MAP:
Reduce:
(KEY,VALUE):
MapReduce流程图
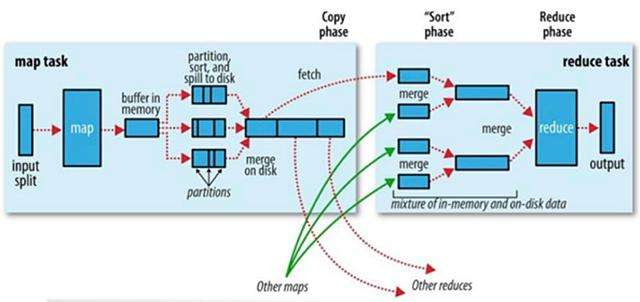
MapTask
- 1.切片会格式化,然后调用map方法
- 2.map的输出要映射成KV,KV会参与分区计算,算出分区号P,最终输出(K,V,P)到buffer区(buffer默认是100M,阈值为80%)
- 3.buffer是一个环形缓冲区,本质就是线性字节数组,两端分别向中间写,一端是写KV数据,另一端是写KV的索引,索引固定16B(int P,int keyStart,int valueStart,int valueLength),如果数据填充到阈值80%,启动线程快速排序,快速排序中比较的是key的值(从索引中取出),比较之后交换的是索引的位置,排序是二次排序,分区号有序,分区内key也有序。
- 4.当buffer排序之后,准备溢写到磁盘之前,用户可以选择启动combiner,按组统计
- 5.mapTask的输出是一个文件,保存在本地的文件系统中,当这些小文件超过3个(默认值,用户可以设置),合并成大文件,也会触发combine,但是必须是幂等的。
ReduceTask
- 1.shuffle :洗牌(相同的key被拉取到一个分区)
- 2.sort :整个MapReduce框架中只有map端是无序到有序的过程,reduce这里的sort其实是对排好序的一堆小文件做归并的过程
- 3.reduce怎么工作的,通过run方法:rIter = shuffle 包装成迭代器,里面包含该分区所有组的数据。reduce方法被调用的时候,并没有把一组数据真的加载到内存中,而是传递一个迭代器-values,在reduce方法使用该迭代器的时候,hasNext方法判断nextKeyIsSame(),取出当前key和下一条的key比较,不相同就证明不是一组数据,相同就继续执行while循环,进行统计。next方法负责调取nextKeyValue方法,从reduceTask级别的迭代器中取记录,并同时更新nextKeyIsSame()。
- 4.reduce运用了迭代器模式:规避了内存OOM的问题


