Hadoop之yarn
HDFS是存储模型,把数据进行切块,散列到各个节点,提供物理支持。MapReduce写好的程序怎么向文件移动,即计算向数据移动。需要HDFS暴露数据的位置,然后进行资源管理和任务调度。
框架角色
client
- 1.会根据每次的计算数据,咨询NameNode元数据(block的相关信息)算split,得到一个切片的清单,一个split对应一个map数量。 split是逻辑的,block是物理的,block上有(offset,location),split和block是有映射的关系。结果:split包含偏移量,以及split对应的map任务应该移动到哪些节点(location)。例如:
split01 fileA 000 400 datanode1 datanode3 datanode5
split02 fileA 401 700 datanode2 datanode3 datanode4 - 2.生成计算程序未来运行时的相关配置文件
- 3.client会将jar,split清单,配置 上传到HDFS系统中(副本数10)
- 4.client会调用JobTracker,提交job(通知要启动一个计算程序了),并且告知文件都放在了HDFS的哪些地方。
JobTracker
- 1.JobTracker收到启动程序后,从HDFS中取回【split清单】
- 2.根据收到的TaskTracker汇报的资源,最终确定每一个split对应的map应该去到哪一个节点,生成确定的清单
- 3.TaskTracker再心跳的时候会取回分配给自己的任务信息
TaskTracker
TaskTracker与DataNode合并设置,让每一个节点同时作为DataNode和TaskTracker,为了让每一个TaskTracker尽量处理本地的数据。
- 1.取回任务后,从HDFS中下载jar,xml到本机
- 2.最终启动任务MapTask/ReduceTask
问题
- 1.单点故障
- 2.压力过大
- 3.集成了资源管理和任务调度,两者耦合,未来的计算框架不能复用资源管理
改进,hadoop 2.x yarn架构图
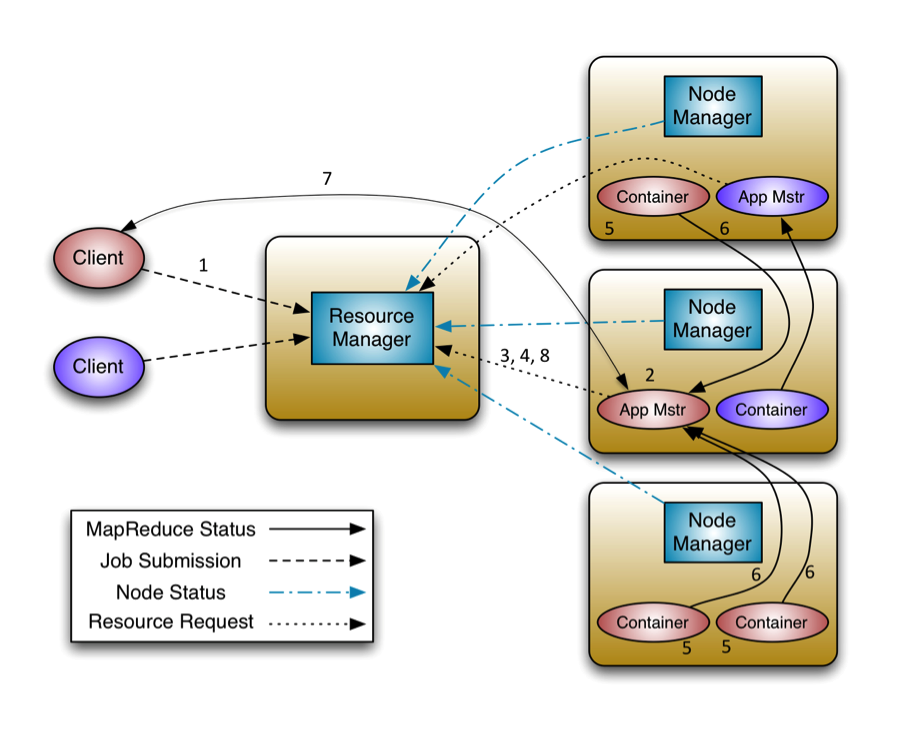
yarn基本组成
- ResourceManager负责集群统一的资源管理、调度、分配。
- NodeManager负责上报心跳,提交自己的节点状况
- ApplicationMaster相当于一个任务的管理者,负责监控、管理所有运行任务的节点,同时负责向ResourceManager申请资源,返还资源等。
- Container是yarn中分配资源的单位,包括内存,CPU等。
yarn运行流程
- 1.client跟1.x版本一样,切片清单、jar、配置文件上传到HDFS,访问ResourceManager申请一个ApplicationMaster
- 2.ResourceManager选择一台不忙的节点通知NameNode启动一个Container,在里面反射一个ApplicationMaster
- 3.启动ApplicationMaster,从HDFS下载切片清单,向ResourceManager申请资源
- 4.由ResourceManager根据自己掌握的资源情况得到一个确认的清单,通知NameNode启动Container,并反向注册到已经启动的ApplicationMaster进程
- 5.最终ApplicationMaster将任务发送到Container(消息)
- 6.Container收到消息后,反射相应的任务,调用方法执行
对比
- 1.单点故障
曾经1.x版本是全局的,JobTracker挂了之后,整个计算层就没有了调度
yarn:每一个App由一个自己的ApplicationMaster调度,且支持失败重试 - 2.压力过大
yarn中每个计算程序有自己的ApplicationMaster,只负责自己计算程序的任务调度,不同的任务有不同的ApplicationMaster。 - 3.yarn只是资源管理,不负责具体的任务调度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号