scrapy搭建
中文文档
https://docs.pythontab.com/scrapy/scrapy0.24/index.html
一、scrapy运行原理
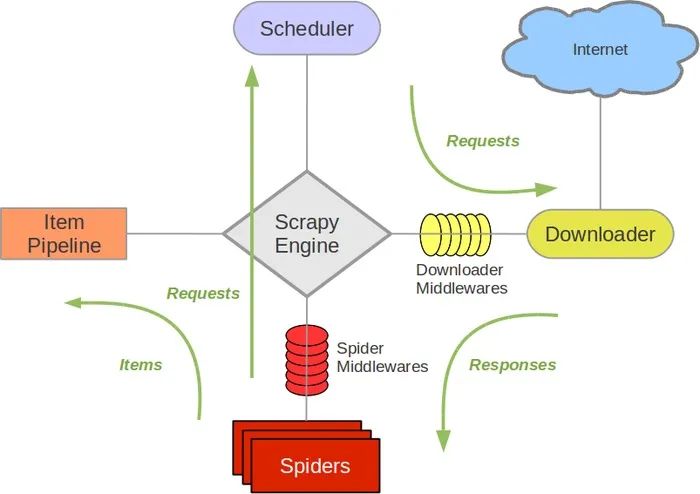
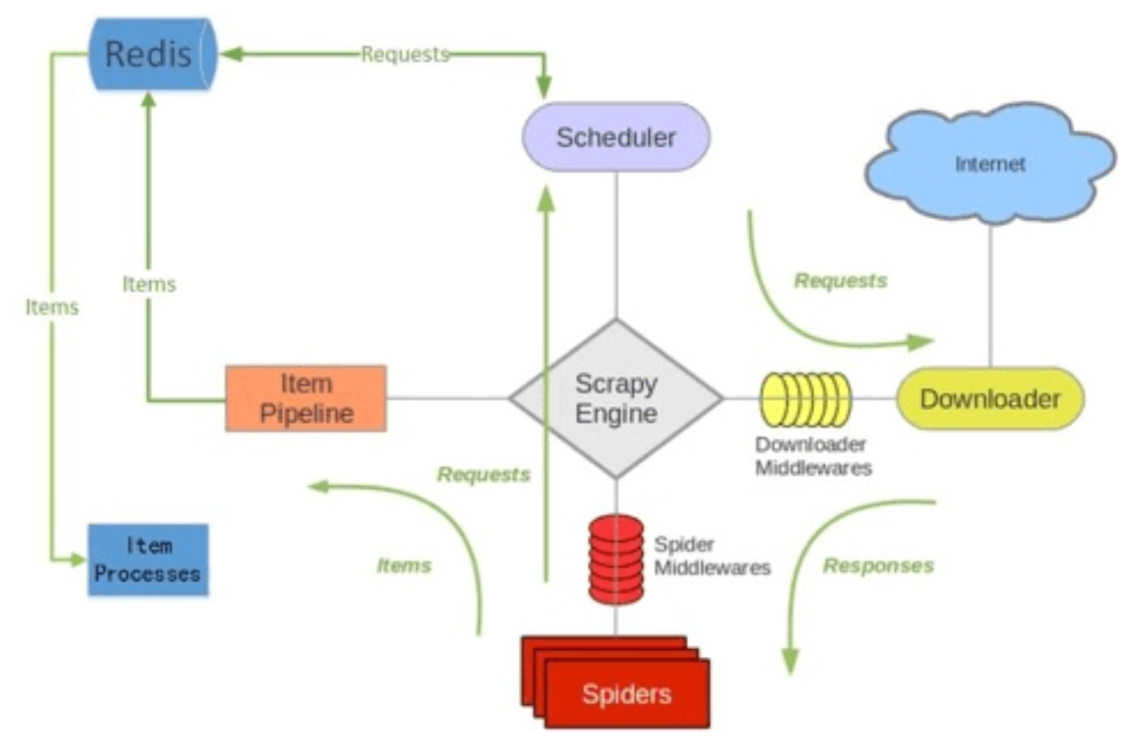
执行顺序
############# [ 下载中间件: from_crawler方法创建爬虫 ] #############
############# [ 爬虫中间件: from_crawler方法创建爬虫 ] #############
############# [ 下载中间件: 爬虫启动时引擎调用spider_opened方法 ] #############
############# [ 爬虫中间件: 爬虫启动时引擎调用spider_opened方法 ] #############
############# [ 爬虫中间件: process_start_requests方法处理最开始的start_urls的请求 ] #############
############# [ 下载中间件: process_request方法处理请求对象,为请求对象加添加header信息 ] #############
############# [ 下载中间件: process_response方法处理响应 ] #############
############# [ 爬虫中间件: process_spider_input方法对响应体对象进行修饰 ] #############
############# [ 爬虫中间件: process_spider_output方法处理爬虫输出到下一步的管道 ] #############
############# [ 进入ItemPipeline管道: 处理数据并输出到目标位置 ] #############
Scrapy主要有以下组件:
- 引擎(Scrapy Engine)
- Item 项目
- 调度器(Scheduler)
- 下载器(Downloader)
- 爬虫(Spiders)
- 项目管道(Pipeline)
- 下载器中间件(Downloader Middlewares)
- 爬虫中间件(Spider Middlewares)
- 调度中间件(Scheduler Middewares)
二、工程搭建流程
1、创建一个爬虫专用的解析器环境,用于存放爬虫相关的依赖包
2、新建爬虫项目
# 会在当前目录下初始化工程
scrapy startproject 工程名
3、生成一个爬虫
# 1.在爬虫工程下初始化一个基于通用爬虫模板的爬虫
cd 工程名
scrapy genspider one "one.cn"
# 2.指定爬虫模板生成爬虫,-t指定生成模板
scrapy genspider -t crawl two two.com
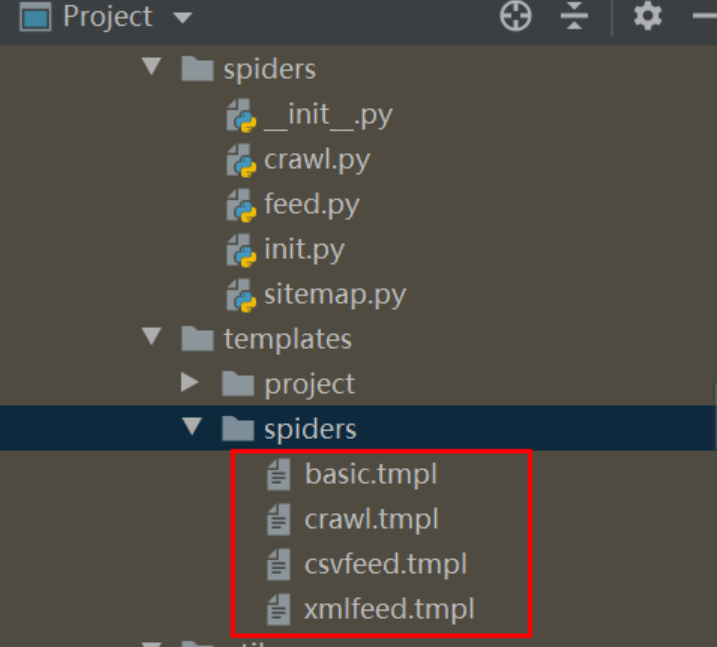
4、打开工程,配置虚拟解释器环境
5、在命令中运行爬虫scrapy crawl 爬虫名(指的是步骤3中的one)
5.1、在pycharm中运行爬虫
【新建run.py】
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy import cmdline
if __name__ == '__main__':
cmdline.execute("scrapy crawl demo".split())
6、调试
方式一:scrapy shell http://www.aepu.com.cn/html/929/
方式二:pythonCharm中打断点然后在console中直接输入py代码进行调试(推荐)
三、数据抓取步骤
爬虫框架的具体使用步骤如下:
- 选择目标网站
- 定义要抓取的数据(通过Scrapy Items来完成的)
- 编写提取数据的spider
- 执行spider,获取数据
- 数据存储
四、 目录文件说明
当我创建了一个scrapy项目后,继续创建了一个spider,目录结构是这样的:
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
projectname/ :项目的Python模块,将会从这里引用代码
projectname/items.py :项目的目标文件
projectname/pipelines.py :项目的管道文件
projectname/settings.py :项目的设置文件
projectname/spiders/ :存储爬虫代码目录
五、基础配置修改
【settings.py】
# 不遵守机器人规则
ROBOTSTXT_OBEY = False
# 添加user-agent请求头用户代理(基本反爬措施)
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
# 禁用cookies
COOKIES_ENABLED = False
# 关闭telnet连接
TELNETCONSOLE_ENABLED = False
# 配置延迟下载(生产环境一般会开开,还有极限算法也要开开)
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 16
六、下载中间件
# 随机user-agent库,在下载中间件中使用
https://pypi.org/project/user-agent2/
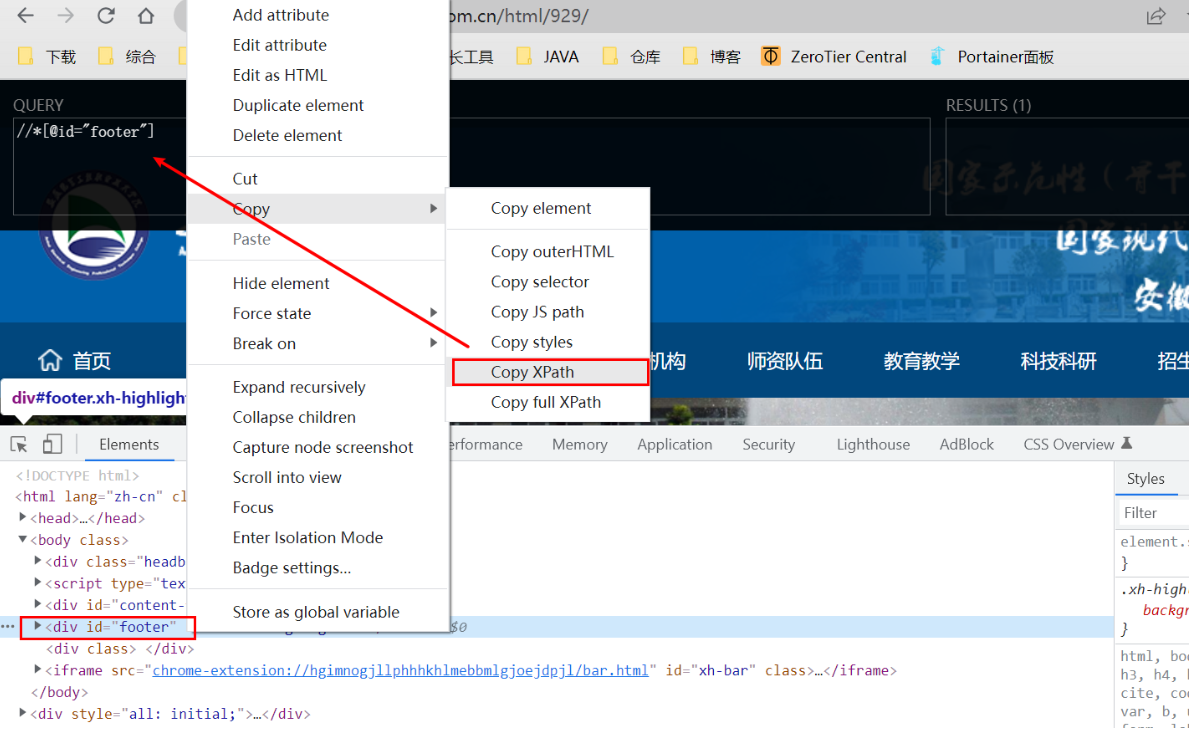
七、数据提取XPath
使用chrome浏览器 + XPath Helper浏览器插件
参考文档:
阿里云盘里面的爬虫资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号