第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程2024 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 完成个人项目,实现对论文查重 |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 120 | 150 |
| Development | 开发 | 300 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 40 | 10 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 300 | 540 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 90 | 30 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1250 | 2000 |
一、需求分析
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
分析:
需要从指定文件中获取两篇文本进行比较,然后将比较结果输出到指定文件里
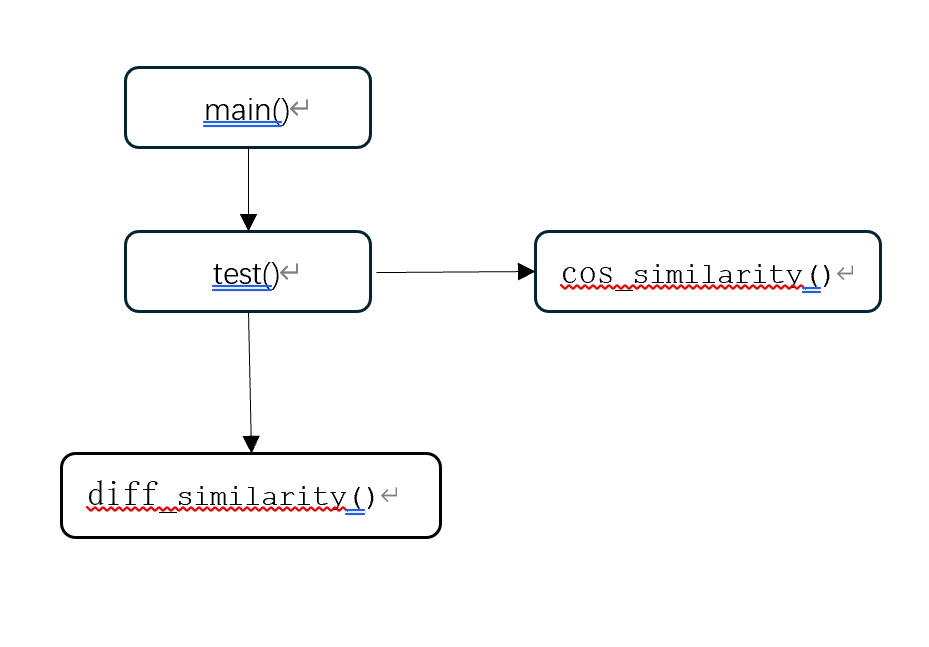
二、程序函数接口和调用关系:
| 函数 | 功能和实现 |
|---|---|
| main | 调用测试函数 |
| test[] | 调用diff_simularity函数和cos_simularity函数比较文档与句子的相似度 |
| diff_simularity | 利用difflib.SequenceMatcher()比较两个文档的相似度 |
| cos_simularity | 利用余弦相似度比较两个文档相似度 |
函数调用关系图:
三、算法关键:
1、利用python中的jieba库将两段文字分词,计算词频,通过余弦相似度公式计算结果
2、利用python中现成的difflib.SequenceMatcher()比较文档相似度
独到之处:
对于字数较长的文档比较,余弦相似度的结果误差较大,而SequenceMatcher的基本思想是找到不包含垃圾元素的最长连续匹配子序列,将两者结果取均值,可以让结果更精准
四、算法性能与改进:
1、刚开始了解到用余弦相似度算法可以比较文本的相似度,但是在测试时发现由于文档字数较长,产生了较大的误差。于是试着改进算法,了解到了python中的difflib库中也提供了比较文本相似度的方法SequenceMatcher,所以想着把两个方法得到的结果取均值,从而得到更准确的相似度。
2、由于我用的是pycharm社区版,没有profile工具,测试不了代码的性能,所以代码性能这部分没能完成。
五、单元测试:
构建测试数据的思路:
将查重分为长文本和短文本比较,长文本测试数据采用了给定的文本文件;而短文本测试数据思路是比较原语句和增删改后的句子以及单纯符号句子,最终将结果送入指定文件result.txt中。
部分测试用例:
1.缩减抄袭版测试:

测试结果:相似度:0.88
2.增改抄袭版测试:

测试结果:相似度:0.96
3.非抄袭版测试:

测试结果:相似度:0.25
4.纯符号版测试:

测试结果:相似度:0.43
总结:
这几天为了完成第一次个人项目,学习了很多新知识,比如学会了使用psp表格,还有学会了在github管理自己的代码,以及熟悉完成一个项目的流程,但是因为有很多知识从未接触过,项目整体完成度不够完整。尽管如此,我认为重要的不只是结果,更在于过程中收获了什么,所以我对能收获对以后的工作有用的经验感到充实。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号