python openpyxl使用和pandas写入表格
该文档只浅谈一下openpyxl对表格的基本操作,值得注意的是openpyxl只支持xlsx格式
一,openpyxl的安装
pip install openpyxl
二,openpyxl对表格各个名称的简介
Workbook:指一个工作簿,也就是一个单独的XLSX文件:


三,openpyxl使用
推荐读文件的时候使用只读模式,速度会快很多;不建议使用可读写模式操作xlsx文件,慢的很;读和写分开会好一些
1,创建不存在的表格
from openpyxl import Workbook # 实例化 wb = Workbook(‘文件名称.xlsx’) # 激活 worksheet 默认是新建床表格成功时sheet表 ws = wb.activewb.save('文件名称.xlsx')#保存数据
2,打开已经存在
import os import openpyxl file_path = os.path.abspath(os.path.join(os.path.dirname(__file__),'text.xlsx')) #以只读的模式打开已有的表格 wb = openpyxl.load_workbook(file_path,read_only=True)
3,创建sheet表
# 方式一:插入到最后(默认) ws1 = wb.create_sheet("Mysheet1") # 方式二:插入到最开始的位置 ws2 = wb.create_sheet("Mysheet2", 0)
4,查看sheet表
# 显示所有表名 print(wb.sheetnames) ['Mysheet2', 'Sheet', 'Mysheet1'] # 遍历所有表 for sheet in wb: ... print(sheet.title)
5,选择sheet表
# sheet 名称可以作为 key 进行索引 #方式一:推荐方式一 ws2 = wb["sheetname"] #方式二: ws1 = wb.get_sheet_by_name("sheetname")
6,添加数据
ws = wb["Mysheet2"]
# 第一行输入 ws.append(['A1', 'B1', 'C1']) # 输入内容(10行数据) for i in range(10): A1= datetime.datetime.now().strftime("%H:%M:%S") B1= str(time()) C1= get_column_letter(choice(range(1, 10))) ws.append([TIME, TITLE, A_Z])

7,获取excel表格的sheet1表格的行数与列数
ws = wb['Mysheet2'] # 获取最大行 row_max = ws.max_row # 获取最大列 con_max = ws.max_column #获取所有工作行内容 rows = ws.rows #获取所有工作列内容 columns = ws.columns
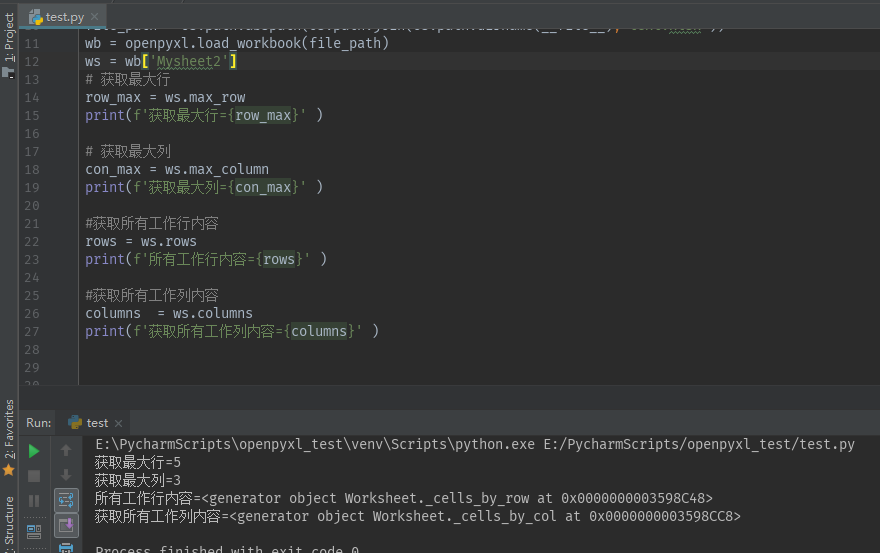
8,获取每一行,每一列
sheet.rows为生成器, 里面是每一行的数据,每一行又由一个tuple包裹。 sheet.columns类似,不过里面是每个tuple是每一列的单元格。 # 因为按行,所以返回A1, B1, C1这样的顺序 for row in sheet.rows: for cell in row: print(cell.value) # A1, A2, A3这样的顺序 for column in sheet.columns: for cell in column: print(cell.value)
9,单元格访问和赋值
- 单一单元格访问
# 方法一 c = ws['A4'].value # 方法二:row 行;column 列 c = ws.cell(row=4, column=2).value #赋值 # 方法一 ws['A4'] = 5 # 方法二:row 行;column 列 ws.cell(row=4, column=2,value=5)
- 多单元格访问
# 通过切片 cell_range = ws['A1':'C2'] # 通过行(列) colC = ws['C'] col_range = ws['C:D'] #第几行 row10 = ws[10] row_range = ws[5:10] # 通过指定范围(行 → 行) for row in ws.iter_rows(min_row=1, max_col=3, max_row=2): for cell in row: print(cell) <Cell Sheet1.A1> <Cell Sheet1.B1> <Cell Sheet1.C1> <Cell Sheet1.A2> <Cell Sheet1.B2> <Cell Sheet1.C2> # 通过指定范围(列 → 列) for row in ws.iter_rows(min_col=1, max_row=2, max_col=3):: for cell in row: print(cell) <Cell Sheet1.A1> <Cell Sheet1.B1> <Cell Sheet1.C1> <Cell Sheet1.A2> <Cell Sheet1.B2> <Cell Sheet1.C2>
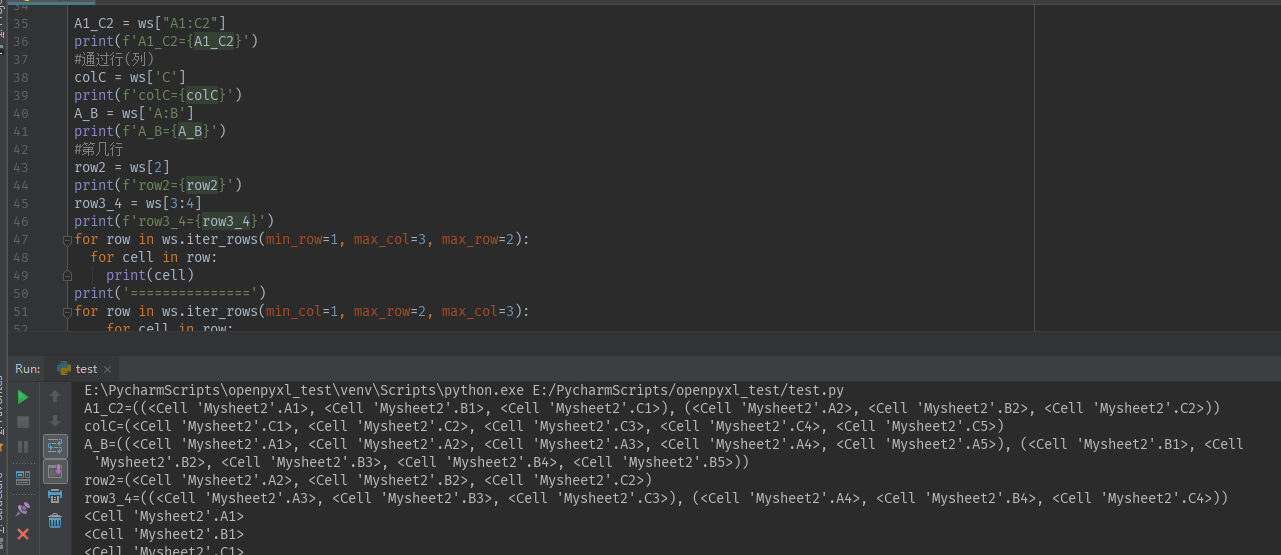
10, 删除工作表
# 方式一 wb.remove(sheet) # 方式二 del wb[sheet]
11, 删除行或者列
注意,删除行或者列后,后面的行或者列会自动往前填充,也就是说,删除第一列,原来的第二列就会变成第一列
1) 删除列 delete_cols()
import os import openpyxl file_path = os.path.abspath(os.path.join(os.path.dirname(__file__), os.pardir,'test.xlsx')) wb = openpyxl.load_workbook(file_path) ws = wb['sheet'] print('#原始数据') for i in ws.values: print(i) print('#删除列') ws.delete_cols(1) for i in ws.values: print(i)
执行结果:
('a', 'b', 'c', 'd') (1, 2, 3, 4) (5, 6, 7, 8) (9, 10, 11, 12) (13, 14, 15, 16) #删除列 ('b', 'c', 'd') (2, 3, 4) (6, 7, 8) (10, 11, 12) (14, 15, 16)
2)删除行 delete_rows()
import os import openpyxl file_path = os.path.abspath(os.path.join(os.path.dirname(__file__), os.pardir,'test.xlsx')) wb = openpyxl.load_workbook(file_path) ws = wb['sheet'] print('#原始数据') for i in ws.values: print(i) print('#删除行') ws.delete_rows(2) for i in ws.values: print(i)
执行结果:
#原始数据 ('a', 'b', 'c', 'd') (1, 2, 3, 4) (5, 6, 7, 8) (9, 10, 11, 12) (13, 14, 15, 16) #删除行 ('a', 'b', 'c', 'd') (5, 6, 7, 8) (9, 10, 11, 12) (13, 14, 15, 16)
12:ws转成pandas
file_path = os.path.abspath(os.path.join(os.path.dirname(__file__),os.pardir,'Data/test_data.xlsx')) wb = openpyxl.load_workbook(file_path) ws = wb['Sheet1'] df = pd.DataFrame(ws.values) print(df)
执行结果:
0 1 2 3
0 A B C D
1 1a b 3 4
2 2 c 4 5
3 3 d 5 6
4 4 e 6 7
5 5 f 7 8
1)pandas转成ws
file_path = os.path.abspath(os.path.join(os.path.dirname(__file__),os.pardir,'Data/test_data.xlsx')) wb = openpyxl.load_workbook(file_path) ws = wb['Sheet1'] df = pd.DataFrame(ws.values) print(f"#原始数据\n{df}") for i in df.values: ws.append(i.tolist()) for i in ws.rows: for j in i: print(j, j.value, end=',')
执行结果:
#原始数据 0 1 2 3 0 A B C D 1 1a b 3 4 2 2 c 4 5 3 3 d 5 6 4 4 e 6 7 5 5 f 7 8 <Cell 'Sheet1'.A1> A,<Cell 'Sheet1'.B1> B,<Cell 'Sheet1'.C1> C,<Cell 'Sheet1'.D1> D,
<Cell 'Sheet1'.A2> 1a,<Cell 'Sheet1'.B2> b,<Cell 'Sheet1'.C2> 3,<Cell 'Sheet1'.D2> 4,
<Cell 'Sheet1'.A3> 2,<Cell 'Sheet1'.B3> c,<Cell 'Sheet1'.C3> 4,<Cell 'Sheet1'.D3> 5,
<Cell 'Sheet1'.A4> 3,<Cell 'Sheet1'.B4> d,<Cell 'Sheet1'.C4> 5,<Cell 'Sheet1'.D4> 6,
<Cell 'Sheet1'.A5> 4,<Cell 'Sheet1'.B5> e,<Cell 'Sheet1'.C5> 6,<Cell 'Sheet1'.D5> 7,
<Cell 'Sheet1'.A6> 5,<Cell 'Sheet1'.B6> f,<Cell 'Sheet1'.C6> 7,<Cell 'Sheet1'.D6> 8,
<Cell 'Sheet1'.A7> A,<Cell 'Sheet1'.B7> B,<Cell 'Sheet1'.C7> C,<Cell 'Sheet1'.D7> D,
<Cell 'Sheet1'.A8> 1a,<Cell 'Sheet1'.B8> b,<Cell 'Sheet1'.C8> 3,<Cell 'Sheet1'.D8> 4,
<Cell 'Sheet1'.A9> 2,<Cell 'Sheet1'.B9> c,<Cell 'Sheet1'.C9> 4,<Cell 'Sheet1'.D9> 5,
<Cell 'Sheet1'.A10> 3,<Cell 'Sheet1'.B10> d,<Cell 'Sheet1'.C10> 5,<Cell 'Sheet1'.D10> 6,
<Cell 'Sheet1'.A11> 4,<Cell 'Sheet1'.B11> e,<Cell 'Sheet1'.C11> 6,<Cell 'Sheet1'.D11> 7,
<Cell 'Sheet1'.A12> 5,<Cell 'Sheet1'.B12> f,<Cell 'Sheet1'.C12> 7,<Cell 'Sheet1'.D12> 8, Process finished with exit code 0
13:合并单元格
#方法一 ws.merge_cells("A1:B1") #方式二 ws.merge_cells(start_column=3,end_column=6,start_row=2,end_row=3)
14:样式设置
14.1)颜色
Color(index=0) # 根据索引进行填充 # Color(rgb='00000000') # 根据rgb值进行填充 # index COLOR_INDEX = ( '00000000', '00FFFFFF', '00FF0000', '0000FF00', '000000FF', #0-4 '00FFFF00', '00FF00FF', '0000FFFF', '00000000', '00FFFFFF', #5-9 '00FF0000', '0000FF00', '000000FF', '00FFFF00', '00FF00FF', #10-14 '0000FFFF', '00800000', '00008000', '00000080', '00808000', #15-19 '00800080', '00008080', '00C0C0C0', '00808080', '009999FF', #20-24 '00993366', '00FFFFCC', '00CCFFFF', '00660066', '00FF8080', #25-29 '000066CC', '00CCCCFF', '00000080', '00FF00FF', '00FFFF00', #30-34 '0000FFFF', '00800080', '00800000', '00008080', '000000FF', #35-39 '0000CCFF', '00CCFFFF', '00CCFFCC', '00FFFF99', '0099CCFF', #40-44 '00FF99CC', '00CC99FF', '00FFCC99', '003366FF', '0033CCCC', #45-49 '0099CC00', '00FFCC00', '00FF9900', '00FF6600', '00666699', #50-54 '00969696', '00003366', '00339966', '00003300', '00333300', #55-59 '00993300', '00993366', '00333399', '00333333', #60-63 ) BLACK = COLOR_INDEX[0] WHITE = COLOR_INDEX[1] RED = COLOR_INDEX[2] DARKRED = COLOR_INDEX[8] BLUE = COLOR_INDEX[4] DARKBLUE = COLOR_INDEX[12] GREEN = COLOR_INDEX[3] DARKGREEN = COLOR_INDEX[9] YELLOW = COLOR_INDEX[5] DARKYELLOW = COLOR_INDEX[19]
14.2)字体
from openpyxl.styles import Font,Color ws.cell(5,3).value='哈哈哈' ws.cell(5,3).font = Font(name='仿宋',size=12,color=Color(index=0),b=True,i=True) # size sz 字体大小 # b bold 是否粗体 # i italic 是否斜体 # name family 字体样式
14.3)边框
- 边
from openpyxl.styles import Side,Color
Side(style='thin',color=Color(index=0)) # style可选项 style = ('dashDot','dashDotDot', 'dashed','dotted', 'double','hair', 'medium', 'mediumDashDot', 'mediumDashDotDot', 'mediumDashed', 'slantDashDot', 'thick', 'thin') # 'medium' 中粗 # 'thin' 细 # 'thick' 粗 # 'dashed' 虚线 # 'dotted' 点线
Border(left=Side(), right=Side(), top=Side(), bottom=Side()) ws.cell(3,3).border = Border()
- 填充
from openpyxl.styles import PatternFill,Color PatternFill(patternType='solid',fgColor=Color(), bgColor=Color()) # fgColor 前景色 # bgColor 后景色 # 参数可选项 patternType = {'darkDown', 'darkUp', 'lightDown', 'darkGrid', 'lightVertical', 'solid', 'gray0625', 'darkHorizontal', 'lightGrid', 'lightTrellis', 'mediumGray', 'gray125', 'darkGray', 'lightGray', 'lightUp', 'lightHorizontal', 'darkTrellis', 'darkVertical'} ws.cell(3,3).fill = PatternFill()
- 对齐
from openpyxl.styles import Alignment Alignment(horizontal='fill',vertical='center') # 参数可选项 horizontal = {'fill', 'distributed', 'centerContinuous', 'right', 'justify', 'center', 'left', 'general'} vertical = {'distributed', 'justify', 'center', 'bottom', 'top'} ws.cell(3,3).alignment= Alignment()
四 pandas 写入表格
import pandas as pd id =['1','2'] width_man=['12','18'] height_man=['20','55'] age_man=['10','12'] width_woman=['15','11'] height_woman=['40','45'] age_woman=['11','15'] df = pd.DataFrame({'ID': id, 'WIDTH': width_man, 'HEIGHT': height_man, 'AGE': age_man, 'WIDTH': width_woman, 'HEIGHT': height_woman, 'AGE': age_woman,}) df.to_excel('table.xlsx', sheet_name='sheet', index=False)
参考:
https://blog.csdn.net/weixin_41546513/article/details/109555832

 浙公网安备 33010602011771号
浙公网安备 33010602011771号