= 2 * n; i ++ )
{
char s[5];
int x;
scanf("%s", s);
if(strcmp(s,"Push") == 0)
{
scanf("%d", &x);
pre[cnt1 ++] = x;
stk.push(x);
}
else
{
in[cnt2 ++] = stk.top();
stk.pop();
}
}
// 输出后序序列
lastprintf(1, 1, n);
return 0;
}
7-39 堆中的路径
将一系列给定数字插入一个初始为空的小顶堆H[]。随后对任意给定的下标i,打印从H[i]到根结点的路径。
输入格式:
每组测试第1行包含2个正整数N和M(≤1000),分别是插入元素的个数、以及需要打印的路径条数。下一行给出区间[-10000, 10000]内的N个要被插入一个初始为空的小顶堆的整数。最后一行给出M个下标。
输出格式:
对输入中给出的每个下标i,在一行中输出从H[i]到根结点的路径上的数据。数字间以1个空格分隔,行末不得有多余空格。
输入样例:
5 3
46 23 26 24 10
5 4 3
输出样例:
24 23 10
46 23 10
26 10
思路:
-
小根堆:每个结点都小于等于他的左右孩子。
-
大根堆:每个结点都大于等于他的左右孩子。
-
用数组模拟堆进行插入,需要实现两个函数down和up,即该位置的数向上或者向下移动,数组中储存二叉树,x 的左儿子是2 * x ,x 的右儿子是2 * x + 1。
-
小根堆插入一般都在数组最后插入,然后up一下就可以了。
-
构造完成堆以后,查找某点到根节点的路径就是找该点所有父结点,即u / 2。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010;
int n, m, cnt;
int h[N];
void down(int u)
{
int t = u;
if(u * 2 <= cnt && h[u * 2] < h[t]) t = u * 2;
if(u * 2 + 1 <= cnt && h[u * 2 + 1] < h[t]) t = u * 2 + 1;
if(u != t)
{
swap(h[u], h[t]);
down(t);
}
}
void up(int u)
{
while(u / 2 && h[u / 2] > h[u])
{
swap(h[u / 2], h[u]);
up(u / 2);
}
}
// 获取路径
void getpath(int x)
{
while(x / 2)
{
printf("%d ", h[x]);
x /= 2;
}
printf("%d\n", h[x]);
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i ++ )
{
int x;
scanf("%d", &x);
h[++ cnt] = x;
up(cnt);
}
while(m -- )
{
int x;
scanf("%d", &x);
getpath(x);
}
return 0;
}
7-40 并查集
题目大意:
给一些查询和插入操作,如果两个点是连通的就返回yes否者返回no,插入操作是将两个点连接,最后输出有几个独立的集合。
File Transfer
We have a network of computers and a list of bi-directional connections. Each of these connections allows a file transfer from one computer to another. Is it possible to send a file from any computer on the network to any other?
Input Specification:
Each input file contains one test case. For each test case, the first line contains N (2≤N≤104), the total number of computers in a network. Each computer in the network is then represented by a positive integer between 1 and N. Then in the following lines, the input is given in the format:
I c1 c2
where I stands for inputting a connection between c1 and c2; or
C c1 c2
where C stands for checking if it is possible to transfer files between c1 and c2; or
S
where S stands for stopping this case.
Output Specification:
For each C case, print in one line the word "yes" or "no" if it is possible or impossible to transfer files between c1 and c2, respectively. At the end of each case, print in one line "The network is connected." if there is a path between any pair of computers; or "There are k components." where k is the number of connected components in this network.
Sample Input 1:
5
C 3 2
I 3 2
C 1 5
I 4 5
I 2 4
C 3 5
S
Sample Output 1:
no
no
yes
There are 2 components.
Sample Input 2:
5
C 3 2
I 3 2
C 1 5
I 4 5
I 2 4
C 3 5
I 1 3
C 1 5
S
Sample Output 2:
no
no
yes
yes
The network is connected.
思路:
- 并查集,集合的合并和集合间的查询。
- find函数如果当前点不是就继续向上找,同时对路径进行压缩,让每个点都指向他所在集合的代表元素。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <map>
using namespace std;
const int N = 10010;
int n, k, flag = 1;
int p[N];
map<int, int> ma;
int find(int x)
{
if(x != p[x]) p[x] = find(p[x]);
return p[x];
}
int main()
{
scanf("%d", &n);
// 初始化并查集
for(int i = 1; i <= n; i ++ ) p[i] = i;
while(1)
{
char op[2];
int a, b;
scanf("%s", op);
if(*op == 'S') break;
scanf("%d%d", &a, &b);
if(*op == 'I')
{
p[find(b)] = find(a);
}
else
{
if(find(a) == find(b))
puts("yes");
else
puts("no");
}
}
// 寻找独立集合
for(int i = 1; i <= n; i ++ )
{
ma[find(i)] ++;
}
k = ma.size();
if(k == 1) printf("The network is connected.\n");
else
printf("There are %d components.\n", k);
return 0;
}
7-41 列出连通集
给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集。假设顶点从0到N−1编号。进行搜索时,假设我们总是从编号最小的顶点出发,按编号递增的顺序访问邻接点。
输入格式:
输入第1行给出2个整数N(0<N≤10)和E,分别是图的顶点数和边数。随后E行,每行给出一条边的两个端点。每行中的数字之间用1空格分隔。
输出格式:
按照"{ v1 v2 ... v**k }"的格式,每行输出一个连通集。先输出DFS的结果,再输出BFS的结果。
输入样例:
8 6
0 7
0 1
2 0
4 1
2 4
3 5
输出样例:
{ 0 1 4 2 7 }
{ 3 5 }
{ 6 }
{ 0 1 2 7 4 }
{ 3 5 }
{ 6 }
思路:
- 图的DFS和BFS遍历。
- 刚开始我在想还要先去找出每个连通集并记录一下连通集的最小点标号,便于开始遍历。后来发现直接维护一个st数组判断该点是否已经被选过即可,然后直接从0 ~ n-1遍历全部点即可。
- 遍历过程中每次选到该点时直接将st置为1表示该点已经选过。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int N = 20;
int n, m;
int g[N][N];
int st[N];
void dfs(int x)
{
for(int i = 0; i < n; i ++ )
{
if(!st[i] && g[x][i])
{
st[i] = 1;
printf(" %d", i);
dfs(i);
}
}
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 0; i < m; i ++ )
{
int a, b;
scanf("%d%d", &a, &b);
g[a][b] = g[b][a] = 1;
}
// DFS
for(int i = 0; i < n; i ++ )
{
if(!st[i])
{
st[i] = 1;
printf("{ %d", i);
dfs(i);
printf(" }\n");
}
}
// BFS
memset(st, 0, sizeof st);
queue<int> q;
for(int i = 0; i < n; i ++ )
{
if(!st[i])
{
q.push(i);
st[i] = 1;
printf("{");
while(!q.empty())
{
int t = q.front();
q.pop();
for(int j = 0; j < n; j ++ )
{
if(!st[j] && g[t][j])
{
st[j] = 1;
q.push(j);
}
}
printf(" %d", t);
}
printf(" }\n");
}
}
return 0;
}
7-42 DFS
题目大意:
有个100 X 100的正方形,中心点是(0,0),右上角是(50,50),中心有个直径为15的圆形岛,在正方形内给出n个可以踩的点,判断是否可以由中心岛踩某些点而到达岸边。给出每次跳跃的距离。
Saving James Bond - Easy Version
This time let us consider the situation in the movie "Live and Let Die" in which James Bond, the world's most famous spy, was captured by a group of drug dealers. He was sent to a small piece of land at the center of a lake filled with crocodiles. There he performed the most daring action to escape -- he jumped onto the head of the nearest crocodile! Before the animal realized what was happening, James jumped again onto the next big head... Finally he reached the bank before the last crocodile could bite him (actually the stunt man was caught by the big mouth and barely escaped with his extra thick boot).
Assume that the lake is a 100 by 100 square one. Assume that the center of the lake is at (0,0) and the northeast corner at (50,50). The central island is a disk centered at (0,0) with the diameter of 15. A number of crocodiles are in the lake at various positions. Given the coordinates of each crocodile and the distance that James could jump, you must tell him whether or not he can escape.
Input Specification:
Each input file contains one test case. Each case starts with a line containing two positive integers N (≤100), the number of crocodiles, and D, the maximum distance that James could jump. Then N lines follow, each containing the (x,y) location of a crocodile. Note that no two crocodiles are staying at the same position.
Output Specification:
For each test case, print in a line "Yes" if James can escape, or "No" if not.
Sample Input 1:
14 20
25 -15
-25 28
8 49
29 15
-35 -2
5 28
27 -29
-8 -28
-20 -35
-25 -20
-13 29
-30 15
-35 40
12 12
Sample Output 1:
Yes
Sample Input 2:
4 13
-12 12
12 12
-12 -12
12 -12
Sample Output 2:
No
思路:
- 题目没让输出路径,所以可以直接遍历每个点,去DFS遍历每个可以由该点跳跃到的点,每次判断一下是否可以由该点到达岸边。
- 两点之间的距离公式:(x1 - x2) ^ 2 + (y1 - y2) ^ 2 = r ^ 2。
- 注意中心点是个直径为15的岛,所以从中心岛跳出时需要特判一下距离。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 110;
struct point
{
int x;
int y;
}p[N];
int n, m, flag = 0;
int st[N];
// 判断是否有点可以从中心岛跳过去
int f1(int x)
{
int dx = p[x].x * p[x].x;
int dy = p[x].y * p[x].y;
int r = (m + 7.5) * (m + 7.5);
if(dx + dy <= r) return 1;
else return 0;
}
// 判断是否可以由x,跳到y上
int distance(int x, int y)
{
int dx = (p[x].x - p[y].x) * (p[x].x - p[y].x);
int dy = (p[x].y - p[y].y) * (p[x].y - p[y].y);
int r = m * m;
if(dx + dy <= r) return 1;
return 0;
}
// 判断是否可以由x这个点跳到岸上
int judge(int x)
{
if(p[x].x - m <= -50 || p[x].x + m >= 50 || p[x].y - m <= -50 || p[x].y + m >= 50)
return 1;
return 0;
}
void dfs(int x)
{
st[x] = 1;
if(judge(x)) flag = 1;
else
for(int i = 1; i <= n; i ++ )
if(!st[i] && distance(x, i))
dfs(i);
return;
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i ++ )
scanf("%d%d", &p[i].x, &p[i].y);
if(m >= 42.5) puts("Yes");
else
for(int i = 1; i <= n; i ++ )
if(!st[i] && f1(i))
dfs(i);
if(flag) puts("Yes");
else puts("No");
return 0;
}
7-43 哈利·波特的考试
哈利·波特要考试了,他需要你的帮助。这门课学的是用魔咒将一种动物变成另一种动物的本事。例如将猫变成老鼠的魔咒是haha,将老鼠变成鱼的魔咒是hehe等等。反方向变化的魔咒就是简单地将原来的魔咒倒过来念,例如ahah可以将老鼠变成猫。另外,如果想把猫变成鱼,可以通过念一个直接魔咒lalala,也可以将猫变老鼠、老鼠变鱼的魔咒连起来念:hahahehe。
现在哈利·波特的手里有一本教材,里面列出了所有的变形魔咒和能变的动物。老师允许他自己带一只动物去考场,要考察他把这只动物变成任意一只指定动物的本事。于是他来问你:带什么动物去可以让最难变的那种动物(即该动物变为哈利·波特自己带去的动物所需要的魔咒最长)需要的魔咒最短?例如:如果只有猫、鼠、鱼,则显然哈利·波特应该带鼠去,因为鼠变成另外两种动物都只需要念4个字符;而如果带猫去,则至少需要念6个字符才能把猫变成鱼;同理,带鱼去也不是最好的选择。
输入格式:
输入说明:输入第1行给出两个正整数N (≤100)和M,其中N是考试涉及的动物总数,M是用于直接变形的魔咒条数。为简单起见,我们将动物按1~N编号。随后M行,每行给出了3个正整数,分别是两种动物的编号、以及它们之间变形需要的魔咒的长度(≤100),数字之间用空格分隔。
输出格式:
输出哈利·波特应该带去考场的动物的编号、以及最长的变形魔咒的长度,中间以空格分隔。如果只带1只动物是不可能完成所有变形要求的,则输出0。如果有若干只动物都可以备选,则输出编号最小的那只。
输入样例:
6 11
3 4 70
1 2 1
5 4 50
2 6 50
5 6 60
1 3 70
4 6 60
3 6 80
5 1 100
2 4 60
5 2 80
输出样例:
4 70
思路:
-
由题目知道两个动物之间可以由咒语互变,可以理解成无向图。
-
多元汇最短路,Floyd算法,因为题目没有说明是从哪个点作为起点,所以用到了Floyd算法,d数组中储存的即为 a 到 b 的最短路。
-
算完以后,找到每一行里面的最大值,再在这些最大值里找到一个最小值即为答案。
-
有个特殊情况是不能到达的某个点,Floyd算完以后,遍历时,如果找到一个距离为INF的值即两点之间不可到达,所以不连通,就输出0。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 110, INF = 1e9;
int n, m;
int d[N][N];
void floyd()
{
for(int k = 1; k <= n; k ++ )
for(int i = 1; i <= n; i ++ )
for(int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
int main()
{
scanf("%d%d", &n, &m);
// 初始化
for(int i = 1; i <= n; i ++ )
for(int j = 1; j <= n; j ++ )
if(i == j) d[i][j] = 0;
else d[i][j] = INF;
for(int i = 1; i <= m; i ++ )
{
int a, b, w;
scanf("%d%d%d", &a, &b, &w);
d[a][b] = d[b][a] = min(d[a][b], w);
}
floyd();
// minnum储存最小的点坐标,maxres储存对应的咒语长度
// flag 对应是否存在不可到达的点
int flag = 0;
int minnum = 1, maxres = INF;
for(int i = 1; i <= n; i ++ )
{
int x = -1;
for(int j = 1; j <= n; j ++ )
{
if(d[i][j] > x)
{
x = d[i][j];
}
}
if(x == INF) flag = 1;
if(maxres > x)
{
maxres = x;
minnum = i;
}
}
if(flag) printf("0");
else
printf("%d %d", minnum, maxres);
return 0;
}
7-44 关键路径
题目大意:
给定一个有向图,第一行n表示点的数量(0 ~ n -1编号)m表示边得数量,然后m行每行给出一条边的起点、终点、权值。求从起点到终点的的最短时间,如果不存在就输出Impossible。
How Long Does It Take
Given the relations of all the activities of a project, you are supposed to find the earliest completion time of the project.
Input Specification:
Each input file contains one test case. Each case starts with a line containing two positive integers N (≤100), the number of activity check points (hence it is assumed that the check points are numbered from 0 to N−1), and M, the number of activities. Then M lines follow, each gives the description of an activity. For the i-th activity, three non-negative numbers are given: S[i], E[i], and L[i], where S[i] is the index of the starting check point, E[i] of the ending check point, and L[i] the lasting time of the activity. The numbers in a line are separated by a space.
Output Specification:
For each test case, if the scheduling is possible, print in a line its earliest completion time; or simply output "Impossible".
Sample Input 1:
9 12
0 1 6
0 2 4
0 3 5
1 4 1
2 4 1
3 5 2
5 4 0
4 6 9
4 7 7
5 7 4
6 8 2
7 8 4
Sample Output 1:
18
Sample Input 2:
4 5
0 1 1
0 2 2
2 1 3
1 3 4
3 2 5
Sample Output 2:
Impossible
思路:
- 关键路径题目,把每个点的入度储存下来,然后从度为0的点开始遍历。
- ET数组储存每个点完成的最早时间,InD数组储存每个点的入度。
- 把度为0的点入队,然后遍历每个跟点相连的点,更新ET值,再把每个跟该点相连的点的入度减一,如果为0就入队。
- 做完以后看ans的值是否和n的值相同,不同则说明图中存在环,输出Impossible,相同就输出最大的res。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int N = 110;
int n, m;
int ET[N], InD[N]; // ET储存每个活动最早完成时间
int g[N][N]; // InD储存每个点的入度
queue<int> q;
int main()
{
scanf("%d%d", &n, &m);
memset(g, -1, sizeof g);
for(int i = 0; i < m; i ++ )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
g[a][b] = c;
InD[b] ++;
}
// 度为 0 的加入队列
for(int i = 0; i < n; i ++ )
if(!InD[i])
q.push(i);
int res = 0, ans = 0;
while(!q.empty())
{
int t = q.front();
q.pop();
ans ++;
// 更新一下每个可以更新的点
for(int i = 0; i < n; i ++ )
{
if(g[t][i] != -1)
{
if(ET[t] + g[t][i] > ET[i])
{
ET[i] = ET[t] + g[t][i];
res = max(res, ET[i]);
}
InD[i] --;
if(!InD[i])
q.push(i);
}
}
}
// ans记录每个点是否加入队列,如果ans不等于n说明存在回路
if(ans != n) puts("Impossible");
else printf("%d\n", res);
return 0;
}
7-45 排序
给定N个(长整型范围内的)整数,要求输出从小到大排序后的结果。
本题旨在测试各种不同的排序算法在各种数据情况下的表现。各组测试数据特点如下:
数据1:只有1个元素;
数据2:11个不相同的整数,测试基本正确性;
数据3:103个随机整数;
数据4:104个随机整数;
数据5:105个随机整数;
数据6:105个顺序整数;
数据7:105个逆序整数;
数据8:105个基本有序的整数;
数据9:105个随机正整数,每个数字不超过1000。
输入格式:
输入第一行给出正整数N(≤105),随后一行给出N个(长整型范围内的)整数,其间以空格分隔。
输出格式:
在一行中输出从小到大排序后的结果,数字间以1个空格分隔,行末不得有多余空格。
输入样例:
11
4 981 10 -17 0 -20 29 50 8 43 -5
输出样例:
-20 -17 -5 0 4 8 10 29 43 50 981
思路:
- 刚看到以为会有坑,后来看完以后发现只是一个排序题目。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long LL;
const int N = 100010;
int n;
LL q[N], temp[N];
void quick_sort(LL q[], int l, int r)
{
if(l >= r) return ;
int i = l - 1, j = r + 1;
LL x = q[(l + r) / 2];
while(i < j)
{
do i ++; while(q[i] < x);
do j --; while(q[j] > x);
if(i < j)
swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
void merge_sort(LL q[], int l, int r)
{
if(l >= r) return ;
int mid = (l + r) / 2;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int i = l, j = mid + 1, k = 0;
while(i <= mid && j <= r)
{
if(q[i] < q[j])
temp[k ++ ] = q[i ++ ];
else
temp[k ++ ] = q[j ++ ];
}
while(i <= mid)
temp[k ++ ] = q[i ++ ];
while(j <= r)
temp[k ++ ] = q[j ++ ];
for(int i = l, j = 0; i <= r;)
q[i ++ ] = temp[j ++ ];
}
int main()
{
scanf("%d", &n);
for(int i = 0; i < n; i ++ )
scanf("%lld", &q[i]);
// 可以直接调用sort函数
// sort(q, q + n);
// 手写快排和归并
// quick_sort(q, 0, n - 1);
merge_sort(q, 0, n - 1);
int flag = 0;
for(int i = 0; i < n; i ++ )
{
if(flag) printf(" ");
flag = 1;
printf("%lld", q[i]);
}
return 0;
}
7-46 插入和归并排序
题目大意:
给定一个序列和一个排序没有完成的该序列的一个状态,判断是插入排序还是归并排序,并输出迭代下一步的序列。
Insert or Merge
According to Wikipedia:
Insertion sort iterates, consuming one input element each repetition, and growing a sorted output list. Each iteration, insertion sort removes one element from the input data, finds the location it belongs within the sorted list, and inserts it there. It repeats until no input elements remain.
Merge sort works as follows: Divide the unsorted list into N sublists, each containing 1 element (a list of 1 element is considered sorted). Then repeatedly merge two adjacent sublists to produce new sorted sublists until there is only 1 sublist remaining.
Now given the initial sequence of integers, together with a sequence which is a result of several iterations of some sorting method, can you tell which sorting method we are using?
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N (≤100). Then in the next line, N integers are given as the initial sequence. The last line contains the partially sorted sequence of the N numbers. It is assumed that the target sequence is always ascending. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print in the first line either "Insertion Sort" or "Merge Sort" to indicate the method used to obtain the partial result. Then run this method for one more iteration and output in the second line the resuling sequence. It is guaranteed that the answer is unique for each test case. All the numbers in a line must be separated by a space, and there must be no extra space at the end of the line.
Sample Input 1:
10
3 1 2 8 7 5 9 4 6 0
1 2 3 7 8 5 9 4 6 0
Sample Output 1:
Insertion Sort
1 2 3 5 7 8 9 4 6 0
Sample Input 2:
10
3 1 2 8 7 5 9 4 0 6
1 3 2 8 5 7 4 9 0 6
Sample Output 2:
Merge Sort
1 2 3 8 4 5 7 9 0 6
思路:
-
a储存原序列,q储存中间状态。
-
插入排序是有序的,那么就可以直接遍历q,找到有序的前面一部分,后面无序的与原数组a比较,如果相同即为插入排序,反之为归并。
-
插入排序直接就把q排好序的一部分往下再排一位即可。
-
归并排序是分治的思想,那么直接枚举长度len从2开始,把a数组按归并排序排,每次比较a和q如果两者相等,即找到,然后再排一次就是答案。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 110;
int n;
int q[N], a[N];
int main()
{
scanf("%d", &n);
for(int i = 0; i < n; i ++ )
scanf("%d", &a[i]);
for(int i = 0; i < n; i ++ )
scanf("%d", &q[i]);
// 判断是否为插入排序
int t, flag = 1;
for(int i = 1; i < n; i ++ )
if(q[i] < q[i - 1])
{
t = i;
break;
}
for(int i = t; i < n; i ++ )
if(q[i] != a[i])
flag = 0;
// 处理下一次迭代
// 插入排序
if(flag)
{
int k = q[t];
sort(q, q + t + 1);
int te = 0;
printf("Insertion Sort\n");
for(int i = 0; i < n; i ++ )
{
if(te) printf(" ");
te = 1;
printf("%d", q[i]);
}
}
// 归并排序
else
{
int len = 2;
int k = 1;
while(k)
{
k = 0;
for(int i = 0; i < n; i ++ )
if(a[i] != q[i])
{
k = 1;
break;
}
for(int i = 0; i < n; i += len)
{
sort(a + i, a + min(i + len, n));
}
len *= 2;
}
int te = 0;
printf("Merge Sort\n");
for(int i = 0; i < n; i ++ )
{
if(te) printf(" ");
te = 1;
printf("%d", a[i]);
}
}
return 0;
}
7-47 插入和堆排序
题目大意:
给定一个序列和一个排序没有完成的该序列的一个状态,判断是插入排序还是堆排序,并输出迭代下一步的序列。
Insertion or Heap Sort
According to Wikipedia:
Insertion sort iterates, consuming one input element each repetition, and growing a sorted output list. Each iteration, insertion sort removes one element from the input data, finds the location it belongs within the sorted list, and inserts it there. It repeats until no input elements remain.
Heap sort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element and moving that to the sorted region. it involves the use of a heap data structure rather than a linear-time search to find the maximum.
Now given the initial sequence of integers, together with a sequence which is a result of several iterations of some sorting method, can you tell which sorting method we are using?
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N (≤100). Then in the next line, N integers are given as the initial sequence. The last line contains the partially sorted sequence of the N numbers. It is assumed that the target sequence is always ascending. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print in the first line either "Insertion Sort" or "Heap Sort" to indicate the method used to obtain the partial result. Then run this method for one more iteration and output in the second line the resulting sequence. It is guaranteed that the answer is unique for each test case. All the numbers in a line must be separated by a space, and there must be no extra space at the end of the line.
Sample Input 1:
10
3 1 2 8 7 5 9 4 6 0
1 2 3 7 8 5 9 4 6 0
Sample Output 1:
Insertion Sort
1 2 3 5 7 8 9 4 6 0
Sample Input 2:
10
3 1 2 8 7 5 9 4 6 0
6 4 5 1 0 3 2 7 8 9
Sample Output 2:
Heap Sort
5 4 3 1 0 2 6 7 8 9
思路:
-
a储存原序列,q储存中间状态。
-
插入排序是有序的,那么就可以直接遍历q,找到有序的前面一部分,后面无序的与原数组a比较,如果相同即为插入排序,反之为堆排序。
-
插入排序直接就把q排好序的一部分往下再排一位即可。
-
堆排序是从后往前的序列,每次把堆顶放到最后,所以可以从后往前找比堆顶(就是a[1])大的就是已经有序的序列,找到第一个不属于有序的元素,让其与h[1]交换,然后再down一下第一个元素。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 110;
int n, ans;
int q[N], a[N];
void down(int u)
{
int t = u;
if(u * 2 <= ans && q[u * 2] > q[t]) t = u * 2;
if(u * 2 + 1 <= ans && q[u * 2 + 1] > q[t]) t = u * 2 + 1;
if(u != t)
{
swap(q[u], q[t]);
down(t);
}
}
void up(int u)
{
while(u / 2)
{
if(q[u] > q[u / 2])
swap(q[u], q[u / 2]);
u /= 2;
}
}
int main()
{
scanf("%d", &n);
for(int i = 1; i <= n; i ++ )
scanf("%d", &a[i]);
for(int i = 1; i <= n; i ++ )
scanf("%d", &q[i]);
// 判断是否为插入排序
int t, flag = 1;
for(int i = 2; i <= n; i ++ )
if(q[i] < q[i - 1])
{
t = i;
break;
}
for(int i = t; i <= n; i ++ )
if(q[i] != a[i])
flag = 0;
// 处理下一次迭代
// 插入排序
if(flag)
{
int k = q[t];
sort(q + 1, q + t + 1);
int te = 0;
printf("Insertion Sort\n");
for(int i = 1; i <= n; i ++ )
{
if(te) printf(" ");
te = 1;
printf("%d", q[i]);
}
}
// 堆排序
else
{
int k = 1;
for(int i = n; i >= 1; i -- )
{
if(q[i] < q[1])
{
k = i;
break;
}
}
ans = k - 1;
swap(q[1], q[k]);
down(1);
int te = 0;
printf("Heap Sort\n");
for(int i = 1; i <= n; i ++ )
{
if(te) printf(" ");
te = 1;
printf("%d", q[i]);
}
}
return 0;
}
7-48 PAT Judge
题目大意:
排序题,给定m次提交,最后按总分、满分题目数、id排名输出。
The ranklist of PAT is generated from the status list, which shows the scores of the submissions. This time you are supposed to generate the ranklist for PAT.
Input Specification:
Each input file contains one test case. For each case, the first line contains 3 positive integers, N (≤104), the total number of users, K (≤5), the total number of problems, and M (≤105), the total number of submissions. It is then assumed that the user id's are 5-digit numbers from 00001 to N, and the problem id's are from 1 to K. The next line contains K positive integers p[i] (i=1, ..., K), where p[i] corresponds to the full mark of the i-th problem. Then M lines follow, each gives the information of a submission in the following format:
user_id problem_id partial_score_obtained
where partial_score_obtained is either −1 if the submission cannot even pass the compiler, or is an integer in the range [0, p[problem_id]]. All the numbers in a line are separated by a space.
Output Specification:
For each test case, you are supposed to output the ranklist in the following format:
rank user_id total_score s[1] ... s[K]
where rank is calculated according to the total_score, and all the users with the same total_score obtain the same rank; and s[i] is the partial score obtained for the i-th problem. If a user has never submitted a solution for a problem, then "-" must be printed at the corresponding position. If a user has submitted several solutions to solve one problem, then the highest score will be counted.
The ranklist must be printed in non-decreasing order of the ranks. For those who have the same rank, users must be sorted in nonincreasing order according to the number of perfectly solved problems. And if there is still a tie, then they must be printed in increasing order of their id's. For those who has never submitted any solution that can pass the compiler, or has never submitted any solution, they must NOT be shown on the ranklist. It is guaranteed that at least one user can be shown on the ranklist.
Sample Input:
7 4 20
20 25 25 30
00002 2 12
00007 4 17
00005 1 19
00007 2 25
00005 1 20
00002 2 2
00005 1 15
00001 1 18
00004 3 25
00002 2 25
00005 3 22
00006 4 -1
00001 2 18
00002 1 20
00004 1 15
00002 4 18
00001 3 4
00001 4 2
00005 2 -1
00004 2 0
Sample Output:
1 00002 63 20 25 - 18
2 00005 42 20 0 22 -
2 00007 42 - 25 - 17
2 00001 42 18 18 4 2
5 00004 40 15 0 25 -
思路:
- 因为题目数量很少所以用一个数组储存下来题目对应的分数,用结构体来储存每个人的id,分数,满分通过的题目数,各个题目对应的分数。
- sort排序要手写cmp函数,总分,满分题目数,id排序。
- 在排序前把每个人的总分计算一下,同时判断一下每个人是否有一次编译也没过的情况。
- 输出时注意名次,重复名次输出是一样的,如果一次都没有编译通过,就不输出该同学的成绩。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 10010;
struct student
{
int id;
int r; // 是否有提交编译过了
int fpass; // 完全正确的通过数
int total_score;
int s[6] = {-2,-2,-2,-2,-2,-2};
} stu[N];
int n, k, m;
int p[6];
bool cmp(student a, student b)
{
if(a.total_score != b.total_score)
return a.total_score > b.total_score;
else
{
if(a.fpass != b.fpass)
return a.fpass > b.fpass;
else
{
return a.id < b.id;
}
}
}
int main()
{
scanf("%d%d%d", &n, &k, &m);
// 读入题目和分数
for(int i = 1; i <= k; i ++ )
scanf("%d", &p[i]);
// 读入提交
for(int i =1; i <= m; i ++ )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
// 满分
if(c == p[b])
{
if(stu[a].s[b] == -2 || stu[a].s[b] == -1)
{
stu[a].s[b] = c;
stu[a].fpass ++;
// stu[a].total_score += c;
}
else if(stu[a].s[b] < c)
{
// stu[a].total_score += (c - stu[a].s[b]);
stu[a].s[b] = c;
stu[a].fpass ++;
}
}
// 编译不过
else if(c == -1)
{
if(stu[a].s[b] == -2)
{
stu[a].s[b] = c;
}
}
// 不是满分
else
{
if(stu[a].s[b] < c)
{
// stu[a].total_score += (c - stu[a].s[b]);
stu[a].s[b] = c;
}
}
}
// 计算总分
for(int i = 1; i <= n; i ++ )
{
int w = 0;
stu[i].id = i;
for(int j = 1; j <= k; j ++ )
{
int t = stu[i].s[j];
if(t == -1 || t == -2)
{
w ++;
continue;
}
else
stu[i].total_score += t;
}
if(w == k) stu[i].r = 1;
}
// 排序
sort(stu + 1, stu + 1 + n, cmp);
// 输出
int cnt = 1, t = 0;
for(int i = 1; i <= n; i ++ )
{
int flag = 0;
if(stu[i].r) continue;
if(t && stu[i].total_score != stu[i - 1].total_score)
cnt = i;
t = 1;
printf("%d %05d %d ", cnt, stu[i].id, stu[i].total_score);
for(int j = 1; j <= k; j ++ )
{
if(flag) printf(" ");
flag = 1;
if(stu[i].s[j] == -1)
printf("0");
else if(stu[i].s[j] == -2)
printf("-");
else
printf("%d", stu[i].s[j]);
}
printf("\n");
}
return 0;
}
7-49 Sort with Swap(0, i)
题目大意:
给定一个长度为N的序列,{0,1,2,·····,N-1}的随机排列,每次只能交换0和一个其他数字,输出让每个数字到对应的位置需要交换几步。
Given any permutation of the numbers {0, 1, 2,..., N−1}, it is easy to sort them in increasing order. But what if Swap(0, *) is the ONLY operation that is allowed to use? For example, to sort {4, 0, 2, 1, 3} we may apply the swap operations in the following way:
Swap(0, 1) => {4, 1, 2, 0, 3}
Swap(0, 3) => {4, 1, 2, 3, 0}
Swap(0, 4) => {0, 1, 2, 3, 4}
Now you are asked to find the minimum number of swaps need to sort the given permutation of the first N nonnegative integers.
Input Specification:
Each input file contains one test case, which gives a positive N (≤105) followed by a permutation sequence of {0, 1, ..., N−1}. All the numbers in a line are separated by a space.
Output Specification:
For each case, simply print in a line the minimum number of swaps need to sort the given permutation.
Sample Input:
10
3 5 7 2 6 4 9 0 8 1
Sample Output:
9
思路:
-
可以看出序列是由一个或多个环组成的,按环交换一遍后可以让对应的元素到相应的位置。
-
以q[0]为哨兵,当环交换以后,如果环包含0那么0必定在q[0]。
-
遍历一遍看每个元素是否在相应的位置上
-
- 如果q[0] != 0,则把环交换一遍。
- 如果交换一遍之后仍然不在相应位置,就把该数与q[0]交换。
- 每次交换数的时候就把答案加1,最后得到的步骤数即为答案。
- 如果q[0] != 0,则把环交换一遍。
-
如果环内包含0,那么交换一遍的步骤为环内元素个数减一;如果不包含0,则需要把0引入最后再交换出去,步骤数为环内元素个数加一。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010;
int n, ans;
int q[N];
void swap_sort()
{
for(int i = 0; i < n; i ++ )
{
if(i != q[i])
{
while(q[0] != 0)
{
swap(q[0], q[q[0]]);
ans ++;
}
if(i != q[i])
{
swap(q[0], q[i]);
ans ++;
}
}
}
}
int main()
{
scanf("%d", &n);
for(int i = 0; i < n; i ++ )
scanf("%d", &q[i]);
swap_sort();
printf("%d", ans);
return 0;
}
7-50 电话聊天狂人
给定大量手机用户通话记录,找出其中通话次数最多的聊天狂人。
输入格式:
输入首先给出正整数N(≤105),为通话记录条数。随后N行,每行给出一条通话记录。简单起见,这里只列出拨出方和接收方的11位数字构成的手机号码,其中以空格分隔。
输出格式:
在一行中给出聊天狂人的手机号码及其通话次数,其间以空格分隔。如果这样的人不唯一,则输出狂人中最小的号码及其通话次数,并且附加给出并列狂人的人数。
输入样例:
4
13005711862 13588625832
13505711862 13088625832
13588625832 18087925832
15005713862 13588625832
输出样例:
13588625832 3
思路:
- 刚开始以为要排序,后来发现直接遍历一遍就可以了。
- 用map储存电话号码和拨打次数,每次遇见号码就直接加一。
- 遍历map里面的所有元素,如果拨打次数大则更新一下答案,如果次数相等就把人数加一,每次更新电话号码的时候把sum置为1,当次数相等时题目要求输出号码小的,就在相等的条件里面加一个判断,更新一下电话就可以。
- 刚开始我没写相等时输出电话小的,不知道是不是没有卡这个点。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <map>
using namespace std;
const int N = 100010;
int n;
map<string, int> ma;
int main()
{
cin >> n;
for(int i = 0; i < n; i ++ )
{
string a, b;
cin >> a >> b;
ma[a] ++;
ma[b] ++;
}
string ans;
int max_ans = 0, sum = 1;
for(auto it = ma.begin(); it != ma.end(); it ++ )
{
if(it -> second > max_ans)
{
ans = it -> first;
max_ans = it -> second;
sum = 1;
}
else if(it -> second == max_ans)
{
sum ++;
// 如果电话号码小,则更新
if(ans > it -> first)
ans = it -> first;
}
}
if(sum == 1) cout << ans << ' ' << max_ans << endl;
else cout << ans << ' ' << max_ans << ' ' << sum << endl;
return 0;
}
7-52 QQ帐户的申请与登陆
实现QQ新帐户申请和老帐户登陆的简化版功能。最大挑战是:据说现在的QQ号码已经有10位数了。
输入格式:
输入首先给出一个正整数N(≤105),随后给出N行指令。每行指令的格式为:“命令符(空格)QQ号码(空格)密码”。其中命令符为“N”(代表New)时表示要新申请一个QQ号,后面是新帐户的号码和密码;命令符为“L”(代表Login)时表示是老帐户登陆,后面是登陆信息。QQ号码为一个不超过10位、但大于1000(据说QQ老总的号码是1001)的整数。密码为不小于6位、不超过16位、且不包含空格的字符串。
输出格式:
针对每条指令,给出相应的信息:
1)若新申请帐户成功,则输出“New: OK”;
2)若新申请的号码已经存在,则输出“ERROR: Exist”;
3)若老帐户登陆成功,则输出“Login: OK”;
4)若老帐户QQ号码不存在,则输出“ERROR: Not Exist”;
5)若老帐户密码错误,则输出“ERROR: Wrong PW”。
输入样例:
5
L 1234567890 myQQ@qq.com
N 1234567890 myQQ@qq.com
N 1234567890 myQQ@qq.com
L 1234567890 myQQ@qq
L 1234567890 myQQ@qq.com
输出样例:
ERROR: Not Exist
New: OK
ERROR: Exist
ERROR: Wrong PW
Login: OK
思路:
- 用map来储存每个账号和对应的密码,find去查找。
- 按题给情况分析输出就可以。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <map>
using namespace std;
const int N = 100010;
int n;
map<string, string> ma;
int main()
{
cin >> n;
getchar();
while(n -- )
{
string num, pw;
char op[2];
cin >> op >> num >> pw;
if(*op == 'N')
{
if(ma.find(num) != ma.end())
{
cout << "ERROR: Exist" << endl;
}
else
{
ma[num] = pw;
cout << "New: OK" << endl;
}
}
else
{
if(ma.find(num) != ma.end())
{
if(ma[num] != pw)
cout << "ERROR: Wrong PW" << endl;
else
cout << "Login: OK" << endl;
}
else
cout << "ERROR: Not Exist" << endl;
}
}
return 0;
}
7-54 Harry Potter's Exam(同43)
7-55 QQ Account Management(同52)
7-56 The World's Richest
题目大意:
给定一个n和k,接下来n行,每行是一个人的姓名,年龄,资产,然后给k个询问,每个询问有三个数据,m,l ,r。m是输出数量,和一个年龄范围[ l , r ],输出这个年龄范围内所有人按资产,年龄,姓名排序,输出前m个,如果不足m个,就输出有的,如果这个范围内没有人就输出None。
Forbes magazine publishes every year its list of billionaires based on the annual ranking of the world's wealthiest people. Now you are supposed to simulate this job, but concentrate only on the people in a certain range of ages. That is, given the net worths of N people, you must find the M richest people in a given range of their ages.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 positive integers: N (≤105) - the total number of people, and K (≤103) - the number of queries. Then N lines follow, each contains the name (string of no more than 8 characters without space), age (integer in (0, 200]), and the net worth (integer in [−106, 106]) of a person. Finally there are K lines of queries, each contains three positive integers: M (≤ 100) - the maximum number of outputs, and [A**min, Amax] which are the range of ages. All the numbers in a line are separated by a space.
Output Specification:
For each query, first print in a line Case #X: where X is the query number starting from 1. Then output the M richest people with their ages in the range [A**min, Amax]. Each person's information occupies a line, in the format Name Age Net_Worth.
The outputs must be in non-increasing order of the net worths. In case there are equal worths, it must be in non-decreasing order of the ages. If both worths and ages are the same, then the output must be in non-decreasing alphabetical order of the names. It is guaranteed that there is no two persons share all the same of the three pieces of information. In case no one is found, output None.
Sample Input:
12 4
Zoe_Bill 35 2333
Bob_Volk 24 5888
Anny_Cin 95 999999
Williams 30 -22
Cindy 76 76000
Alice 18 88888
Joe_Mike 32 3222
Michael 5 300000
Rosemary 40 5888
Dobby 24 5888
Billy 24 5888
Nobody 5 0
4 15 45
4 30 35
4 5 95
1 45 50
Sample Output:
Case #1:
Alice 18 88888
Billy 24 5888
Bob_Volk 24 5888
Dobby 24 5888
Case #2:
Joe_Mike 32 3222
Zoe_Bill 35 2333
Williams 30 -22
Case #3:
Anny_Cin 95 999999
Michael 5 300000
Alice 18 88888
Cindy 76 76000
Case #4:
None
思路:
- 这个题目,就是储存,排序和查询,然后按题目要求输出查询结果就可。
- 有个点就是会卡时间,所以不能每次找到年龄段内的人,然后再排序。
- 可以读入所有数据后把数据排好序,然后遍历找到年龄段内的人,直接输出即可。
- 我卡一个点是vector动态申请会超时,所以每次读入n后直接把vector的大小预申请出来。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N = 100010;
struct node
{
char id[10];
int age, mony;
};
int n, k;
bool cmp(node a, node b)
{
if(a.mony != b.mony)
return a.mony > b.mony;
else if(a.age != b.age)
return a.age < b.age;
return strcmp(a.id, b.id) < 0;
}
int main()
{
scanf("%d%d", &n, &k);
vector<node> ma(n);
for(int i = 0; i < n; i ++ )
scanf("%s %d %d", ma[i].id, &ma[i].age, &ma[i].mony);
sort(ma.begin(), ma.end(), cmp);
int num = 1;
while(k -- )
{
int cnt, l, r;
scanf("%d%d%d", &cnt, &l, &r);
// 输出
int flag = 1;
cout << "Case #" << num << ":" << endl;
num ++;
for(auto it = ma.begin(); it != ma.end(); it ++ )
{
if(!cnt) break;
if(it->age >= l && it->age <= r)
{
cout << it->id << ' ' << it->age << ' ' << it->mony << endl;
flag = 0;
cnt --;
}
}
if(flag) cout << "None" << endl;
}
return 0;
}
7-57 汉诺塔的非递归实现
借助堆栈以非递归(循环)方式求解汉诺塔的问题(n, a, b, c),即将N个盘子从起始柱(标记为“a”)通过借助柱(标记为“b”)移动到目标柱(标记为“c”),并保证每个移动符合汉诺塔问题的要求。
输入格式:
输入为一个正整数N,即起始柱上的盘数。
输出格式:
每个操作(移动)占一行,按柱1 -> 柱2的格式输出。
输入样例:
3
输出样例:
a -> c
a -> b
c -> b
a -> c
b -> a
b -> c
a -> c
思路:
- 递归问题
-
- 当n = 1时,直接从a -> c。
- 当n != 1时,把n - 1个先从a -> b,然后把最下面的一个从a -> c,再把n - 1个从b -> c。
- 当n = 1时,直接从a -> c。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <stack>
using namespace std;
struct node
{
int n;
char a, b, c;
};
int n;
stack<node> stk;
void h(int n, char a, char b, char c)
{
if(n == 1)
{
printf("%c -> %c\n", a, c);
return;
}
else
{
h(n - 1, a, c, b);
printf("%c -> %c\n", a, c);
h(n - 1, b, a, c);
}
}
int main()
{
scanf("%d", &n);
// h(n, 'a', 'b', 'c');
stk.push({n, 'a', 'b', 'c'});
while(!stk.empty())
{
node t = stk.top();
stk.pop();
if(t.n == 1)
{
printf("%c -> %c\n", t.a, t.c);
}
else
{
// 把 n - 1 个通过 a 移动到 c 上
stk.push({t.n - 1, t.b, t.a, t.c});
// 把剩下的一个直接从 a 移动到 a 上
stk.push({1, t.a, t.b, t.c});
// 把 n - 1 个通过 c 移动到 b 上
stk.push({t.n - 1, t.a, t.c, t.b});
// 栈是后入先出的数据结构所以压入的时候要反过来。
}
}
return 0;
}
7-58 堆栈模拟队列
设已知有两个堆栈S1和S2,请用这两个堆栈模拟出一个队列Q。
所谓用堆栈模拟队列,实际上就是通过调用堆栈的下列操作函数:
int IsFull(Stack S):判断堆栈S是否已满,返回1或0;int IsEmpty (Stack S ):判断堆栈S是否为空,返回1或0;void Push(Stack S, ElementType item ):将元素item压入堆栈S;ElementType Pop(Stack S ):删除并返回S的栈顶元素。
实现队列的操作,即入队void AddQ(ElementType item)和出队ElementType DeleteQ()。
输入格式:
输入首先给出两个正整数N1和N2,表示堆栈S1和S2的最大容量。随后给出一系列的队列操作:A item表示将item入列(这里假设item为整型数字);D表示出队操作;T表示输入结束。
输出格式:
对输入中的每个D操作,输出相应出队的数字,或者错误信息ERROR:Empty。如果入队操作无法执行,也需要输出ERROR:Full。每个输出占1行。
输入样例:
3 2
A 1 A 2 A 3 A 4 A 5 D A 6 D A 7 D A 8 D D D D T
输出样例:
ERROR:Full
1
ERROR:Full
2
3
4
7
8
ERROR:Empty
思路:
- 当一个序列入栈再按栈的规则出栈进入第二个栈,那么第二个栈再出栈的顺序即为队列的顺序,所以两个栈,一个当作入栈,一个当作出栈,显然入栈的容量小一点。
- 入栈有三种情况:
-
- 当入栈序列不满时,直接进入入栈序列即可。
- 当入栈序列满,而出栈序列为空时,把入栈序列的数弹出压入到出栈序列。
- 当入栈序列满,而出栈序列不为空时,此时不能往出栈序列里压数,判断为满。
- 当入栈序列不满时,直接进入入栈序列即可。
- 出栈有三种情况:
-
- 当出栈序列不为空时,直接弹出即可。
- 当出栈序列空,入栈序列不空时,把入栈序列的数加入出栈序列,再弹出。
- 当出栈空,入栈空时,判断队列为空,输出空即可。
- 当出栈序列不为空时,直接弹出即可。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 10010;
int n1, n2;
int s1[N], s2[N], t1, t2;
// s1 入栈,s2 出栈
int main()
{
scanf("%d%d", &n1, &n2);
getchar();
// 让大容量做为出栈
int IN, OUT;
if(n1 < n2)
{
IN = n1 - 1;
OUT = n2 - 1;
}
else
{
IN = n2 - 1;
OUT = n1 - 1;
}
t1 = t2 = -1;
char x;
while(1)
{
scanf("%c", &x);
if(x == 'T')
break;
else if(x == 'A')
{
int item;
scanf("%d", &item);
// 入栈满,出栈满
if(t1 == IN && t2 > -1)
{
printf("ERROR:Full\n");
}
// 入栈满,出栈空
else if(t1 == IN && t2 == -1)
{
while(t1 > -1)
{
s2[++ t2] = s1[t1 --];
}
s1[++ t1] = item;
}
// 入栈不满
else
{
s1[++ t1] = item;
}
}
else if(x == 'D')
{
// 入栈空,出栈空
if(t1 == -1 && t2 == -1)
{
printf("ERROR:Empty\n");
}
// 入栈不空,出栈空
else if(t1 > -1 && t2 == -1)
{
while(t1 > -1)
{
s2[++ t2] = s1[t1 --];
}
printf("%d\n", s2[t2 --]);
}
// 出栈不空
else
{
printf("%d\n", s2[t2 --]);
}
}
}
return 0;
}
7-59 还原二叉树
给定一棵二叉树的先序遍历序列和中序遍历序列,要求计算该二叉树的高度。
输入格式:
输入首先给出正整数N(≤50),为树中结点总数。下面两行先后给出先序和中序遍历序列,均是长度为N的不包含重复英文字母(区别大小写)的字符串。
输出格式:
输出为一个整数,即该二叉树的高度。
输入样例:
9
ABDFGHIEC
FDHGIBEAC
输出样例:
5
思路:
- 这个题跟由前序和中序求后序一样,只不过不用输出后序序列,记录一下深度,每次如果深度大于答案后更新一下最大深度。
- 前序的第一个点即为二叉树的根节点,在中序序列中找到该点后,该点的左侧即为左子树,右侧即为右子树,只需要递归处理左右子树即可,每次层数都会加一,递归开始时都判断一下res是否需要更新,递归完以后res即为最大深度。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 55;
int n, res;
char pre[N], in[N];
void f(int root, int l, int r, int d)
{
if(l > r) return ;
res = max(res, d);
int i = l;
// 找到根节点
while(i < r && in[i] != pre[root]) i ++;
// 左子树
f(root + 1, l, i - 1, d + 1);
// 右子树
f(root + 1 + i - l, i + 1, r, d + 1);
}
int main()
{
scanf("%d", &n);
scanf("%s%s", pre, in);
f(0, 0, n - 1, 1);
printf("%d\n", res);
return 0;
}
7-60 树种统计
随着卫星成像技术的应用,自然资源研究机构可以识别每一棵树的种类。请编写程序帮助研究人员统计每种树的数量,计算每种树占总数的百分比。
输入格式:
输入首先给出正整数N(≤105),随后N行,每行给出卫星观测到的一棵树的种类名称。种类名称由不超过30个英文字母和空格组成(大小写不区分)。
输出格式:
按字典序递增输出各种树的种类名称及其所占总数的百分比,其间以空格分隔,保留小数点后4位。
输入样例:
29
Red Alder
Ash
Aspen
Basswood
Ash
Beech
Yellow Birch
Ash
Cherry
Cottonwood
Ash
Cypress
Red Elm
Gum
Hackberry
White Oak
Hickory
Pecan
Hard Maple
White Oak
Soft Maple
Red Oak
Red Oak
White Oak
Poplan
Sassafras
Sycamore
Black Walnut
Willow
输出样例:
Ash 13.7931%
Aspen 3.4483%
Basswood 3.4483%
Beech 3.4483%
Black Walnut 3.4483%
Cherry 3.4483%
Cottonwood 3.4483%
Cypress 3.4483%
Gum 3.4483%
Hackberry 3.4483%
Hard Maple 3.4483%
Hickory 3.4483%
Pecan 3.4483%
Poplan 3.4483%
Red Alder 3.4483%
Red Elm 3.4483%
Red Oak 6.8966%
Sassafras 3.4483%
Soft Maple 3.4483%
Sycamore 3.4483%
White Oak 10.3448%
Willow 3.4483%
Yellow Birch 3.4483%
思路:
- 用map把每个名字储存和数量储存下来,因为map是按key值排序的所以直接遍历一遍然后输出名字和比例就可以了。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <map>
#define x first
#define y second
using namespace std;
const int N = 100010;
int n;
map<string, int> ma;
int main()
{
scanf("%d", &n);
getchar();
for(int i = 0; i < n; i ++ )
{
string s;
getline(cin, s);
ma[s] ++;
}
for(auto it = ma.begin(); it != ma.end(); it ++ )
{
cout << it->x << ' ';
printf("%.4f%\n", 100.0 * it->y / n);
}
return 0;
}
7-61 朋友圈
某学校有N个学生,形成M个俱乐部。每个俱乐部里的学生有着一定相似的兴趣爱好,形成一个朋友圈。一个学生可以同时属于若干个不同的俱乐部。根据“我的朋友的朋友也是我的朋友”这个推论可以得出,如果A和B是朋友,且B和C是朋友,则A和C也是朋友。请编写程序计算最大朋友圈中有多少人。
输入格式:
输入的第一行包含两个正整数N(≤30000)和M(≤1000),分别代表学校的学生总数和俱乐部的个数。后面的M行每行按以下格式给出1个俱乐部的信息,其中学生从1~N编号:
第i个俱乐部的人数Mi(空格)学生1(空格)学生2 … 学生Mi
输出格式:
输出给出一个整数,表示在最大朋友圈中有多少人。
输入样例:
7 4
3 1 2 3
2 1 4
3 5 6 7
1 6
输出样例:
4
思路:
- 并查集应用。
- 把同一个朋友圈的人加到一个集合里,最后遍历一遍,然后如果在同一个集合里就把数量加加,及时更新最大值即可。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 30010;
int n, m;
int p[N], num[N];
int find(int x)
{
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
scanf("%d%d", &n, &m);
// 初始化并查集
for(int i = 0; i <= n; i ++ )
p[i] = i;
while(m -- )
{
int x, t1;
scanf("%d%d", &x, &t1);
x --;
while(x -- )
{
int t2;
scanf("%d", &t2);
p[find(t2)] = find(t1);
}
}
int res = 1;
for(int i = 1; i <= n; i ++ )
{
int t = find(i);
num[t] ++;
res = max(res, num[t]);
}
printf("%d\n", res);
return 0;
}
7-62 Windows消息队列
消息队列是Windows系统的基础。对于每个进程,系统维护一个消息队列。如果在进程中有特定事件发生,如点击鼠标、文字改变等,系统将把这个消息加到队列当中。同时,如果队列不是空的,这一进程循环地从队列中按照优先级获取消息。请注意优先级值低意味着优先级高。请编辑程序模拟消息队列,将消息加到队列中以及从队列中获取消息。
输入格式:
输入首先给出正整数N(≤105),随后N行,每行给出一个指令——GET或PUT,分别表示从队列中取出消息或将消息添加到队列中。如果指令是PUT,后面就有一个消息名称、以及一个正整数表示消息的优先级,此数越小表示优先级越高。消息名称是长度不超过10个字符且不含空格的字符串;题目保证队列中消息的优先级无重复,且输入至少有一个GET。
输出格式:
对于每个GET指令,在一行中输出消息队列中优先级最高的消息的名称和参数。如果消息队列中没有消息,输出EMPTY QUEUE!。对于PUT指令则没有输出。
输入样例:
9
PUT msg1 5
PUT msg2 4
GET
PUT msg3 2
PUT msg4 4
GET
GET
GET
GET
输出样例:
msg2
msg3
msg4
msg1
EMPTY QUEUE!
思路:
- 调用优先队列就是堆,然后每次直接输出堆顶就可以了,重载结构体内的小于号,让消息队列排序按照优先级。
- 每次读入命令后判断,如果是输入就压入队列,如果是输出,就把堆顶拿出,然后弹出,每次记得判断队列是否为空,为空即输出空。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int N = 100010;
struct node
{
char name[15];
int rank;
bool operator <(const node x) const{
return rank > x.rank;
}
}w;
int n;
string op, p;
priority_queue<node> q;
// 优先队列,堆,重载小于号
int main()
{
cin >> n;
p = "PUT";
for(int i = 0; i < n; i ++ )
{
cin >> op;
if(op == p)
{
cin >> w.name >> w.rank;
q.push(w);
}
else
{
if(q.empty())
{
cout << "EMPTY QUEUE!" << endl;
}
else
{
w = q.top();
q.pop();
cout << w.name << endl;
}
}
}
return 0;
}
7-64 修理牧场
农夫要修理牧场的一段栅栏,他测量了栅栏,发现需要N块木头,每块木头长度为整数L**i个长度单位,于是他购买了一条很长的、能锯成N块的木头,即该木头的长度是L**i的总和。
但是农夫自己没有锯子,请人锯木的酬金跟这段木头的长度成正比。为简单起见,不妨就设酬金等于所锯木头的长度。例如,要将长度为20的木头锯成长度为8、7和5的三段,第一次锯木头花费20,将木头锯成12和8;第二次锯木头花费12,将长度为12的木头锯成7和5,总花费为32。如果第一次将木头锯成15和5,则第二次锯木头花费15,总花费为35(大于32)。
请编写程序帮助农夫计算将木头锯成N块的最少花费。
输入格式:
输入首先给出正整数N(≤104),表示要将木头锯成N块。第二行给出N个正整数(≤50),表示每段木块的长度。
输出格式:
输出一个整数,即将木头锯成N块的最少花费。
输入样例:
8
4 5 1 2 1 3 1 1
输出样例:
49
思路:
- 刚看到这个题目以为是要用贪心去解,后来发现考察的是哈夫曼树,最小生成树。
- 每次选最小的两个连到一起生成树,然后把值加到序列里,再去选最小的,最后的哈夫曼树的树根即为答案。
- 用到了STL里的优先队列(堆),自动排序,每次去堆顶就可以了,然后把加一起以后的值加入被选序列里。
AC代码:
调用STL
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
#include <vector>
using namespace std;
const int N = 60;
int n, sum;
priority_queue<int, vector<int>, greater<int> >q;
int main()
{
scanf("%d", &n);
for(int i = 0; i < n; i ++ )
{
int x;
scanf("%d", &x);
q.push(x);
}
while(q.size() > 1)
{
int t1 = q.top(); q.pop();
int t2 = q.top(); q.pop();
sum += t1 + t2;
q.push(t1 + t2);
}
printf("%d", sum);
return 0;
}
数组实现
#include <bits/stdc++.h>
using namespace std;
const int N = 10010;
int n;
int a[N];
int main() {
scanf("%d", &n);
for(int i = 1; i <= n; i ++ ) {
scanf("%d", &a[i]);
}
sort(a + 1, a + 1 + n);
int sum = 0;
for(int i = 1; i <= n; i ++ ) {
sum += a[i] + a[i + 1];
a[i + 1] += a[i];
sort(a + 1 + i, a + 1 + n);
}
cout << sum - a[n];
return 0;
}
7-66 哥尼斯堡的“七桥问题”
哥尼斯堡是位于普累格河上的一座城市,它包含两个岛屿及连接它们的七座桥,如下图所示。
可否走过这样的七座桥,而且每桥只走过一次?瑞士数学家欧拉(Leonhard Euler,1707—1783)最终解决了这个问题,并由此创立了拓扑学。
这个问题如今可以描述为判断欧拉回路是否存在的问题。欧拉回路是指不令笔离开纸面,可画过图中每条边仅一次,且可以回到起点的一条回路。现给定一个无向图,问是否存在欧拉回路?
输入格式:
输入第一行给出两个正整数,分别是节点数N (1≤N≤1000)和边数M;随后的M行对应M条边,每行给出一对正整数,分别是该条边直接连通的两个节点的编号(节点从1到N编号)。
输出格式:
若欧拉回路存在则输出1,否则输出0。
输入样例1:
6 10
1 2
2 3
3 1
4 5
5 6
6 4
1 4
1 6
3 4
3 6
输出样例1:
1
输入样例2:
5 8
1 2
1 3
2 3
2 4
2 5
5 3
5 4
3 4
输出样例2:
0
思路:
-
欧拉回路知识点:
-
定义
如果图G(有向图或者无向图)中所有边一次仅且一次行遍所有顶点的通路称作欧拉通路。如果图G中所有边一次仅且一次行遍所有顶点的回路称作欧拉回路。具有欧拉回路的图称为欧拉图(简称E图)。具有欧拉通路但不具有欧拉回路的图称为半欧拉图。
-
欧拉回路存在的判断方法
- 有向图:图连通;所有的顶点的入度等于出度。
- 无向图:图连通;所有点的度必须为偶数。
-
欧拉通路存在的判断方法
- 有向图:图连通;所有点中除去两个点其他点的入度等于出度;除去的两个特殊点一个是入度-出度=1,一个是出度-入度=1。
- 无向图:图连通;所有点除去两个点其他点的度均为偶数;除去的两个点度为奇数。
-
-
储存点的时候把每个点的度计算一下,遍历度的数组检查是否存在度为奇数的点。
-
dfs递归遍历每个点,判断是否是连通图。递归过程中把每个与该点连接的点都遍历并且置st为1,循环是用ans记录图中有几个独立集合,如果只有一个那么即为连通图,大于1即至少两个图所以不连通。
-
最后根据两个条件判断得到是否存在欧拉回路。
-
还有一个法子是用并查集把每个连通的点放到一个集合里,可以直接判断p[i]是否等于 i ,如果是连通图那么肯定只满足一个,所以ans等于1为连通图。
AC代码:
dfs求连通
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010;
int n, m;
int g[N][N], d[N], st[N];
void dfs(int x)
{
st[x] = 1;
for(int i = 1; i <= n; i ++ )
{
int t = g[x][i];
if(!st[i] && t == 1)
dfs(i);
}
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 0; i < m; i ++ )
{
int a, b;
scanf("%d%d", &a, &b);
g[a][b] = g[b][a] = 1;
d[a] ++;
d[b] ++;
}
// flag 为 1 表示图中无奇数度的结点
int flag = 1;
for(int i = 1; i <= n; i ++ )
if(d[i] % 2) flag = 0;
// 判断图是否连通
int ans = 0;
for(int i = 1; i <= n; i ++ )
{
if(!st[i])
{
dfs(i);
ans ++;
}
}
if(ans == 1 && flag == 1)
printf("1");
else
printf("0");
return 0;
}
并查集求连通
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1010;
int n, m;
int g[N][N], d[N], p[N], st[N];
int find(int x)
{
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i ++ )
p[i] = i;
for(int i = 0; i < m; i ++ )
{
int a, b;
scanf("%d%d", &a, &b);
// g[a][b] = g[b][a] = 1;
if(find(a) != find(b))
{
p[find(b)] = find(a);
}
d[a] ++;
d[b] ++;
}
// flag 为 1 表示图中无奇数度的结点
int flag = 1, ans = 0;
for(int i = 1; i <= n; i ++ )
{
if(d[i] % 2) flag = 0;
// 判断图是否连通
if(p[i] == i)
ans ++;
}
if(ans == 1 && flag == 1)
printf("1");
else
printf("0");
return 0;
}
7-67 任务调度的合理性
假定一个工程项目由一组子任务构成,子任务之间有的可以并行执行,有的必须在完成了其它一些子任务后才能执行。“任务调度”包括一组子任务、以及每个子任务可以执行所依赖的子任务集。
比如完成一个专业的所有课程学习和毕业设计可以看成一个本科生要完成的一项工程,各门课程可以看成是子任务。有些课程可以同时开设,比如英语和C程序设计,它们没有必须先修哪门的约束;有些课程则不可以同时开设,因为它们有先后的依赖关系,比如C程序设计和数据结构两门课,必须先学习前者。
但是需要注意的是,对一组子任务,并不是任意的任务调度都是一个可行的方案。比如方案中存在“子任务A依赖于子任务B,子任务B依赖于子任务C,子任务C又依赖于子任务A”,那么这三个任务哪个都不能先执行,这就是一个不可行的方案。你现在的工作是写程序判定任何一个给定的任务调度是否可行。
输入格式:
输入说明:输入第一行给出子任务数N(≤100),子任务按1~N编号。随后N行,每行给出一个子任务的依赖集合:首先给出依赖集合中的子任务数K,随后给出K个子任务编号,整数之间都用空格分隔。
输出格式:
如果方案可行,则输出1,否则输出0。
输入样例1:
12
0
0
2 1 2
0
1 4
1 5
2 3 6
1 3
2 7 8
1 7
1 10
1 7
输出样例1:
1
输入样例2:
5
1 4
2 1 4
2 2 5
1 3
0
输出样例2:
0
思路:
- 拓扑排序,有向图判环。
- 把入度为零的点入队,每次从队列中取出删除入度为零的点,把与该点相连的点的入度减一,如果为零则入队。
- 用ans储存入队点的个数,如果ans = n,则表明每个点都进入过队列,说明没有环,反之存在环。
AC代码:
#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 110;
int n, k;
int ind[N], g[N][N]; //ind[]c
queue<int> q;
int main()
{
scanf("%d", &n);
for(int i = 1; i <= n; i ++ )
{
scanf("%d", &k);
while(k -- )
{
int x;
scanf("%d", &x);
g[x][i] = 1;
ind[i] ++;
}
}
// 找到入度为 0 的点
for(int i = 1; i <= n; i ++ )
{
if(ind[i] == 0)
q.push(i);
}
// 拓扑排序
int ans = 0;
while(!q.empty())
{
int t = q.front();
q.pop();
ans ++;
for(int i = 1; i <= n; i ++ )
if(g[t][i])
{
ind[i] --;
if(ind[i] == 0)
q.push(i);
}
}
if(ans == n) printf("1");
else printf("0");
return 0;
}
7-68 城市间紧急救援
作为一个城市的应急救援队伍的负责人,你有一张特殊的全国地图。在地图上显示有多个分散的城市和一些连接城市的快速道路。每个城市的救援队数量和每一条连接两个城市的快速道路长度都标在地图上。当其他城市有紧急求助电话给你的时候,你的任务是带领你的救援队尽快赶往事发地,同时,一路上召集尽可能多的救援队。
输入格式:
输入第一行给出4个正整数N、M、S、D,其中N(2≤N≤500)是城市的个数,顺便假设城市的编号为0 ~ (N−1);M是快速道路的条数;S是出发地的城市编号;D是目的地的城市编号。
第二行给出N个正整数,其中第i个数是第i个城市的救援队的数目,数字间以空格分隔。随后的M行中,每行给出一条快速道路的信息,分别是:城市1、城市2、快速道路的长度,中间用空格分开,数字均为整数且不超过500。输入保证救援可行且最优解唯一。
输出格式:
第一行输出最短路径的条数和能够召集的最多的救援队数量。第二行输出从S到D的路径中经过的城市编号。数字间以空格分隔,输出结尾不能有多余空格。
输入样例:
4 5 0 3
20 30 40 10
0 1 1
1 3 2
0 3 3
0 2 2
2 3 2
输出样例:
2 60
0 1 3
思路:
- dijkstra算法基础应用,再过程中记录需要用到的数据量。
- 每次更新的时候把路径储存下来,最后用dfs来遍历输出答案。
- 需要输出的是最短路径的数量和最多的救援队数量,最后输出路径上城市的编号。
- 在过程中更新dist的条件是dist[j] > dist[t] + g [t][j] || (dist[j] > dist[t] + g[t][j] && wi[j] > wi[t] + w[j])。
-
- 第一种情况,还在同一条路径上,所以j的路径数量等于t的路径数量。
- 第二种情况即不在同一条路径上,j的路径数量等于j的加上t的路径数量。
- 第一种情况,还在同一条路径上,所以j的路径数量等于t的路径数量。
- 注:一定要初始化dist和g数组。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 510;
int n, m, s, d;
int w[N], g[N][N], st[N];
int path[N], dist[N], num[N], wi[N];
// 路径记录,每个点到起点的距离,路径条数,到该点路径上集结最多的人数
void dijkstra(int s)
{
memset(dist, 0x3f, sizeof dist);
dist[s] = 0;
wi[s] = w[s];
num[s] = 1;
for(int i = 0; i < n; i ++ )
{
int t = -1;
// 找到当前距离起点最短的点
for(int j = 0; j < n; j ++ )
if(!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
// if(t == -1) break;
st[t] = 1;
// 更新每个点的距离
for(int j = 0; j < n; j ++ )
{
// 同一条路
if(!st[j] && dist[j] > dist[t] + g[t][j])
{
dist[j] = dist[t] + g[t][j];
path[j] = t;
wi[j] = wi[t] + w[j];
num[j] = num[t];
}
// 不同的路
else if(!st[j] && dist[j] == dist[t] + g[t][j])
{
num[j] += num[t];
if(wi[j] < wi[t] + w[j])
{
wi[j] = wi[t] + w[j];
path[j] = t;
}
}
}
}
}
void dfs(int d)
{
if(d == s)
{
printf("%d", d);
return ;
}
else
{
dfs(path[d]);
printf(" %d", d);
}
}
int main()
{
memset(g, 0x3f, sizeof g);
scanf("%d%d%d%d", &n, &m, &s, &d);
for(int i = 0; i < n; i ++ )
scanf("%d", &w[i]);
for(int i = 0; i < m; i ++ )
{
int a, b, l;
scanf("%d%d%d", &a, &b, &l);
g[a][b] = g[b][a] = l;
}
dijkstra(s);
printf("%d %d\n", num[d], wi[d]);
dfs(d);
return 0;
}
7-69 模拟EXCEL排序
Excel可以对一组纪录按任意指定列排序。现请编写程序实现类似功能。
输入格式:
输入的第一行包含两个正整数N(≤105) 和C,其中N是纪录的条数,C是指定排序的列号。之后有 N行,每行包含一条学生纪录。每条学生纪录由学号(6位数字,保证没有重复的学号)、姓名(不超过8位且不包含空格的字符串)、成绩([0, 100]内的整数)组成,相邻属性用1个空格隔开。
输出格式:
在N行中输出按要求排序后的结果,即:当C=1时,按学号递增排序;当C=2时,按姓名的非递减字典序排序;当C=3时,按成绩的非递减排序。当若干学生具有相同姓名或者相同成绩时,则按他们的学号递增排序。
输入样例:
3 1
000007 James 85
000010 Amy 90
000001 Zoe 60
输出样例:
000001 Zoe 60
000007 James 85
000010 Amy 90
思路:
- 排序题目,用结构体储存数据,根据输入判断出应该按照哪个排序。
- 调用sort函数,自己手写cmp规则,根据c来判断调用规则。
- 排序结束后直接按规则输出即可。
- 注:当名字相同时按照学号排序。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010;
struct student
{
int id;
char name[10];
int grade;
}stu[N];
int n, m;
bool cmp1(student a, student b)
{
return a.id < b.id;
}
bool cmp2(student a, student b)
{
if(strcmp(a.name, b.name) == 0)
return a.id < b.id;
return strcmp(a.name, b.name) < 0;
}
bool cmp3(student a, student b)
{
if(a.grade != b.grade)
return a.grade < b.grade;
else if(strcmp(a.name, b.name) == 0)
return strcmp(a.name, b.name) < 0;
else
return a.id < b.id;
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 0; i < n; i ++ )
scanf("%d%s%d", &stu[i].id, stu[i].name, &stu[i].grade);
if(m == 1)
sort(stu, stu + n, cmp1);
else if(m == 2)
sort(stu, stu + n, cmp2);
else
sort(stu, stu + n, cmp3);
for(int i = 0; i < n; i ++ )
{
printf("%06d %s %d\n", stu[i].id, stu[i].name, stu[i].grade);
}
return 0;
}
7-70 魔法优惠券
在火星上有个魔法商店,提供魔法优惠券。每个优惠劵上印有一个整数面值K,表示若你在购买某商品时使用这张优惠劵,可以得到K倍该商品价值的回报!该商店还免费赠送一些有价值的商品,但是如果你在领取免费赠品的时候使用面值为正的优惠劵,则必须倒贴给商店K倍该商品价值的金额…… 但是不要紧,还有面值为负的优惠劵可以用!(真是神奇的火星)
例如,给定一组优惠劵,面值分别为1、2、4、-1;对应一组商品,价值为火星币M7、6、−2、−3,其中负的价值表示该商品是免费赠品。我们可以将优惠劵3用在商品1上,得到M28的回报;优惠劵2用在商品2上,得到M12的回报;优惠劵4用在商品4上,得到M3的回报。但是如果一不小心把优惠劵3用在商品4上,你必须倒贴给商店M12。同样,当你一不小心把优惠劵4用在商品1上,你必须倒贴给商店M7。
规定每张优惠券和每件商品都只能最多被使用一次,求你可以得到的最大回报。
输入格式:
输入有两行。第一行首先给出优惠劵的个数N,随后给出N个优惠劵的整数面值。第二行首先给出商品的个数M,随后给出M个商品的整数价值。N和M在[1, 106]之间,所有的数据大小不超过230,数字间以空格分隔。
输出格式:
输出可以得到的最大回报。
输入样例:
4 1 2 4 -1
4 7 6 -2 -3
输出样例:
43
思路:
- 贪心题目,要的到最大的钱数即看优惠券和商品价格的乘积和最大。
- 把两个数组都按降序排好,用双指针来记录数字的位置。
- head前面模拟,直接看如果q[] x g[] 是大于0 的即这个组合是成立的。
- 两个尾指针是不一样的,所以要分开模拟,后面是负数,两个负数相乘大于零即也是合适的答案,但是注意随时检查头指针和尾指针是否越界,即保持head <= min(tail1, tail2),head要随时小于两个尾指针的最小值。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1000010;
int n, m;
int q[N], g[N];
bool cmp(int a, int b)
{
return a > b;
}
int main()
{
scanf("%d", &n);
for(int i = 1; i <= n; i ++ )
scanf("%d", &q[i]);
scanf("%d", &m);
for(int i = 1; i <= m; i ++ )
scanf("%d", &g[i]);
sort(q + 1, q + 1 + n, cmp);
sort(g + 1, g + 1 + m, cmp);
int head = 1, tail1 = n, tail2 = m;
int sum = 0;
while(q[head] * g[head] > 0)
{
sum += q[head] * g[head];
head ++;
}
while(head <= min(tail1, tail2) && q[tail1] * g[tail2] > 0)
{
sum += q[tail1] * g[tail2];
tail1 --;
tail2 --;
}
printf("%d", sum);
return 0;
}
7-71 奥运排行榜
每年奥运会各大媒体都会公布一个排行榜,但是细心的读者发现,不同国家的排行榜略有不同。比如中国金牌总数列第一的时候,中国媒体就公布“金牌榜”;而美国的奖牌总数第一,于是美国媒体就公布“奖牌榜”。如果人口少的国家公布一个“国民人均奖牌榜”,说不定非洲的国家会成为榜魁…… 现在就请你写一个程序,对每个前来咨询的国家按照对其最有利的方式计算它的排名。
输入格式:
输入的第一行给出两个正整数N和M(≤224,因为世界上共有224个国家和地区),分别是参与排名的国家和地区的总个数、以及前来咨询的国家的个数。为简单起见,我们把国家从0 ~ N−1编号。之后有N行输入,第i行给出编号为i−1的国家的金牌数、奖牌数、国民人口数(单位为百万),数字均为[0,1000]区间内的整数,用空格分隔。最后面一行给出M个前来咨询的国家的编号,用空格分隔。
输出格式:
在一行里顺序输出前来咨询的国家的排名:计算方式编号。其排名按照对该国家最有利的方式计算;计算方式编号为:金牌榜=1,奖牌榜=2,国民人均金牌榜=3,国民人均奖牌榜=4。输出间以空格分隔,输出结尾不能有多余空格。
若某国在不同排名方式下有相同名次,则输出编号最小的计算方式。
输入样例:
4 4
51 100 1000
36 110 300
6 14 32
5 18 40
0 1 2 3
输出样例:
1:1 1:2 1:3 1:4
思路:
- 排序题目。
- 因为只给出了金牌数,奖牌数,人口数,需要输出的是用哪种方式排名可以使得该国家的排名最小,所以需要把每种方式都排出来,然后把这种排序下该国家的名次储存下来。
- 这里我用到两个结构体数组来储存国家的奖牌数和排名,用p数组去进行各个方式的排序,然后在pre数组下,就可以直接通过数组下标直接查找到国家的位置并把排名直接插入。
- 输出时,直接用一个t储存该国家的排名,用k储存用的哪种方式排序,每次比较把最小的排名去更新t的值,同时更新k的值,最后直接输出排名和排序方式即可。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 230;
struct nation
{
int id;
int goldmedal, medal, pupl;
int r1, r2, r3, r4;
}p[N], pre[N];
int n, m;
bool cmp1(nation a, nation b)
{
return a.goldmedal > b.goldmedal;
}
bool cmp2(nation a, nation b)
{
return a.medal > b.medal;
}
bool cmp3(nation a, nation b)
{
float t1 = a.goldmedal * 1.0 / a.pupl;
float t2 = b.goldmedal * 1.0 / b.pupl;
return t1 > t2;
}
bool cmp4(nation a, nation b)
{
float t1 = a.medal * 1.0 / a.pupl;
float t2 = b.medal * 1.0 / b.pupl;
return t1 > t2;
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 0; i < n; i ++ )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
p[i].id = i;
p[i].goldmedal = a;
p[i].medal = b;
p[i].pupl= c;
}
// 金牌排序
sort(p, p + n, cmp1);
for(int i = 0; i < n; i ++ )
{
if(p[i].goldmedal == p[i - 1].goldmedal && i - 1 >= 0)
{
pre[p[i].id].r1 = pre[p[i - 1].id].r1;
}
else
pre[p[i].id].r1 = i + 1;
}
// 奖牌排序
sort(p, p + n, cmp2);
for(int i = 0; i < n; i ++ )
{
if(p[i].medal == p[i - 1].medal && i - 1 >= 0)
{
pre[p[i].id].r2 = pre[p[i - 1].id].r2;
}
else
pre[p[i].id].r2 = i + 1;
}
// 人均金牌
sort(p, p + n, cmp3);
for(int i = 0; i < n; i ++ )
{
if(p[i].goldmedal * 1.0 / p[i].pupl == p[i - 1].goldmedal * 1.0 / p[i - 1].pupl && i - 1 >= 0)
{
pre[p[i].id].r3 = pre[p[i - 1].id].r3;
}
else
pre[p[i].id].r3 = i + 1;
}
// 人均奖牌
sort(p, p + n, cmp4);
for(int i = 0; i < n; i ++ )
{
if(p[i].medal * 1.0 / p[i].pupl == p[i - 1].medal * 1.0 / p[i - 1].pupl && i - 1 >= 0)
{
pre[p[i].id].r4 = pre[p[i - 1].id].r4;
}
else
pre[p[i].id].r4 = i + 1;
}
int flag = 0;
while(m -- )
{
int x;
scanf("%d", &x);
int t = pre[x].r1;
int k = 1;
if(t > pre[x].r2)
t = pre[x].r2, k = 2;
if(t > pre[x].r3)
t = pre[x].r3, k = 3;
if(t > pre[x].r4)
t = pre[x].r4, k = 4;
if(flag) printf(" ");
flag = 1;
printf("%d:%d", t, k);
}
return 0;
}
7-72 PAT排名汇总
计算机程序设计能力考试(Programming Ability Test,简称PAT)旨在通过统一组织的在线考试及自动评测方法客观地评判考生的算法设计与程序设计实现能力,科学的评价计算机程序设计人才,为企业选拔人才提供参考标准(网址http://www.patest.cn)。
每次考试会在若干个不同的考点同时举行,每个考点用局域网,产生本考点的成绩。考试结束后,各个考点的成绩将即刻汇总成一张总的排名表。
现在就请你写一个程序自动归并各个考点的成绩并生成总排名表。
输入格式:
输入的第一行给出一个正整数N(≤100),代表考点总数。随后给出N个考点的成绩,格式为:首先一行给出正整数K(≤300),代表该考点的考生总数;随后K行,每行给出1个考生的信息,包括考号(由13位整数字组成)和得分(为[0,100]区间内的整数),中间用空格分隔。
输出格式:
首先在第一行里输出考生总数。随后输出汇总的排名表,每个考生的信息占一行,顺序为:考号、最终排名、考点编号、在该考点的排名。其中考点按输入给出的顺序从1到N编号。考生的输出须按最终排名的非递减顺序输出,获得相同分数的考生应有相同名次,并按考号的递增顺序输出。
输入样例:
2
5
1234567890001 95
1234567890005 100
1234567890003 95
1234567890002 77
1234567890004 85
4
1234567890013 65
1234567890011 25
1234567890014 100
1234567890012 85
输出样例:
9
1234567890005 1 1 1
1234567890014 1 2 1
1234567890001 3 1 2
1234567890003 3 1 2
1234567890004 5 1 4
1234567890012 5 2 2
1234567890002 7 1 5
1234567890013 8 2 3
1234567890011 9 2 4
思路:
- 排序题目。
- 按照提给要求即分数第一,同分情况按考号排,每个考点读入完以后进行该考点的排序,然后把每个人的考点名次插入到结构体中。
- 读入全部学生以后,按照要求进行一下全排,把每个人的最终名次插入到结构体中。
- 按要求格式输出答案即可。
- 补充:cin,cout 的速度优化,优化以后速度和scanf,printf 速度差不多。
- ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 30010;
struct student
{
char id[15];
int grade, num;
int Lrank, Trank;
}stu[N];
int n, m;
int sum;
bool cmp(student a, student b)
{
if(a.grade != b.grade)
return a.grade > b.grade;
else
return strcmp(a.id, b.id) < 0;
}
int main()
{
// cin,cout 优化速度
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
// scanf("%d", &n);
cin >> n;
for(int i = 1; i <= n; i ++ )
{
// scanf("%d", &m);
cin >> m;
for(int j = sum; j < sum + m; j ++ )
{
// scanf("%s %d", stu[j].id, &stu[j].grade);
cin >> stu[j].id >> stu[j].grade;
stu[j].num = i;
}
sort(stu + sum, stu + sum + m, cmp);
stu[sum].Trank = 1;
for(int j = sum + 1; j < m + sum; j ++ )
{
if(stu[j].grade == stu[j - 1].grade)
stu[j].Trank = stu[j - 1].Trank;
else
stu[j].Trank = j - sum + 1;
}
sum += m;
}
sort(stu, stu + sum, cmp);
stu[0].Lrank = 1;
for(int j = 1; j < sum; j ++ )
{
if(stu[j].grade == stu[j - 1].grade)
stu[j].Lrank = stu[j - 1].Lrank;
else
stu[j].Lrank = j + 1;
}
// printf("%d\n", sum);
cout << sum << endl;
for(int j = 0; j < sum; j ++ )
{
cout << stu[j].id << ' ' << stu[j].Lrank << ' ' << stu[j].num << ' ' << stu[j].Trank << endl;
// printf("%d %d %d\n", stu[j].Lrank, stu[j].num, stu[j].Trank);
}
return 0;
}
7-73 整型关键字的散列映射
给定一系列整型关键字和素数P,用除留余数法定义的散列函数H(Key)=Key将关键字映射到长度为P的散列表中。用线性探测法解决冲突。
输入格式:
输入第一行首先给出两个正整数N(≤1000)和P(≥N的最小素数),分别为待插入的关键字总数、以及散列表的长度。第二行给出N个整型关键字。数字间以空格分隔。
输出格式:
在一行内输出每个整型关键字在散列表中的位置。数字间以空格分隔,但行末尾不得有多余空格。
输入样例:
4 5
24 15 61 88
输出样例:
4 0 1 3
思路:
- 线性探测法如果当前位置有元素 t = (x + k) % p,k从1开始逐渐加一。
- 每次读入一个元素先找到该元素的散列位置,即与 p 取余后的位置没有元素,同时该元素也是第一次出现,如果出现过直接输出该元素的位置即可。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1020;
int n, p, x, flag;
int h[N];
int main() {
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
cin >> n >> p;
memset(h, -1, sizeof h);
for(int i = 0; i < n; i ++ ) {
cin >> x;
int k = 1;
int t = x % p;
while(h[t] != -1 && h[t] != x) {
t = (x + k) % p;
k ++ ;
}
h[t] = x;
if(flag) cout << ' ';
flag = 1;
cout << t;
}
return 0;
}
7-74 字符串关键字的散列映射
给定一系列由大写英文字母组成的字符串关键字和素数P,用移位法定义的散列函数H(Key)将关键字Key中的最后3个字符映射为整数,每个字符占5位;再用除留余数法将整数映射到长度为P的散列表中。例如将字符串AZDEG插入长度为1009的散列表中,我们首先将26个大写英文字母顺序映射到整数0~25;再通过移位将其映射为3×322+4×32+6=3206;然后根据表长得到3206,即是该字符串的散列映射位置。
发生冲突时请用平方探测法解决。
输入格式:
输入第一行首先给出两个正整数N(≤500)和P(≥2N的最小素数),分别为待插入的关键字总数、以及散列表的长度。第二行给出N个字符串关键字,每个长度不超过8位,其间以空格分隔。
输出格式:
在一行内输出每个字符串关键字在散列表中的位置。数字间以空格分隔,但行末尾不得有多余空格。
输入样例1:
4 11
HELLO ANNK ZOE LOLI
输出样例1:
3 10 4 0
输入样例2:
6 11
LLO ANNA NNK ZOJ INNK AAA
输出样例2:
3 0 10 9 6 1
思路:
- 平方探测法:
- 如果冲突,即 h[t] 位置上有元素了,则 t = t + 1 ^ 2,如果还冲突就 t = t - 1 ^ 2,依次以加减平方递增。
- 即序列为:+1^2, - 1^2, + 2^2, - 2^2, + 3^2, - 3 ^3, ……,+p^2, -p^2。 p <= size / 2;
- 需要用到额外的一个char数组来储存字符串,当该点的哈希值(即为最后三位字母的值)存在且相等时,比较字符串是否相等,如果相等直接输出值,不相等即用平方探测法去寻找下一个位置。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1020;
int n, p, x, flag;
int h[N];
char str[10];
char g[N][10];
void mprint(int temp) {
if(flag) cout << ' ';
flag = 1;
cout << temp;
}
int main() {
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
cin >> n >> p;
memset(h, -1, sizeof h);
for(int i = 0; i < n; i ++ ) {
int x = 0, k = 1;
cin >> str;
for(int j = strlen(str) - 1, tj = 0; j >= 0 && tj < 3; j --, tj ++) {
x += (str[j] - 'A') * k;
k *= 32;
}
// 平方探测处理冲突
int t = x % p;
if(h[t] == -1) {
h[t] = x;
strcpy(g[t], str);
mprint(t);
continue;
} else if(h[t] == x) {
if(strcmp(g[t], str) == 0) {
mprint(t);
continue;
}
}
k = 1;
while(1) {
int temp = (t + k * k) % p;
if(h[temp] == x) {
mprint(temp);
break;
} else if(h[temp] == -1) {
h[temp] = x;
strcpy(g[temp], str);
mprint(temp);
break;
}
temp = (t - k * k + p) % p;
if(h[temp] == x) {
mprint(temp);
break;
} else if(h[temp] == -1) {
h[temp] = x;
strcpy(g[temp], str);
mprint(temp);
break;
}
k ++;
}
}
return 0;
}
7-75 航空公司VIP客户查询
不少航空公司都会提供优惠的会员服务,当某顾客飞行里程累积达到一定数量后,可以使用里程积分直接兑换奖励机票或奖励升舱等服务。现给定某航空公司全体会员的飞行记录,要求实现根据身份证号码快速查询会员里程积分的功能。
输入格式:
输入首先给出两个正整数N(≤105)和K(≤500)。其中K是最低里程,即为照顾乘坐短程航班的会员,航空公司还会将航程低于K公里的航班也按K公里累积。随后N行,每行给出一条飞行记录。飞行记录的输入格式为:18位身份证号码(空格)飞行里程。其中身份证号码由17位数字加最后一位校验码组成,校验码的取值范围为0~9和x共11个符号;飞行里程单位为公里,是(0, 15 000]区间内的整数。然后给出一个正整数M(≤105),随后给出M行查询人的身份证号码。
输出格式:
对每个查询人,给出其当前的里程累积值。如果该人不是会员,则输出No Info。每个查询结果占一行。
输入样例:
4 500
330106199010080419 499
110108198403100012 15000
120104195510156021 800
330106199010080419 1
4
120104195510156021
110108198403100012
330106199010080419
33010619901008041x
输出样例:
800
15000
1000
No Info
思路:
- 把每个人按照身份证号和里程总数储存在map里。
- 如果里程数低于 k ,则计入里程 k。
- map查询,ma.find() 找不到返回指向ma.end()的迭代器。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <map>
using namespace std;
const int N = 100010;
int n, k, m;
string id;
int x;
map<string, int> ma;
int main() {
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
cin >> n >> k;
for(int i = 0; i < n; i ++ ) {
cin >> id >> x;
if(x < k) x = k;
ma[id] += x;
}
cin >> m;
while(m -- ) {
cin >> id;
if(ma.find(id) == ma.end())
cout << "No Info" << endl;
else
cout << ma[id] << endl;
}
return 0;
}
7-76 打印选课学生名单
假设全校有最多40000名学生和最多2500门课程。现给出每个学生的选课清单,要求输出每门课的选课学生名单。
输入格式:
输入的第一行是两个正整数:N(≤40000),为全校学生总数;K(≤2500),为总课程数。此后N行,每行包括一个学生姓名(3个大写英文字母+1位数字)、一个正整数C(≤20)代表该生所选的课程门数、随后是C个课程编号。简单起见,课程从1到K编号。
输出格式:
顺序输出课程1到K的选课学生名单。格式为:对每一门课,首先在一行中输出课程编号和选课学生总数(之间用空格分隔),之后在第二行按字典序输出学生名单,每个学生名字占一行。
输入样例:
10 5
ZOE1 2 4 5
ANN0 3 5 2 1
BOB5 5 3 4 2 1 5
JOE4 1 2
JAY9 4 1 2 5 4
FRA8 3 4 2 5
DON2 2 4 5
AMY7 1 5
KAT3 3 5 4 2
LOR6 4 2 4 1 5
输出样例:
1 4
ANN0
BOB5
JAY9
LOR6
2 7
ANN0
BOB5
FRA8
JAY9
JOE4
KAT3
LOR6
3 1
BOB5
4 7
BOB5
DON2
FRA8
JAY9
KAT3
LOR6
ZOE1
5 9
AMY7
ANN0
BOB5
DON2
FRA8
JAY9
KAT3
LOR6
ZOE1
思路:
- 用二维数组储存每门课程的选择人名,用数组下标表示课程编号。
- 题目最后一个点会卡时间,用cout输出会超时,用peintf不会。
- 调用函数c_str(),string类型返回字符串首指针。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N = 40010;
int n, k, c, x;
string name;
vector<string> ve[2510];
int main() {
// ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
cin >> n >> k;
for(int i = 0; i < n; i ++ ) {
cin >> name >> c;
while(c -- ) {
cin >> x;
ve[x].push_back(name);
}
}
for(int i = 1; i <= k; i ++ ) {
cout << i << ' ' << ve[i].size() << endl;
sort(ve[i].begin(), ve[i].end());
for(int j = 0; j < ve[i].size(); j ++ ) {
printf("%s\n", ve[i][j].c_str());
}
}
return 0;
}
7-77 打印学生选课清单
假设全校有最多40000名学生和最多2500门课程。现给出每门课的选课学生名单,要求输出每个前来查询的学生的选课清单。
输入格式:
输入的第一行是两个正整数:N(≤40000),为前来查询课表的学生总数;K(≤2500),为总课程数。此后顺序给出课程1到K的选课学生名单。格式为:对每一门课,首先在一行中输出课程编号(简单起见,课程从1到K编号)和选课学生总数(之间用空格分隔),之后在第二行给出学生名单,相邻两个学生名字用1个空格分隔。学生姓名由3个大写英文字母+1位数字组成。选课信息之后,在一行内给出了N个前来查询课表的学生的名字,相邻两个学生名字用1个空格分隔。
输出格式:
对每位前来查询课表的学生,首先输出其名字,随后在同一行中输出一个正整数C,代表该生所选的课程门数,随后按递增顺序输出C个课程的编号。相邻数据用1个空格分隔,注意行末不能输出多余空格。
输入样例:
10 5
1 4
ANN0 BOB5 JAY9 LOR6
2 7
ANN0 BOB5 FRA8 JAY9 JOE4 KAT3 LOR6
3 1
BOB5
4 7
BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1
5 9
AMY7 ANN0 BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1
ZOE1 ANN0 BOB5 JOE4 JAY9 FRA8 DON2 AMY7 KAT3 LOR6
输出样例:
ZOE1 2 4 5
ANN0 3 1 2 5
BOB5 5 1 2 3 4 5
JOE4 1 2
JAY9 4 1 2 4 5
FRA8 3 2 4 5
DON2 2 4 5
AMY7 1 5
KAT3 3 2 4 5
LOR6 4 1 2 4 5
思路:
- 以名字为key,邻接表储存每个人选的课。
- 输出时排序一下选的课的顺序直接输出即可。
AC代码:
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
#include <map>
using namespace std;
const int N = 40010;
int n, k, c, x;
char name[20];
map<string, vector<int> > ma;
map<string, vector<int> >::iterator it;
int main() {
// ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
cin >> n >> k;
for(int i = 0; i < k; i ++ ) {
cin >> x >> c;
while(c -- ) {
cin >> name;
ma[name].push_back(x);
}
}
for(int i = 0; i < n; i ++ ) {
cin >> name;
int len = ma[name].size();
cout << name << ' ' << len;
sort(ma[name].begin(), ma[name].end());
for(int j = 0; j < len; j ++ ) {
cout << ' ' << ma[name][j];
}
cout << endl;
}
return 0;
}
7-78 Perfect Sequence
题目大意:
给定一个整数序列和一个数 p,从中选出一个子序列,如果该序列的最大值M小于等于最小值m乘p,则称他为完美序列。输出一个序列的完美子序列最长为多少。
Given a sequence of positive integers and another positive integer p. The sequence is said to be a "perfect sequence" if M≤m×p where M and m are the maximum and minimum numbers in the sequence, respectively.
Now given a sequence and a parameter p, you are supposed to find from the sequence as many numbers as possible to form a perfect subsequence.
Input Specification:
Each input file contains one test case. For each case, the first line contains two positive integers N and p, where N (≤105) is the number of integers in the sequence, and p (≤109) is the parameter. In the second line there are N positive integers, each is no greater than 109.
Output Specification:
For each test case, print in one line the maximum number of integers that can be chosen to form a perfect subsequence.
Sample Input:
10 8
2 3 20 4 5 1 6 7 8 9
Sample Output:
8
思路:
- 把读入的序列排序,从第一个数开始遍历,每次去找到小于等于该数p倍的最大的数的位置,与该数位置相减即为完美子序列的长度。
- 查找小于等于某数的最大的数用二分或者调用upper_bound(),lower_bound()。
- lower_bound(key) 返回 >=key值的第一个元素。
- upper_bound(key) 返回 >key 值的第一个元素。
AC代码:
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
const int N = 100010;
int n;
long long p, x;
long long ve[N];
//vector<long long> ve;
int erf(int i, long long x) {
if(ve[n - 1] <= x)
return n;
int l = i + 1, r = n - 1, mid;
while(l < r) {
mid = (l + r) / 2;
if(ve[mid] <= x) {
l = mid + 1;
} else {
r = mid;
}
}
return l;
}
int main() {
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
cin >> n >> p;
for(int i = 0; i < n; i ++ ) {
cin >> ve[i];
}
sort(ve, ve + n);
int res = 0;
for(int i = 0; i < n; i ++ ) {
int j = erf(i, ve[i] * p);
res = max(res, j - i);
}
cout << res << endl;
return 0;
}
7-81 两个有序序列的中位数
已知有两个等长的非降序序列S1, S2, 设计函数求S1与S2并集的中位数。有序序列A0,A1,⋯,A**N−1的中位数指A(N−1)/2的值,即第⌊(N+1)/2⌋个数(A0为第1个数)。
输入格式:
输入分三行。第一行给出序列的公共长度N(0<N≤100000),随后每行输入一个序列的信息,即N个非降序排列的整数。数字用空格间隔。
输出格式:
在一行中输出两个输入序列的并集序列的中位数。
输入样例1:
5
1 3 5 7 9
2 3 4 5 6
输出样例1:
4
输入样例2:
6
-100 -10 1 1 1 1
-50 0 2 3 4 5
输出样例2:
1
思路:
- 两个相等长度的有序序列,中位数即为两序列合并以后的第n个元素。
- 读入两个序列以后,用两个指针依次从0开始,循坏n次找到第n个数,直接输出即可。
AC代码:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010;
int n;
int a[N], b[N];
int main() {
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
cin >> n;
for(int i = 0; i < n; i ++ ) {
cin >> a[i];
}
for(int i = 0; i < n; i ++ ) {
cin >> b[i];
}
int i = 0, j = 0;
int res = a[0];
for(int k = 0; k < n; k ++ ) {
if(a[i] <= b[j]) {
res = a[i];
i ++ ;
} else {
res = b[j];
j ++ ;
}
}
cout << res << endl;
return 0;
}
7-83 顺序存储的二叉树的最近的公共祖先问题
设顺序存储的二叉树中有编号为i和j的两个结点,请设计算法求出它们最近的公共祖先结点的编号和值。
输入格式:
输入第1行给出正整数n(≤1000),即顺序存储的最大容量;第2行给出n个非负整数,其间以空格分隔。其中0代表二叉树中的空结点(如果第1个结点为0,则代表一棵空树);第3行给出一对结点编号i和j。
题目保证输入正确对应一棵二叉树,且1≤i,j≤n。
输出格式:
如果i或j对应的是空结点,则输出ERROR: T[x] is NULL,其中x是i或j中先发现错误的那个编号;否则在一行中输出编号为i和j的两个结点最近的公共祖先结点的编号和值,其间以1个空格分隔。
输入样例1:
15
4 3 5 1 10 0 7 0 2 0 9 0 0 6 8
11 4
输出样例1:
2 3
输入样例2:
15
4 3 5 1 0 0 7 0 2 0 9 0 0 6 8
12 8
输出样例2:
ERROR: T[12] is NULL
思路:
- 数组储存二叉树从1开始。
- 读入a,b两个结点的位置,下标大的肯于该小的结点不是同一个结点,开始循环找两个结点的父节点,如果相等则是答案,最后肯定会回到根节点。
AC代码:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1010;
int n, a, b;
int T[N];
int main() {
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
scanf("%d", &n);
for(int i = 1; i <= n; i ++ )
scanf("%d", &T[i]);
scanf("%d%d", &a, &b);
if(T[a] == 0 || T[b] == 0) {
if(!T[a]) {
printf("ERROR: T[%d] is NULL", a);
return 0;
} else {
printf("ERROR: T[%d] is NULL", b);
return 0;
}
} else {
if(a > b) {
while(a > b) {
a /= 2;
}
while(1) {
if(a == b) break;
b /= 2;
if(a == b) break;
a /= 2;
if(a == b) break;
}
} else if(a < b) {
while(a < b) {
b /= 2;
}
while(1) {
if(a == b) break;
a /= 2;
if(a == b) break;
b /= 2;
if(a == b) break;
}
}
}
printf("%d %d", a, T[a]);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号