标准IO接口说明
标准IO接口说明
数据都是以文件的形式存储在Linux系统中,并且Linux系统为了简化不同类型文件的操作流程,在设计访问接口时也遵循POSIX标准,而POSIX标准就是对不同操作系统的访问接口做出统一的规范,目的是提高程序的兼容性和可移植性。经常使用的C语言同样具有语法标准,并且C语言标准在发布的时候也会发布对应的库函数提供给用户。这些库函数也同样遵循POSIX标准进行设计,而遵循POSIX标准设计出来的函数的集合也被称为标准库,比如大家使用的标准C库中提供了标准的输入输出函数,这些函数在Linux系统可以使用,同样也可以在Windows系统中使用。用户可以根据标准输入输出头文件<stdio.h>中的函数声明进行调用,Linux系统下该头文件路径为 /user/include。
另外,由于任何一种操作系统都会有访问磁盘文件的需求,所以POSIX标准中同样对访问文件的输入输出接口做出了约束,这些访问文件的函数接口在C语言标准中都有具体的描述。
标准C库中关于文件输入输出的函数接口一般被称为标准IO,访问文件常用的标准IO函数有fopen()、fread()、fwrite()、fclose()、fgetc()、fputc()、fgets()、fputs()、fprintf()、fscanf()等。
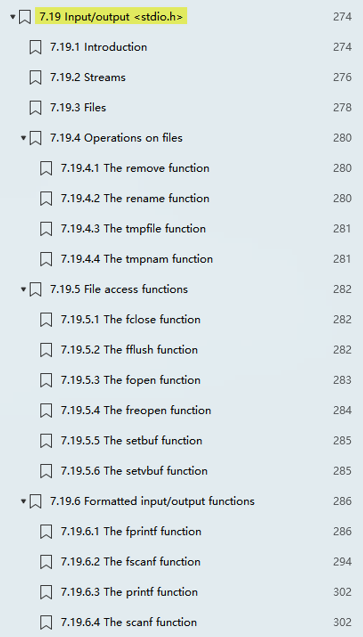
FILE类型其实是一个结构体数据类型,它包含了标准 I/O 库函数为管理文件所需要的所有信息,比如包括用于实际I/O 的文件描述符、指向文件缓冲区的指针、缓冲区的长度、当前缓冲区中的字节数以及出错标志等。头文件stdio.h中有关于FILE类型的相关描述,如:

阅读stdio.h中的条件编译选项可以发现在stdio.h中还包含了另一个头文件<libio.h>,这个头文件中才有关于FILE结构体类型的定义,该头文件的路径同样在Linux系统的/user/include目录下。
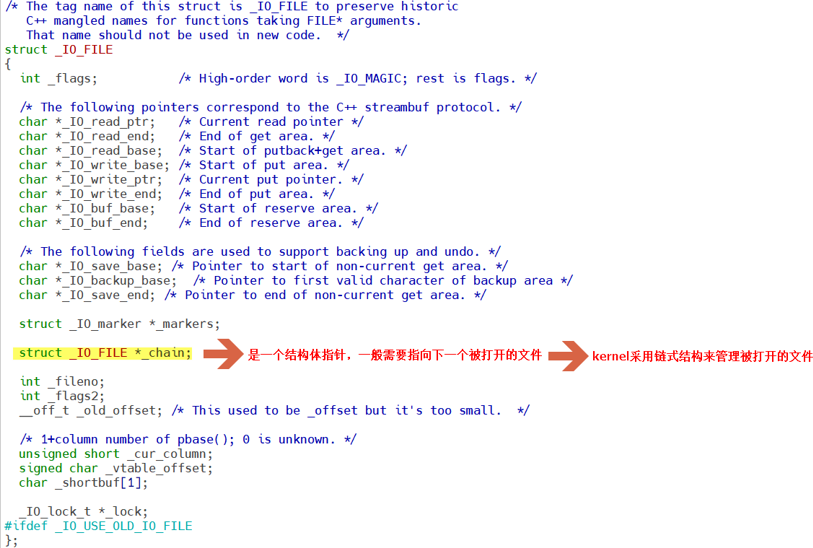
打开头文件<libio.h>之后,可以找到关于FILE结构体类型的定义,可以发现FILE结构体类型中的成员数量很多
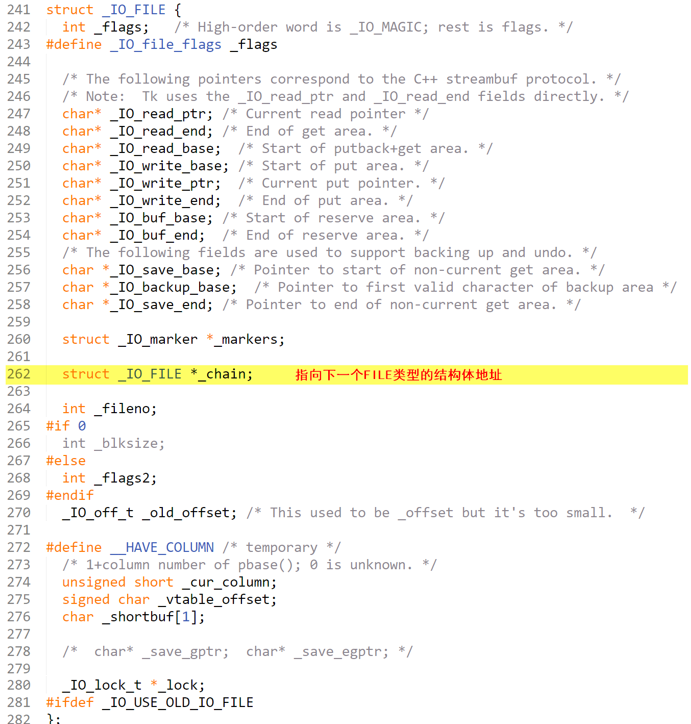
可以看到FILE结构体类型中有一个成员是FILE类型的指针变量chain,该指针可以指向下一个被打开文件的文件信息区,也就是可以把FILE类型当做数据结构中的链表的结点,结点中除了可以存储数据域之外,还可以利用指针域存储下一个结点的地址。
简单理解:用户可以在一个程序中利用fopen函数打开多个文件,每次打开一个文件,内核就会从堆内存中申请一块FILE结构体大小的空间用来存储文件的所有信息,然后按照文件打开的顺序把每个打开的文件的结构体形成一条链表,然后使用链表头进行管理。
注意:打开文件的目的无非就是对文件进行读写操作,所以每次当程序运行的时候已经有三个文件流被打开,分别是标准输入stdin、标准输出stdout、标准出错stderr,这三者在stdio.h中也是FILE指针。
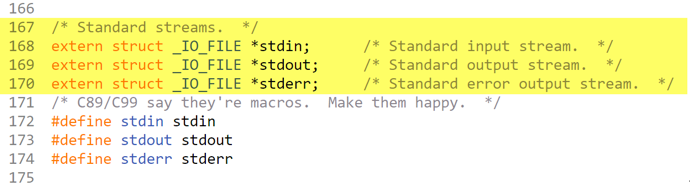
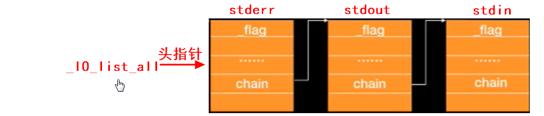
所以内核在管理被打开文件的时候,链表中已经有三个结点存在,然后再把新节点头插入到链表中。
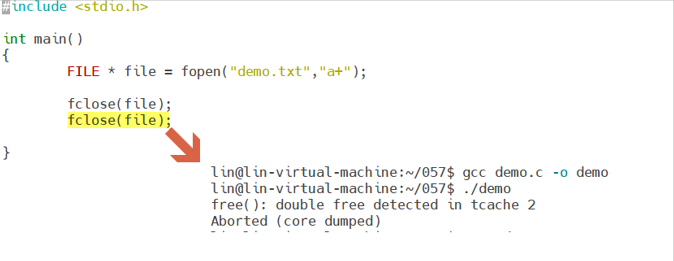
注意:使用标准IO的时候,是不可以反复关闭相同的文件,因为释放已经被释放的堆内存,会导致段错误!!
系统IO接口说明
基本概念
由于Linux系统下“一切皆文件”,也就是Linux系统下的数据和程序(shell命令)都是以文件的形式存储的,所以Linux内核会提供一组操作文件的函数接口,这组函数接口也被称为系统IO,同时为了满足用户访问文件的需求以及提高用户程序的可移植性,标准库也提供了一组操作文件的函数接口,这组函数接口也被称为标准IO,只不过标准库提供的标准IO函数都是遵循ANSI C标准设计出来,是为了方便用户在不同的操作系统下可以调用通用的函数来实现对文件的读写访问,但其实标准IO也是基于内核提供的系统IO设计出来的。
两者区别
标准IO的优点是提供了缓冲区并且函数接口非常丰富,虽然标准IO是在系统IO的基础之上实现的,但是由于标准IO提供了输入输出缓冲区,这样可以避免频繁的系统调用,而且不用人为关心缓冲区大小的选择,整体上提高了I/O的效率。但是缺点是没有办法针对某些类型的文件(链接文件、套接字文件)进行访问,所以一般适合访问普通文件。
而系统IO的缺点是不具备输入输出缓冲区,也就是没办法高效处理数据,原因是系统调用与普通函数调用相比通常需要花费更多的时间,因为系统调用的过程中内核要执行一系列的操作:首先内核需要捕获调用,然后再检查系统调用传递的参数的有效性,最后在用户空间和内核空间之间传输数据。但是系统IO的优点是可以针对特定类型文件进行访问,所以一般适合访问数据需要实时刷新的硬件设备(LCD、触摸屏......)。
简单理解:标准I/O可以看成是在系统I/O的基础上封装了缓冲机制。这样可以先读写缓冲区,必要时再访问实际文件,从而减少了系统调用的次数,提高访问效率。
fwrite() --> a.txt -->fwrite(buf,1,1,fp); --> write() --> 100个字节要写--> 调用100次write() -->慢
fwrite() --> a.txt -->fwrite(buf,1,100,fp); -->write() -->100个字节要写-->调用001次write() -->快
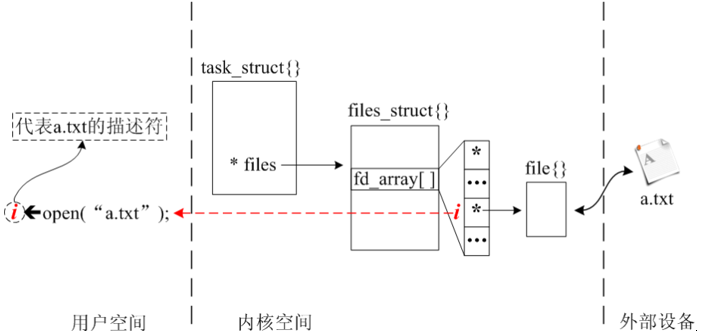
open函数的返回值可以理解为是被打开文件的代号,内核并不是以被打开文件的路径和名称来管理文件,而是在调用open函数的时候会从未分配的文件描述符中找到一个最小的提供给被打开的文件。在对文件进行读写(R/W)访问时同样是通过这个文件描述符实现。
文件描述符本质就是一个非负整数,从内核源码角度分析,这个整数实际上是内核中的一个称为 fd_array 的数组下标。
打开文件时,内核产生一个指向 file{} 的指针,并将该指针放入一个位于 file_struct{} 中的数组 fd_array[] 中,而该指针所在数组的下标,就被 open() 返回给用户,所以内核把这个数组下标称为文件描述符。
文件描述符从0开始分配,每打开一个文件,就产生一个新的文件描述符。当然,用户可以重复打开同一个文件,每次打开文件都会使内核产生新的结构体,并得到不同的文件描述符。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号