python json数据的转换和jsonpath的使用
一、Json模块
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它是的人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON和XML的比较可谓不相上下
1、json结构:对象和数组
- 对象:对象在js中表示为{}括起来的内容,数据结构为{key:value,key:value,...}的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为对象.key获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。
- 数组:数组在js中是中括号[]括起来的内容,数据结构为["Python", "javascript", "C++",..],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是数字、字符串、数组、对象几种。
2、json数据的转换
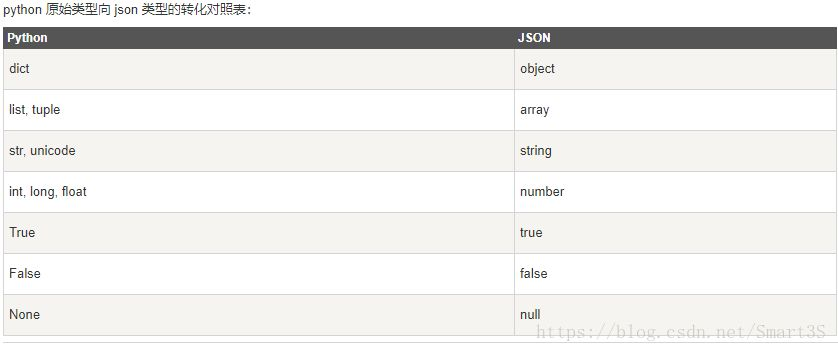
- **不能使用dict将json字符串转换为字典
- **不能使用eval将json字符串转换为字典,json中的null在python中无法识别,会当成变量处理
- loads():将json字符串转换为python类型的,或自动将null转换为None
- dumps():将python类型的数据转换为json字符串,会自动将None转换为null
data = {"name": "ming", "id": 18, "msg": None}
json_data = '{"name":"Tom","id":19,"msg":null}'
json.loads()将json字符串转换为python类型的,或自动将null转换为None
resp = json.loads(json_data) print(type(resp), resp) #(<type 'dict'>, {u'msg': None, u'name': u'json', u'id': 19})
json.load() 读取文件中json形式的字符串元素转化成python类型
strList = json.load(open("listStr.json")) print(type(strList), strList) #(<type 'list'>, [{u'city': u'\u5317\u4eac'}, {u'name': u'python_list'}]) strDict = json.load(open("dictStr.json")) print(type(strDict), strDict) #(<type 'dict'>, {u'city': u'\u5317\u4eac', u'name': u'python_dict'})
json.dumps() 将python类型的数据转换为json字符串,会自动将None转换为null
req = json.dumps(data) print(type(req),req) # (<type 'str'>, '{"msg": null, "name": "python", "id": 18}')
json.dump() 将Python内置类型序列化为json对象后写入文件
listStr = [{"city": "北京"}, {"name":"python_list"}]
json.dump(listStr, open("listStr.json", "w"), ensure_ascii=False)
dictStr = {"city": "北京", "name":"python_dict"}
json.dump(dictStr, open("dictStr.json", "w"), ensure_ascii=False)
二,jsonpath
- JSONPath表达式始终以与XPath表达式与XML文档结合使用的相同方式引用JSON结构。由于JSON结构通常是匿名的,并且不一定具有“根成员对象”,因此JSONPath假定$分配给外部对象的抽象名称。[摘自官方文档]
- JSONPath表达式可以使用点号-表示法:$.store.book[0].title
- 括号符号:$['store']['book'][0]['title']
- JSONPath允许通配符 *表示成员名称和数组索引
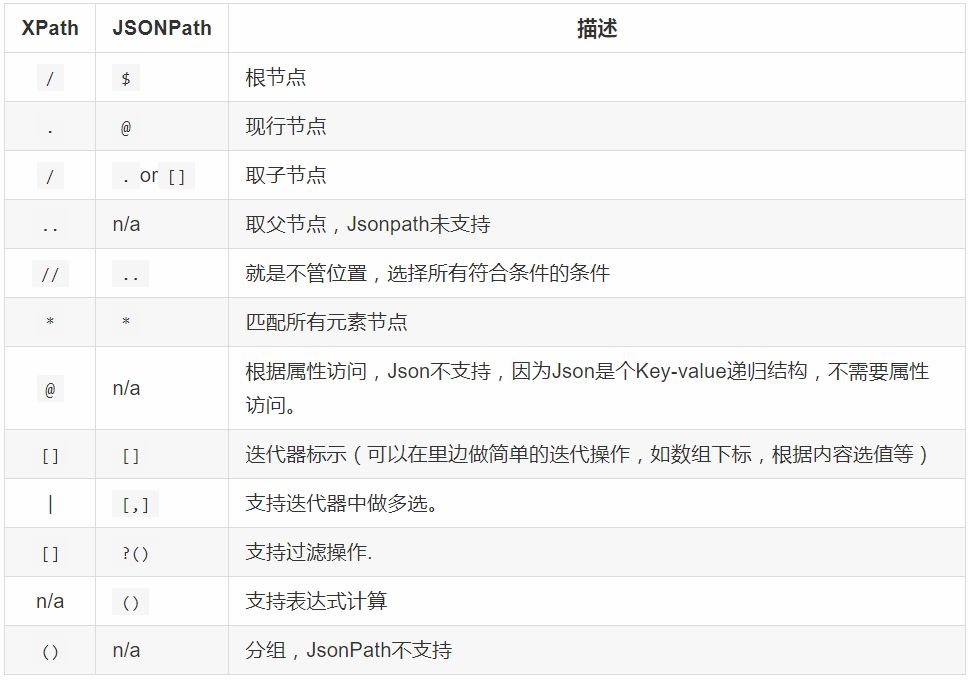
JsonPath与XPath语法对比:
案例:

import jsonpath # 数据源: json_data = { "store": { "book": [ { "category": "reference", "author": "李白", "title": "Sayings of the Century", "price": 8.95 }, { "category": "fiction", "author": "杜甫", "title": "Sword of Honour", "price": 12.99 }, { "category": "fiction", "author": "白居易", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "fiction", "author": "苏轼", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } } } # 普通取值需要先看json数据,找到uname节点,如果没有就会报错 data1 = json_data["store"]["bicycle"]['color'] print(data1) #"red" # jsonpath取值不需要看json数据,直接通过..(..就表示全局检索后面跟的属性)全局搜索uname属性,如果没有返回FALSE data2 = jsonpath.jsonpath(json_data, "$..color") print(data2) #["red"] data3 = jsonpath.jsonpath(json_data, "$.store.bicycle.color") print(data3) #["red"] datas = jsonpath.jsonpath(json_data, "$..author") print(datas) #['李白', '杜甫', '白居易', '苏轼']

注意事项:
json.loads()是把Json格式字符串解码转换成Python对象,如果在json.loads的时候出错,要注意被解码的Json字符的编码。
如果传入的字符串的编码不是UTF-8的话,需要制定字符编码的参数:encoding
dataDict = json.loads(jsonStrGBK);
- dataJsonStr是JSON字符串,假设其编码本身是非UTF-8的话而是GBK的,那么上述代码会导致出错,改为对应的。
dataDict = json.loads(jsonStrGBK, encoding="GBK")
- 如果dataJsonStr通过encoding指定了合适的编码,但是其中又包含了其它编码的字符,则需要先去将dataJsonStr转换为Unicode,然后再指定编码格式调用json.loads()
dataJsonStrUni = data.JsonStr.decode("GB2312") dataDict = json.loads(dataJsontrUni, encoding="GB2312")
字符串编码转换
这是程序员最苦逼的地方,什么乱码之类的几乎都是由汉字引起的。
其实编码问题很好搞定,只要记住一点:任何平台的任何编码,都能和Unicode互相转换。
UTF-8与GBK互相转换,那就先把UTF-8转换成Unicode,再从Unicode转换成GBK,反之同理。
# 这是一个 UTF-8 编码的字符串 utf8Str = "你好地球" # 1. 将 UTF-8 编码的字符串 转换成 Unicode 编码 unicodeStr = utf8Str.decode("UTF-8") # 2. 再将 Unicode 编码格式字符串 转换成 GBK 编码 gbkData = unicodeStr.encode("GBK") # 1. 再将 GBK 编码格式字符串 转化成 Unicode unicodeStr = gbkData.decode("gbk") # 2. 再将 Unicode 编码格式字符串转换成 UTF-8 utf8Str = unicodeStr.encode("UTF-8")
decode的作用是将其它编码的字符串转换成Unicode编码encode的作用是将Unicode编码转换成其他编码的字符串
感谢https://www.cnblogs.com/miqi1992/p/8081244.html
感谢https://www.cnblogs.com/miqi1992/p/8081244.html
分类:
python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现