python flask框架配置mysql数据库以及SQLAlchemy对数据库的操作
本人是一个没有做笔记习惯的低级程序员,但是我还是喜欢编程,最近发现自己的记忆力严重的下降,原来自己学过的东西过段差不多都忘记了,现在才想起用博客记录一下,方便以后自己查看,同时也是为了能更好的提高自己的能力。最近在学习flask框架和mysql,所以再此总结一下。
一 flask框架mysql文件
通过看别的大佬的项目最常见的配置mysql就是
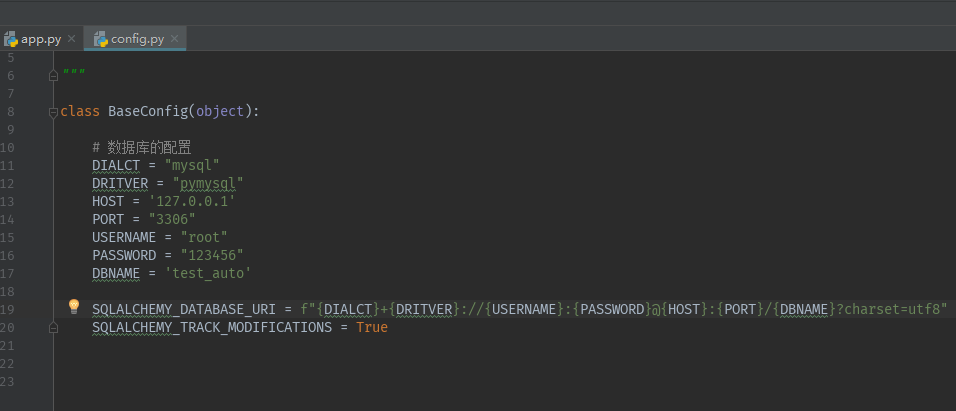
1)创建一个config.py文件
class BaseConfig(object): # 数据库的配置 DIALCT = "mysql" DRITVER = "pymysql" HOST = '127.0.0.1' PORT = "3306" USERNAME = "root" PASSWORD = "123456" DBNAME = 'test_auto' SQLALCHEMY_DATABASE_URI = f"{DIALCT}+{DRITVER}://{USERNAME}:{PASSWORD}@{HOST}:{PORT}/{DBNAME}?charset=utf8" SQLALCHEMY_TRACK_MODIFICATIONS = True
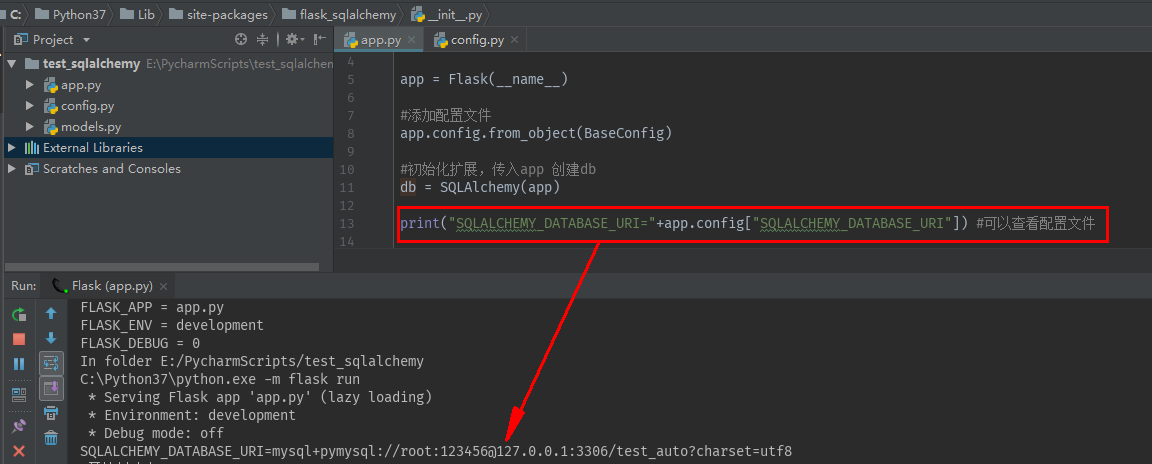
2)导入config文件 通过app.config添加配置文件
from flask import Flask from config import BaseConfig from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) #添加配置文件 app.config.from_object(BaseConfig) #初始化扩展,传入app 创建db db = SQLAlchemy(app)
3 )config.py配置文件
SQLALCHEMY_DATABASE_URI 以及SQLALCHEMY_TRACK_MODIFICATIONS注意不要写错 这些变量可以在\Python37\Lib\site-packages\flask_sqlalchemy\__init__.py目录下查看SQLAlchemy的默认配置文件 和\Python37\Lib\site-packages\flask\app.py目录下查看config的默认配置文件
app.config的默认配置文件
default_config = ImmutableDict( { "ENV": None, "DEBUG": None, "TESTING": False, "PROPAGATE_EXCEPTIONS": None, "PRESERVE_CONTEXT_ON_EXCEPTION": None, "SECRET_KEY": None, "PERMANENT_SESSION_LIFETIME": timedelta(days=31), "USE_X_SENDFILE": False, "SERVER_NAME": None, "APPLICATION_ROOT": "/", "SESSION_COOKIE_NAME": "session", "SESSION_COOKIE_DOMAIN": None, "SESSION_COOKIE_PATH": None, "SESSION_COOKIE_HTTPONLY": True, "SESSION_COOKIE_SECURE": False, "SESSION_COOKIE_SAMESITE": None, "SESSION_REFRESH_EACH_REQUEST": True, "MAX_CONTENT_LENGTH": None, "SEND_FILE_MAX_AGE_DEFAULT": None, "TRAP_BAD_REQUEST_ERRORS": None, "TRAP_HTTP_EXCEPTIONS": False, "EXPLAIN_TEMPLATE_LOADING": False, "PREFERRED_URL_SCHEME": "http", "JSON_AS_ASCII": True, "JSON_SORT_KEYS": True, "JSONIFY_PRETTYPRINT_REGULAR": False, "JSONIFY_MIMETYPE": "application/json", "TEMPLATES_AUTO_RELOAD": None, "MAX_COOKIE_SIZE": 4093, } )
sqlalchemy的默认配置文件
if ( 'SQLALCHEMY_DATABASE_URI' not in app.config and 'SQLALCHEMY_BINDS' not in app.config ): warnings.warn( 'Neither SQLALCHEMY_DATABASE_URI nor SQLALCHEMY_BINDS is set. ' 'Defaulting SQLALCHEMY_DATABASE_URI to "sqlite:///:memory:".' ) app.config.setdefault('SQLALCHEMY_DATABASE_URI', 'sqlite:///:memory:') app.config.setdefault('SQLALCHEMY_BINDS', None) app.config.setdefault('SQLALCHEMY_NATIVE_UNICODE', None) app.config.setdefault('SQLALCHEMY_ECHO', False) app.config.setdefault('SQLALCHEMY_RECORD_QUERIES', None) app.config.setdefault('SQLALCHEMY_POOL_SIZE', None) app.config.setdefault('SQLALCHEMY_POOL_TIMEOUT', None) app.config.setdefault('SQLALCHEMY_POOL_RECYCLE', None) app.config.setdefault('SQLALCHEMY_MAX_OVERFLOW', None) app.config.setdefault('SQLALCHEMY_COMMIT_ON_TEARDOWN', False) track_modifications = app.config.setdefault( 'SQLALCHEMY_TRACK_MODIFICATIONS', None )
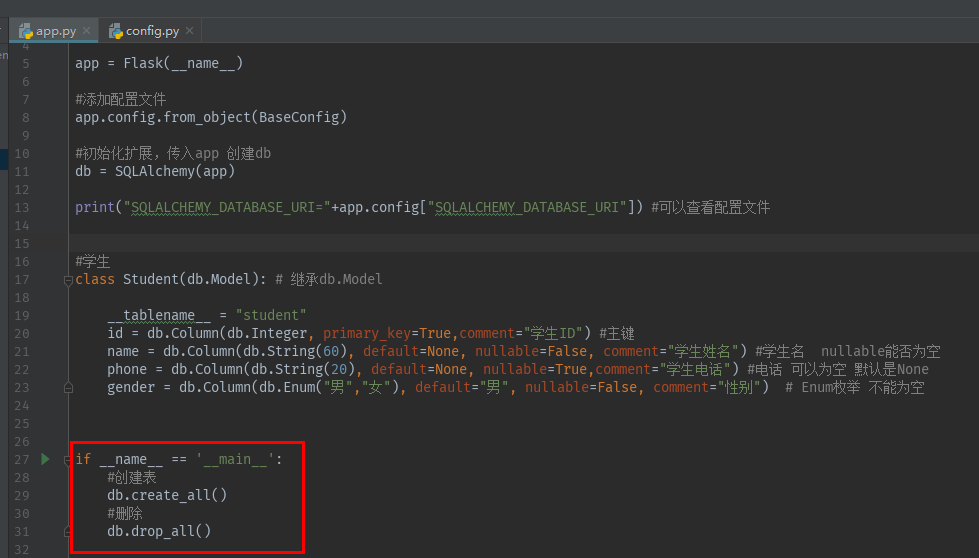
4)创建数据查询模型 并继承db.Model
二,直接使用SQLAlchemy连接mysql,不用通过flask框架
1),SQLAlchemy和pymsql的安装
在使用SQLAlchemy连接mysql前需要先给Python安装MySQL驱动,由于MySQL不支持Python3,所以可以同pymsql与SQLAlchemy进行交互
pip install pymysql
pip install sqlalchemy
2),连接数据库 连接数据库的引擎参数形式
engine = create_engine("数据库类型+数据库驱动://数据库用户名:数据库密码@IP地址:端口号/数据库?编码...", 其它参数)
注意:charset是utf8而不是utf-8,不能带- 不然会包异常
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8",echo=True)
echo=True, # 设置为True,程序运行时反馈执行过程中的关键对象,包括 ORM 构建的 sql 语句
pool_size=5, # 数据库连接池初始化的容量,保持的连接数,初始化时,并不产生连接。只有慢慢需要连接时,才会产生连接
max_overflow=10, # 连接池最大溢出容量,该容量+初始容量=最大容量。超出会堵塞等待,等待时间为timeout参数值默认30
pool_timeout=30, #从连接池里获取连接,如果此时无空闲的连接。且连接数已经到达了pool_size+max_overflow。此时获取连接的进程会等待pool_timeout秒。如果超过这个时间,还没有获得将会抛出异常。
sqlalchemy默认30秒
pool_recycle=7200 # 重连周期
create_engine()返回的是Engine的一个实例,代表了操作数据库的核心接口,处理数据库和数据库的API,可以直接使用engine.execute()或者engine.connect()来直接建立一个DBAPI的连接,但是如果我们要使用ORM, 就不能直接使用engine,初次调用create_engine()并不会真正连接数据库,只有在真正执行一条命令的时候才会尝试建立连接,目的是节省资源
连接oracle时
#db_confug:是字典 db_url = 'oracle+cx_oracle://{oracle_user}:{oracle_password}@{oracle_host}:{oracle_port}/{oracle_sid}'.format(**db_confug) create_engine(db_url) #如果在连接的时候报oracle ORA-12505, TNS:listener does not currently know of SID #解决方法是 db_url = "oracle+cx_oracle://{username}:{password}@{host}:{port}/?service_name={service}".format(**db_cfg)
3),映射说明
在使用ORM时 主要有两个配置过程;一是数据库表的信息描述处理;二是将类映射到这些表上。它们在SQLAlchemy中一起完成,被称为Declarative,
它们在SQLAlchemy中一起完成,被称为Declarative。使用Declarative参与的ORM映射的类需要被定义为一个指定基类的子类,这个基类含有ORM映射中相关类和表的信息。这样的基类称为declarative base class。这个基类可以通过declarative_base来创建。
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
4)建立映射关系
数据库与 Python 对象的映射主要在体现三个方面,其中前两者是比较常见的映射
- 数据库表 (table)映射为 Python 的类 (class),称为 model
- 表的字段 (field) 映射为 Column
- 表的记录 (record)以类的实例 (instance) 来表示
在sqlalchemy中表字段的常见类型如下:
Interger:整型,映射到数据库中是int类型
Float:浮点类型,float
Double; 双精度类型
String; 字符串类型 需要指定字符串的长度
Boolean; 布尔类型
Decimal: 定点类型,专门为解决浮点类型精度丢失的问题而设定。Decimal需要传入两个参数,第一个参数标记该字段能存储多少位数,第二个参数表示小数点后有又多少个小数位。
Enum:枚举类型;
Date:日期类型,年月日;
DateTime: 时间类型,年月日时分毫秒;
Time:时间类型,时分秒;
Text:长字符串,可存储6万多个字符,text;
LongText:长文本类型,longtext.
在指定表字段的映射为Column时 不但要指定表字段的数据类型,往往还需要指定哪些字段是主
primary_key #是否为主键 unique #是否唯一 index #如果为True,为该列创建索引,提高查询效率 nullable #是否允许为空 default #默认值 name #在数据表中的字段映射 autoincrement #是否自动增长 onupdate #更新时执行的函数 comment #字段描述
5) 创建类
根据以上字段的信息了解 可以自定义一个类
- __tablename__指定表名(要注意大小写)
- Column类指定对应的字段,必须指定
from sqlalchemy import create_engine,Column,Integer,String,Enum from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8",echo=True) #学生 class Student(Base): #继承Base __tablename__ = "student" #表名
id = Column(Integer, primary_key=True,comment="学生ID") #为主键 name = Column(String(60), default=None, nullable=False, comment="学生姓名") #学生名 nullable能否为空 False不能为空 True可以为空 phone = Column(String(11), default=None, nullable=True,comment="学生电话") #电话 可以为空 默认是None gender = Column(Enum("男","女"), default="男", nullable=False, comment="性别") #性别 Enum枚举 不能为空
#这个为可选项,只是增加对于表的描述,便于以后测试,也可以描述的更加详细
def __repr__(self): return "<User(name='%s', phone='%s', gender='%s')>" % (self.name,self.phone, self.gender)
if __name__ == '__main__':
Base.metadata.create_all(engine) # 通过基类与数据库进行交互创建表结构,此时表内还没有数据
# Base.metadata.drop_all(engine) #删除数据库的表
在实际编码的时候,常见的方式是先在数据库中建表,然后再用代码操作数据库。上面这种声明式定义映射模型,对 Column 的声明是很枯燥的。如果表的字段很多,这种枯燥的代码编写也是很痛苦的事情。
解决办法有两个:
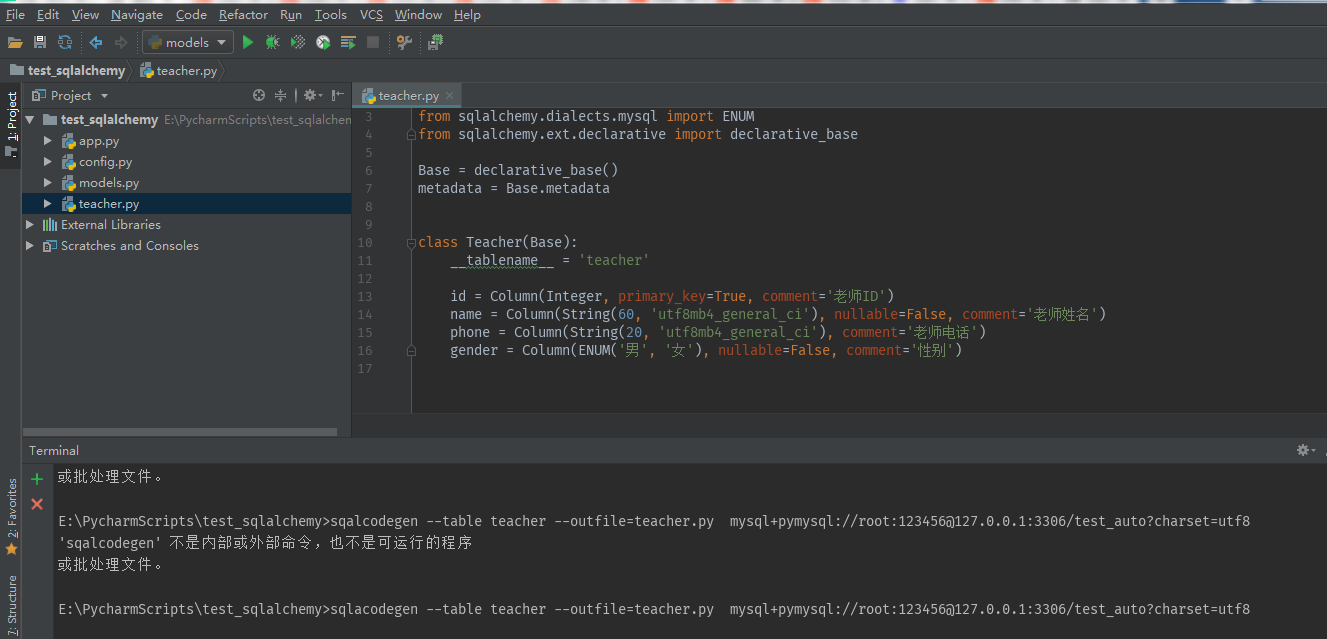
方法一:安装 sqlacodegen 库 (pip install sqlacodegen),然后通过下面的命令,基于数据库中的表自动生成 model 映射的代码。sqlacodegen 用法如下:
sqlacodegen --tables 表名 --outfile=路径名称 database url
database url 是与sqlalchemy的相同
sqlacodegen --table teacher --outfile=teacher.py mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8
方法二,在构建 model 的时候,使用 autoload = True,sqlalchemy 依据数据库表的字段结构,自动加载 model 的 Column。使用这种方法时,在构建 model 之前,Base 类要与 engine 进行绑定。下面的代码演示了 autoload 模式编写 model 映射的方法:
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.sql.schema import Table engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8",echo=True) Base = declarative_base() metadata = Base.metadata metadata.bind = engine class Course(Base): __tablename__= Table("course", metadata, autoload=True )
6)创建会话
- 在一个会话中操作数据库,会话建立在连接上,连接被引擎管理。当第一次使用数据库时,从引擎维护的连接池中获取一个连接使用。
- session对象多线程不安全。所以不同线程应该使用不用的session对象。Session类和engine有一个就行
SQLAlchemy的Session是用于管理数据库操作的一个像容器一样的工厂对象。Session工厂对象中提供query(), add(), add_all(), commit(), delete(), flush(), rollback(), close()等方法
6.1单线程创建session
from sqlalchemy import create_engine,Column,Integer,String,Enum from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8",echo=True) Base = declarative_base() session_factory = sessionmaker(bind=engine) Session = session_factory()
6.2多线程利用数据库连接池创建session
#数据库模块model.py from sqlalchemy.orm import scoped_session from sqlalchemy.orm import sessionmaker
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8",echo=True,
max_overflow=10, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
session_factory = sessionmaker(bind=engine)
Session = scoped_session(session_factory)
####业务模块thread.py import threading from model import Session class User(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(20)) fullname = Column(String(20)) password = Column(String(20)) age = Column(Integer) class MyThread(threading.Thread): def __init__(self, threadName): super(MyThread, self).__init__() self.name = threading.current_thread().name def run(self): session = Session() #每个线程都可以直接使用数据库模块定义的Session,执行时,每一个session都相当于一个connection session.query(User).all() user = User(name="hawk-%s"%self.name, fullname="xxxx",password="xxxx",age=10) session.add(user) time.sleep(1) if self.name == "thread-9": session.commit() Session.remove() if __name__ == "__main__": arr = [] for i in xrange(10): arr.append(MyThread('thread-%s' % i)) for i in arr: i.start() for i in arr: i.join()
7) sqlalchemy对数据库的基本操作
7.1创建一个表
Base.metadata.create_all(engine) # 通过基类与数据库进行交互创建表结构,此时表内还没有数据 # Base.metadata.drop_all(engine) #删除数据库的表
7.2添加 add():增加一个对象
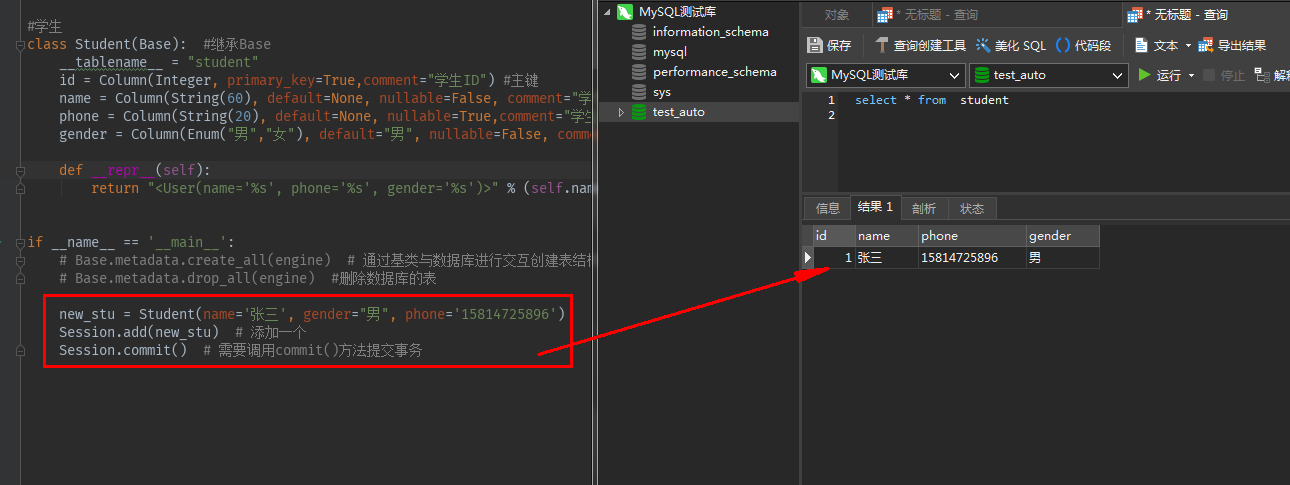
new_stu = Student(name='张三', gender="男", phone='15814725896') Session.add(new_stu) # 添加一个 Session.commit() # 需要调用commit()方法提交事务
7.3添加 add_all():可迭代对象,元素是对象
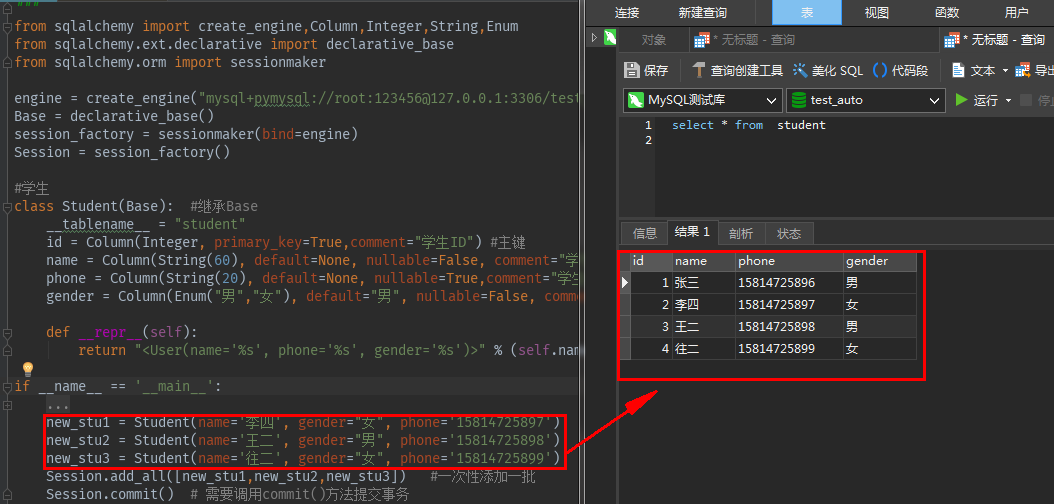
new_stu1 = Student(name='李四', gender="女", phone='15814725897') new_stu2 = Student(name='王二', gender="男", phone='15814725898') new_stu3 = Student(name='往二', gender="女", phone='15814725899') Session.add_all([new_stu1,new_stu2,new_stu3]) #一次性添加一批 Session.commit() # 需要调用commit()方法提交事务
#查找 后添加first(), all()等返回对应的查询对象
7.4 query() 不进行条件查询
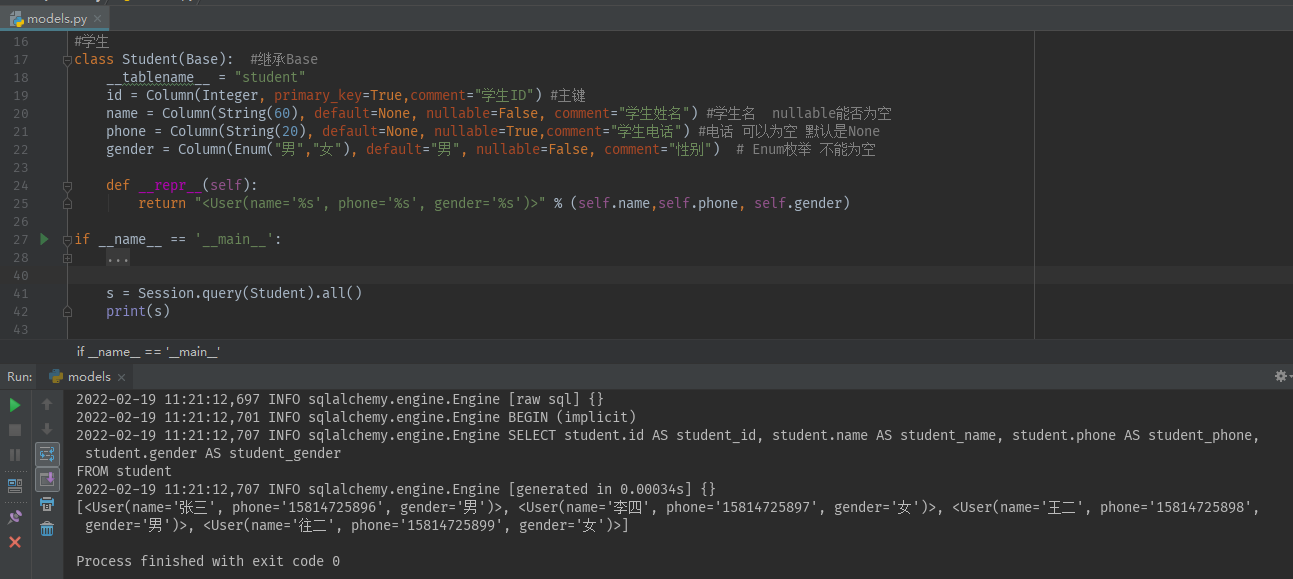
Session.query(Student).all() #查询所有 返回的对象是list列表
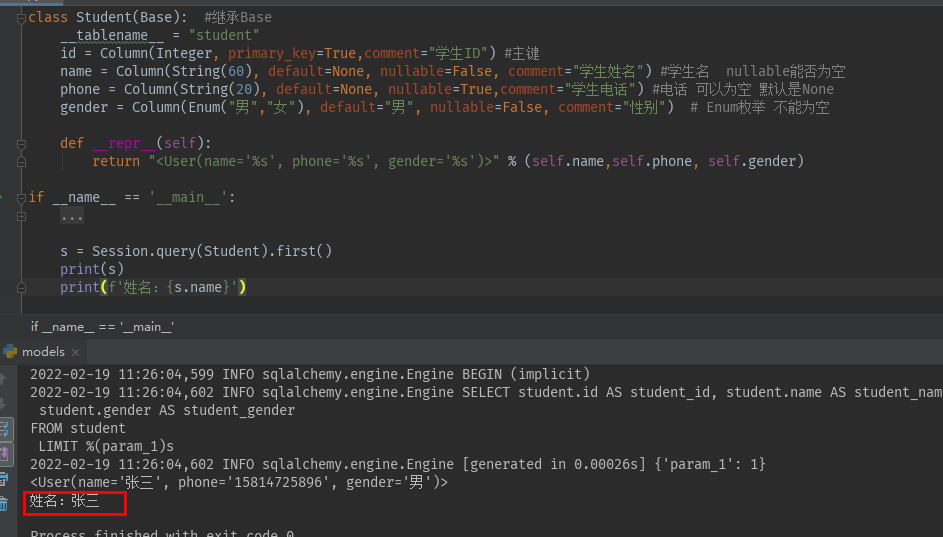
Session.query(Student).first() #查询第一个
7.5 query()进行条件筛选
Query 对象提供了 filter() 方法和 filter_by() 方法用于数据筛选。filter_by() 适用于简单的基于关键字参数的筛选。 filter() 适用于复杂条件的表达
Session.query(Student).filter(Student.id<=3).all()
Session.query(Student).filter(Student.name=='张三').first()
Session.query(Student).filter_by(name='张三').first()
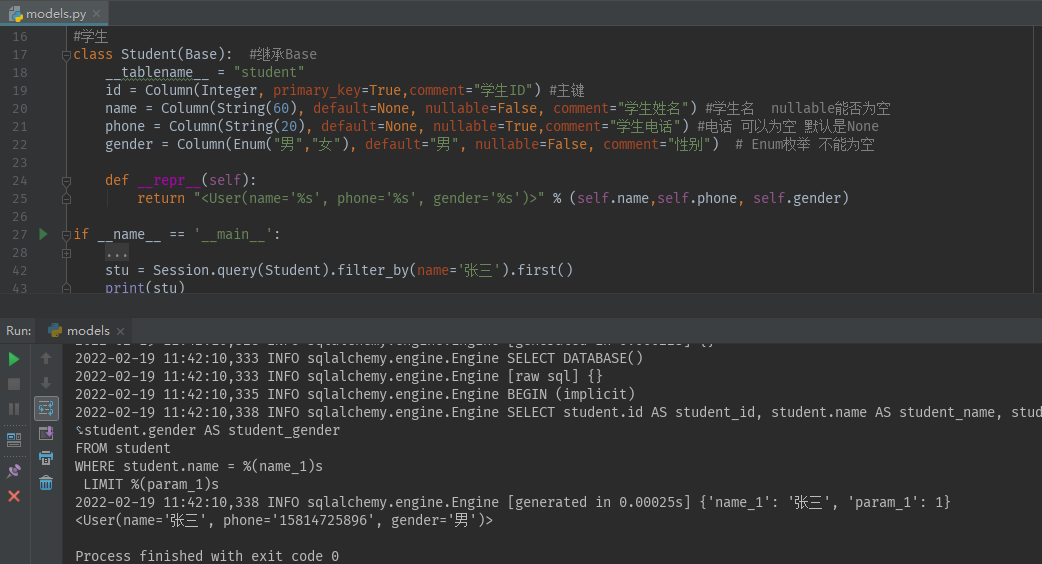
如果我们要找出所有id< =3 的数据只能用 filter() 方法,因为 filter_by 只支持关键字参数,不能实现
如果有两个限制条件是AND关系,可以直接使用两次filter()处理
Session.query(Student).filter(Student.name == '张三').filter(Student.gender == '男').first() #或者是 Session.query(Student).filter_by(name='张三').filter(Student.gender=='男').first()
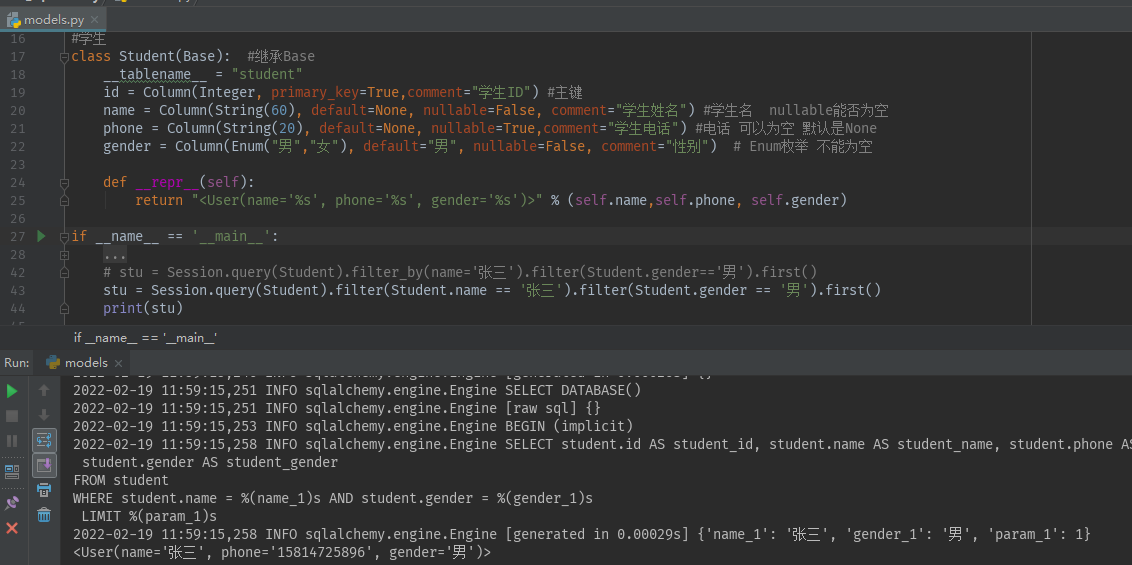
当然也有其他的展示方法
#filter operator : == #相等 != #不相等 like(’%关键字%’) #通配符搜索 ilike() #通配符搜索(不敏感) .in_([‘张三’, ‘张三1’, ‘张三2’]) #存在于 ~User.name.in_([‘张三’, ‘张三1’, ‘张三2’]) #不存在于 ==None #为空 .filter(Student.name == ‘张三’, User.gender == ‘女’) #and or_(Student.name == ‘张三’, Student.name == ‘张三2’) #OR #检索返回的列表,以及列表的标量 : all() #返回所有 first() #返回第一行 one() #检查是不是只有一行结果 如果存在则返回改数据如果不存在则报异常 one_or_none() #检查是不是一行或者没有结果 如果存在则返回该数据 若不存在则返回None
大致常见条件的表达,因为比较直观
def test_filter_le(self): Stu = Session.query(Student).filter(Student.id <= 3).all() print(Stu) def test_filter_ne(self): Stu = Session.query(Student).filter(Student.id != 2).all() print(Stu) def test_filter_like(self): Stu = Session.query(Student).filter(Student.id.like('%9')).all() print(Stu) def test_filter_in(self): Stu = Session.query(Student).filter(Student.EDUCATION.in_(['Bachelor', 'Master'])).all() print(Stu) def test_filter_notin(self): Stu = Session.query(Student).filter(~Student.EDUCATION.in_(['Bachelor', 'Master'])).all() print(Stu) def test_filter_isnull(self): Stu = Session.query(Student).filter(Student.MARITAL_STAT == None).all() print(Stu) def test_filter_isnotnull(self): Stu = Session.query(Student).filter(Student.MARITAL_STAT != None).all() print(Stu) def test_filter_and(self): Stu = Session.query(Student).filter(Student.GENDER=='Female', Student.EDUCATION=='Bachelor').all() print(Stu) def test_filter_and2(self): Stu = Session.query(Student).filter(and_(Student.GENDER=='Female', Student.EDUCATION=='Bachelor')).all() print(Stu) def test_filter_or(self): Stu = Session.query(Student).filter(or_(Student.MARITAL_STAT=='Single', Student.NR_OF_CHILDREN==0)).all() print(Stu)
7.6更新 (注意要重新commit()提交)
stu = Session.query(Student).filter(Student.name == '张三').first() #第一步 查询出要修改的数据 print(f"修改之前={stu}") stu.gender = "女" #第2步 修改字段值 Session.add(stu) #第3步然后重新添加 Session.commit() #第4步最后再重新提交
#或者
Session.query(Student).filter(Student.name == '张三').update({"gender":"女"})
Session.commit() #最后再重新提交
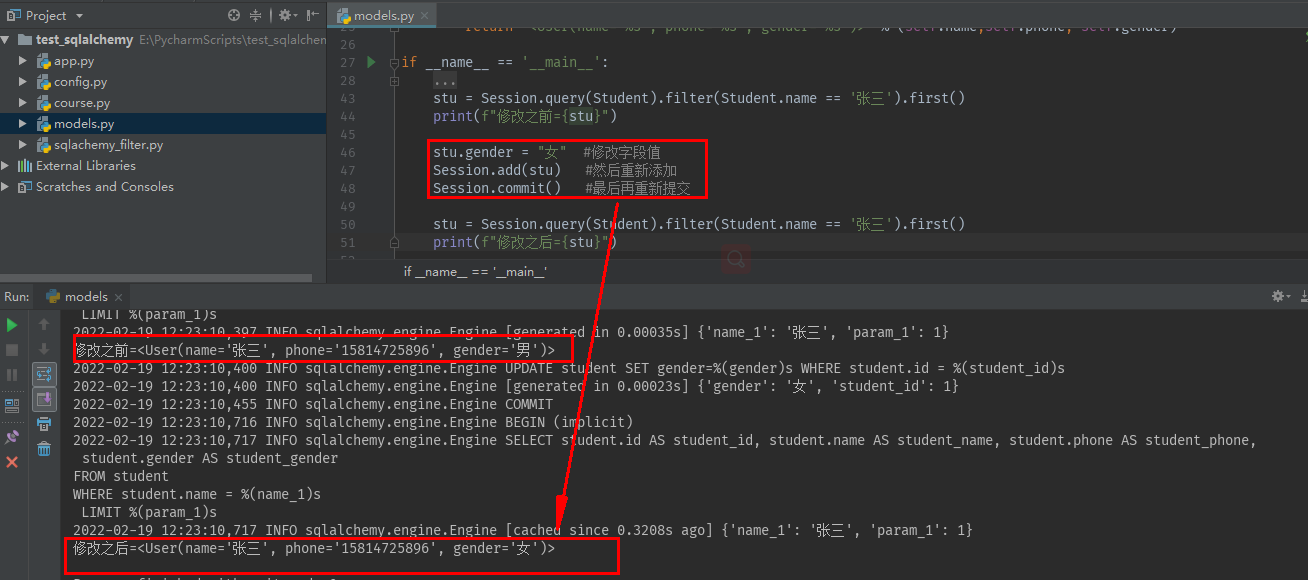
7.8 删除
stu = Session.query(Student).filter(Student.name == '张三').first() #查询数据 Session.delete(stu) #删除数据 Session.commit() #再次提交
#或者
stu = Session.query(Student).filter(Student.name == '张三').delete() #查询数据并删除
print(stu) #输出的是删除的个数
Session.commit() #再次提交
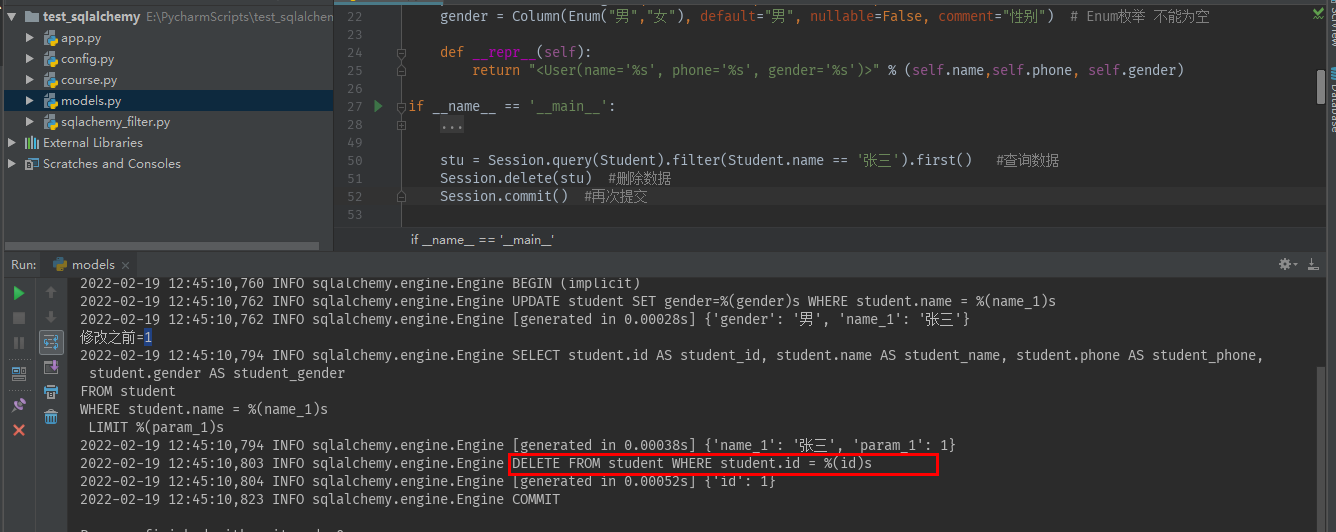
8) 执行原生的SQL语句
从SQLAlchemy中导出text方法,可以通过text(SQL语句)嵌入使用SQL语句。
-
方法一:使用Session 进行执行原生的sql语句
from sqlalchemy import text
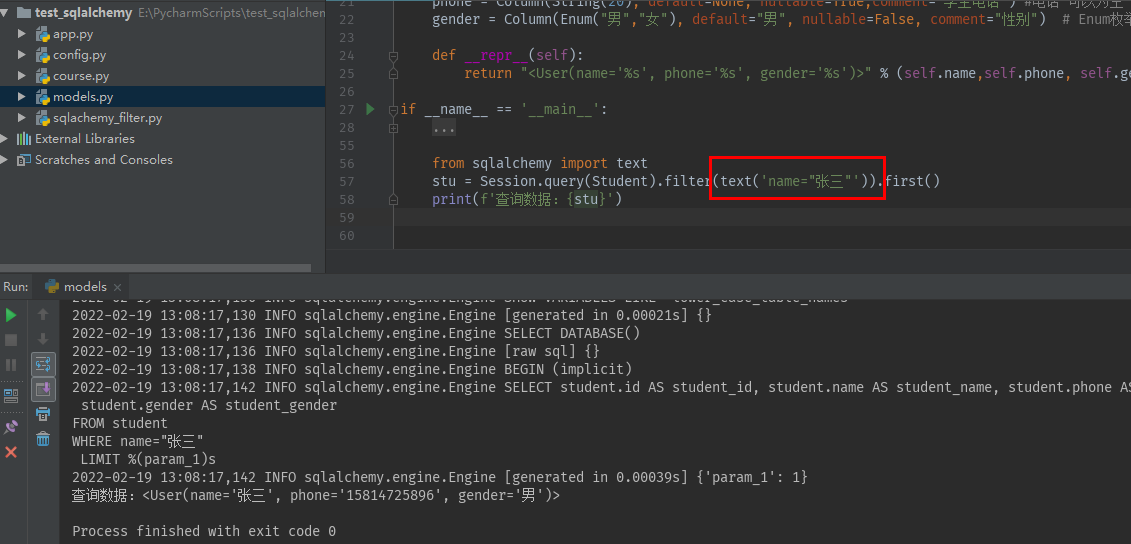
#查询 stu = Session.query(Student).filter(text('name="张三"')).first() print(f'查询数据:{stu}')
#返回字典的类型的数组
sql = "select * from student WHERE name='张三'"
res_rows = Session.execute(text(sql)).fetchall()
result = [dict(zip(result.keys(), result)) for result in res_rows]
print(result)
#执行结果:
[{'id': 1, 'name': '张三', 'phone': '15814725896', 'gender': '男'}]
注意:对于使用原生SQL查询出来的结果是一个list,
首先,使用一个变量接收你以上的查询结果。
其次,在这个list中包含着一个或多个tuple,其实这并不是标准的Python tuple,而是一个特殊的类型"<class 'sqlalchemy.util._collections.result'>",
这是一个 AbstractKeyedTuple 对象,它拥有一个 keys() 方法。
最后,我们可以通过这个方法将查询结果转换为字典,需要传到前端展示只需要将其装换为json格式即可。
示例:data = [dict(zip(result.keys(), result)) for result in results]
# 添加
cursor = session.execute('insert into users(name) values(:value)', params={"value": 'abc'})
session.commit()
print(cursor.lastrowid)
-
方法二通过Engine对象执行原生的SQL语句
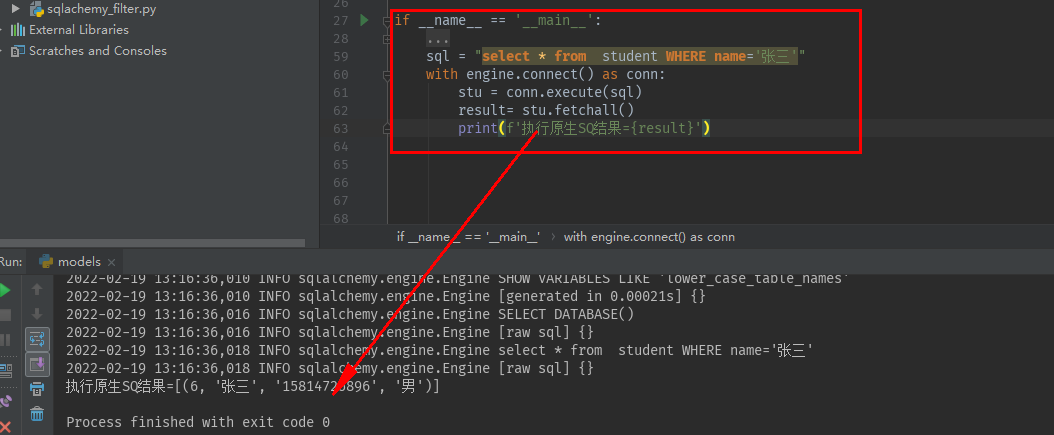
sql = "select * from student WHERE name='张三'" with engine.connect() as conn: stu = conn.execute(sql) result= stu.fetchall() print(f'执行原生SQ结果={result}')
conn.close()
9)建立表与表之间的关系(一对多,多对一)
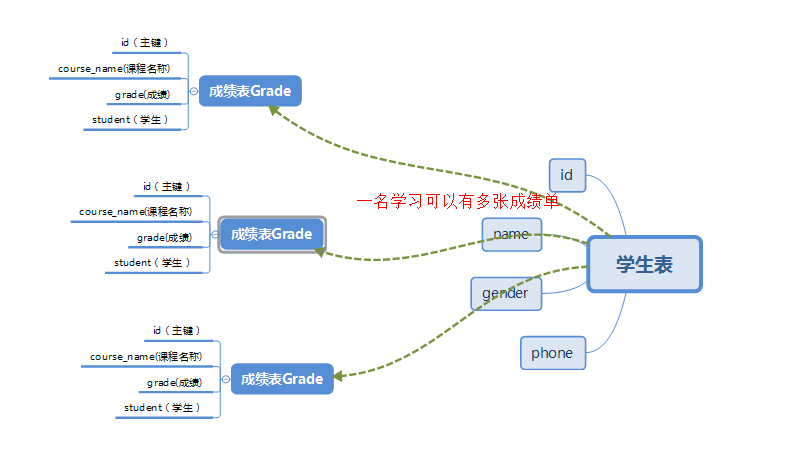
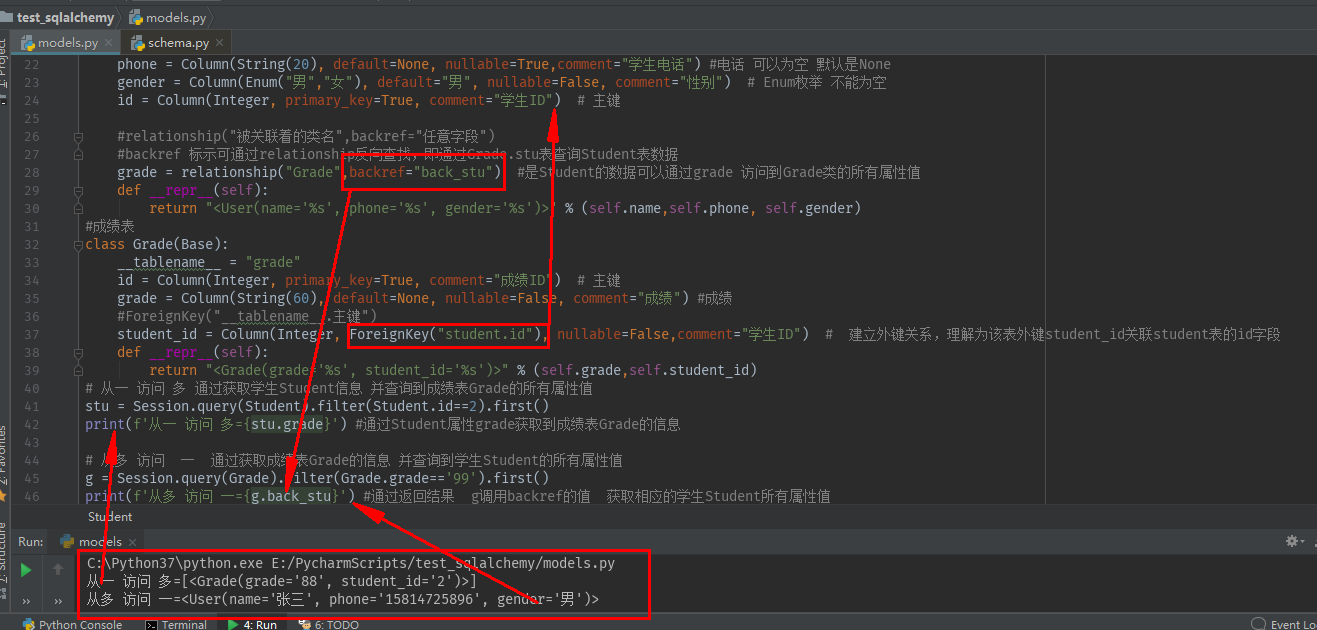
一个学生可以有多张成绩单,可以通过获取学生的信息 ,查询到成绩单表的信息 此时用ForeignKey 去关联少的一方;同是还需要使用relationship函数反向关联多的一方,实现通过获取获取成绩单的数g,然后调用backref的值获取学生表信息
from sqlalchemy import create_engine,Column,Integer,String,Enum from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker,relationship from sqlalchemy import ForeignKey # engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8",echo=True) engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test_auto?charset=utf8") Base = declarative_base() Session_factory = sessionmaker(bind=engine) Session = Session_factory() #学生 class Student(Base): #继承Base __tablename__ = "student" id = Column(Integer, primary_key=True,comment="学生ID") #主键 name = Column(String(60), default=None, nullable=False, comment="学生姓名") #学生名 nullable能否为空 phone = Column(String(20), default=None, nullable=True,comment="学生电话") #电话 可以为空 默认是None gender = Column(Enum("男","女"), default="男", nullable=False, comment="性别") # Enum枚举 不能为空 #relationship("被关联着的类名",backref="任意字段") #backref 标示可通过relationship反向查找,即通过Grade.back_stu查询Student表数据 grade = relationship("Grade",backref="back_stu") #是Student的数据可以通过grade 访问到Grade类的所有属性值 def __repr__(self): return "<User(name='%s', phone='%s', gender='%s')>" % (self.name,self.phone, self.gender) #成绩表 class Grade(Base): __tablename__ = "grade" id = Column(Integer, primary_key=True, comment="成绩ID") # 主键 grade = Column(String(60), default=None, nullable=False, comment="成绩") #成绩 #ForeignKey("__tablename__.主键") student_id = Column(Integer, ForeignKey("student.id"), nullable=False,comment="学生ID") # 建立外键关系,理解为该表外键student_id关联student表的id字段 def __repr__(self): return "<Grade(grade='%s', student_id='%s')>" % (self.grade,self.student_id) # 从一 访问 多 通过获取学生Student信息 并查询到成绩表Grade的所有属性值 stu = Session.query(Student).filter(Student.id==2).first() print(f'从一 访问 多={stu.grade}') #通过Student属性grade获取到成绩表Grade的信息 # 从多 访问 一 通过获取成绩表Grade的信息 并查询到学生Student的所有属性值 g = Session.query(Grade).filter(Grade.grade=='99').first() print(f'从多 访问 一={g.back_stu}') #通过返回结果 g调用backref的值 获取相应的学生Student所有属性值
10)sqlalchemy批量插入数据(性能问题)
#方式1:每插入一条数据进行一次commit() first_time = datetime.utcnow() for i in range(10000): user = User(username=username + str(i), password=password) db.session.add(user) db.session.commit() second_time = datetime.utcnow() print((second_time - first_time).total_seconds()) # 耗时:38.14347s #方式2: 数据插入完后一起commit()提交 second_time = datetime.utcnow() db.session.bulk_save_objects( [User(username=username + str(i), password=password) for i in range(10000) ] ) db.session.commit() third_time = datetime.utcnow() print((third_time - second_time).total_seconds()) # 耗时;2.121589s #方式3:耗时db.session.bulk_insert_mappings() third_time = datetime.utcnow() db.session.bulk_insert_mappings( User, [dict(username="NAME INSERT " + str(i), password=password) for i in range(10000)] ) db.session.commit() fourth_time = datetime.utcnow() print((fourth_time - third_time).total_seconds()) # 耗时:1.13548s #方式4: fourth_time = datetime.utcnow() db.session.execute( User.__table__.insert(), [{"username": 'Execute NAME ' + str(i), "password": password} for i in range(10000)] ) db.session.commit() five_time = datetime.utcnow() print((five_time - fourth_time).total_seconds()) # 耗时:0.888822s
感谢https://www.cnblogs.com/wt7018/p/11617878.html
感谢https://blog.csdn.net/js010111/article/details/119844734的分享
感谢https://blog.csdn.net/weixin_40006963/article/details/113461425的分享

 浙公网安备 33010602011771号
浙公网安备 33010602011771号