
MySQL 普通索引和唯一索引的区别
该文为《 MySQL 实战 45 讲》的学习笔记,感谢查看,如有错误,欢迎指正
一、查询和更新上的区别
这两类索引在查询能力上是没差别的,主要考虑的是对更新性能的影响。建议尽量选择普通索引。
1.1 MySQL 的查询操作
- 普通索引
查找到第一个满足条件的记录后,继续向后遍历,直到第一个不满足条件的记录。 - 唯一索引
由于索引定义了唯一性,查找到第一个满足条件的记录后,直接停止继续检索。
普通索引会多检索一次,几乎没有影响。因为 InnoDB 的数据是按照数据页为单位进行读写的,需要读取数据时,并不是直接从磁盘读取记录,而是先把数据页读到内存,再去数据页中检索。
一个数据页默认 16 KB,对于整型字段,一个数据页可以放近千个 key,除非要读取的数据在数据页的最后一条记录,就需要再读一个数据页,这种情况很少,对CPU的消耗基本可以忽略了。
因此说,在查询数据方面,普通索引和唯一索引没差别。
1.2 MySQL 的更新操作
更新操作并不是直接对磁盘中的数据进行更新,是先把数据页从磁盘读入内存,再更新数据页。
- 普通索引
将数据页从磁盘读入内存,更新数据页。 - 唯一索引
将数据页从磁盘读入内存,判断是否唯一,再更新数据页。
由于 MySQL 中有个 change buffer 的机制,会导致普通索引和唯一索引在更新上有一定的区别。
change buffer的作用是为了降低IO 操作,避免系统负载过高。change buffer将数据写入数据页的过程,叫做merge。
如果需要更新的数据页在内存中时,会直接更新数据页;如果数据不在内存中,会先将更新操作记入change buffer,当下一次读取数据页时,顺带merge到数据页中,change buffer也有定期merge策略。数据库正常关闭的过程中,也会触发merge。
对于唯一索引,更新前需要判断数据是否唯一(不能和表中数据重复),如果数据页在内存中,就可以直接判断并且更新,如果不在内存中,就需要去磁盘中读出来,判断一下是否唯一,是的话就更新。change buffer是用不到的。即使数据页不在内存中,还是要读出来。
change buffer 用的是 buffer pool 里的内存,因此不能无限增大。change buffer 的大小,可以通过参数 innodb_change_buffer_max_size 来动态设置。这个参数设置为 50 的时候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。
结论:唯一索引用不了change buffer,只有普通索引可以用。
二、change buffer 和 redo log的区别
2.1 change buffer 的适用场景
change buffer 的作用是降低更新操作的频率,缓存更新操作。这样会有一个缺点,就是更新不及时,对于读操作比较频繁的表,不建议使用 change buffer。
因为更新操作刚记录进change buffer中,就读取了该表,数据页被读到了内存中,数据马上就merge到数据页中了。这样不仅不会降低性能消耗,反而会增加维护change buffer的成本。
适用于写多读少的表。
2.2 change buffer 和 redo log 区别
我们举一个例子用来理解 redo log 和 change buffer。我们执行以下 SQL 语句:
mysql> insert into t(id,k) values(id1,k1),(id2,k2);
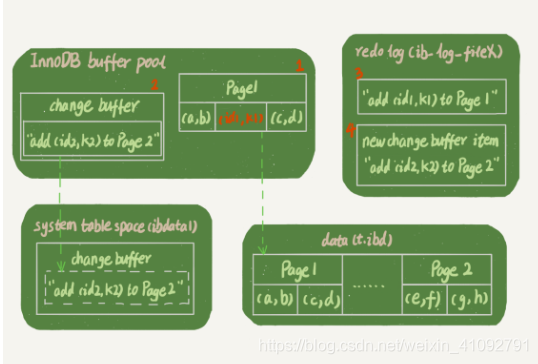
假设,(id1,k1) 在数据页 Page 1 中,(id2,k2) 在数据页 Page 2 中。并且 Page 1 在内存中,Page 2 不在内存中。
执行过程如下:
- 直接向 Page 1 中写入
(id1,k1); - 在
change buffer中记下"向 Page 2 中写入(id2,k2)"这条信息; - 将以上两个动作记入redo log。
做完上面这些,事务就可以完成了。执行这条更新语句的成本很低,就是写了两处内存,然后写了一处磁盘(两次操作合在一起写了一次磁盘),而且还是顺序写的。
这条更新语句,涉及了四个部分:内存、redo log(ib_log_fileX)、 数据表空间(t.ibd)、系统表空间(ibdata1)。
如果要读数据的话,过程是怎样的?
mysql> select * from t where k in (k1, k2);
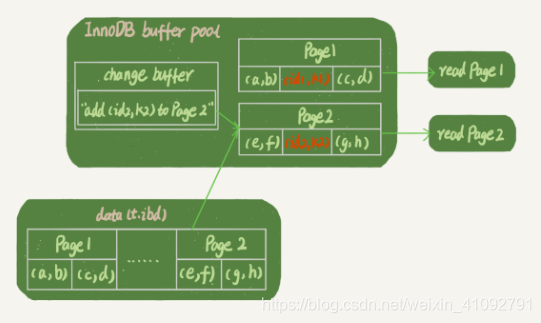
假设读操作在更新后不久,此时内存中还有 Page 1,没有 Page 2,那么读操作就和 redo log 以及 ibdata1 无关了。
- 从内存中获取到 Page 1 上的最新数据
(id1,k1); - 将数据页 Page 2 读入内存,执行
merge操作,此时内存中的 Page 2 也有最新数据(id2,k2);
需要注意的是:
- redo log中的数据,可能还没有 flush 到磁盘,磁盘中的 Page 1 和 Page 2 中并没有最新数据,但我们依然可以拿到最新数据(内存中的 Page 1 就是最新的,Page 2 虽然不是最新的,但是从磁盘读到内存中后,执行了
merge操作,内存中的 Page 2 就是最新的了。) - 如果此时 MySQL 异常宕机了,比如服务器异常掉电,change buffer 中的数据会不会丢?
change buffer中的数据分为两部分,一部分是已经merge到ibdata1中的数据,这部分数据已经持久化,不会丢失。另一部分数据,还在change buffer中,没有merge到ibdata1,分 3 种情况:
(1)change buffer 写入数据到内存,redo log 也已经写入(ib-log-filex),但是未commit,binlog中也没有fsync到磁盘,这部分数据会丢失;
(2)change buffer 写入数据到内存,redo log 也已经写入(ib-log-filex),但是未commit,binlog 已写入到磁盘,这部分不会多丢失,异常重启后会先从 binlog 恢复 redo log,再从 redo log 恢复 change buffer;
(3)change buffer 写入数据到内存,redo log 和 binlog 都已经fsync,直接从redo log 恢复,不会丢失。
redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写),而 change buffer 主要节省的则是随机读磁盘的 IO 消耗
感谢阅读,有兴趣的小伙伴可以关注我的微信公众号DevOps探索之旅,大家一起学习进步


