1. Request库的基本方法
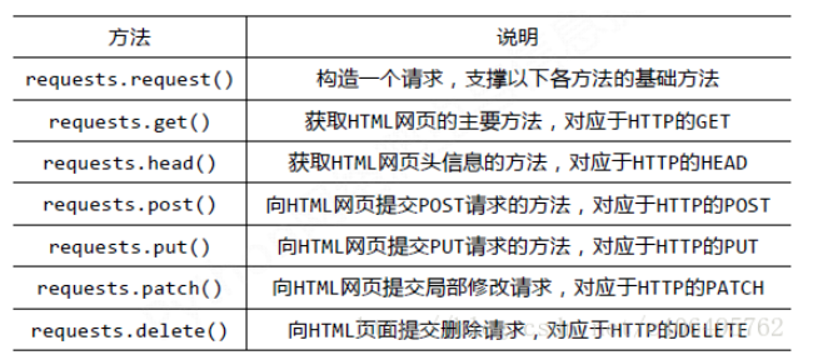
- response.status_code
- rersponse.text
- response.cookies
- response.headers
- response.content
- response.url
- response.history
2. 请求和响应
2.1 基本使用
# 基本使用
import requests
response = requests.get('https://www.baidu.com/')
print(type(response)) # <class 'requests.models.Response'>
print(response.status_code) # 200
print(response.text) # 将响应内容转换成了字符串
print(response.cookies) # <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
2.2 带参数的get方法
# 带参数的get方法
import requests
data = {'name': 'hgzero', 'age': '22'}
response = requests.get('http://httpbin.org/get', params=data) # 相当于在url后面补充?name=hgzero&age=22
print(response.text)
2.3 添加headers
# 添加headers
import requests
target = "https://cnblogs.com/hgzero"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)',
'Referer': "http://cnblogs.com",
}
response = requests.get(url=target, headers=headers, verify=False) # verify为False表示不进行https认证
print(response.text)
2.4 保存二进制内容
response = requests.get("https://github.com/favicon.ico")
with open('favicon.ico', 'wb') as f:
f.write(response.content) # response.content表示保存为二进制格式
f.close()
2.5 解析json
# 解析json
import requests
response = requests.get('http://httpbin.org/get')
print(type(response.json())) # <class 'dict'>
print(response.json())
2.6 基本POST请求
# 基本POST请求
import requests
data = {'name': 'America', 'age': '22'}
response = requests.post('http://httpbin.org/post', data=data)
print(response.text)
3. 高级操作
3.1 文件上传
# 文件上传
import requests
files = {'file': open('xxx.png', 'rb')} # 字典的形式
response = requests.post('http://httpbin.org/post', files=files)
print(response.text)
3.2 获取cookie
# 获取cookie
import requests
response = requests.get("https://www.baidu.com")
print(response.cookies)
for key, value in response.cookies.items():
print(key + "=" + value)
3.3 会话维持
# 会话维持
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
response = s.get('http://httpbin.org/cookies')
print(response.text)
3.4 证书验证
# 证书验证
import requests
# 消除证书认证的警告消息
import urllib3
urllib3.disable_warnings
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
# 加证书验证
response = requests.get('http://www.12306.cn,', cert=('/path/cerver.crt', '/path/key'))
print(response.status_code)
3.5 代理设置
# 代理设置
import requests
proxies = {
'http': 'http://127.0.0.1:9743',
# 如果需要用户名和密码,则可以写成这样的格式
# 'http': 'http://user:password@127.0.0.1:9743'
'https': 'https://127.0.0.1:9743',
}
response = requests.get('http://www.taobao.com', proxies=proxies)
print(response.status_code)
# socks代理
# 先要安装:pip3 install 'requests[socks]'
proxies = {
'http': 'socks5://127.0.0.1:9742',
'https': 'socks5://127.0.0.1:9742',
}
3.6 超时设置
# 超时设置
import requests
from requests.exceptions import ReadTimeout
try:
response = requests.get('http://httpbin.org/get', timeout=1)
print(response.status_code)
except ReadTimeout:
print("Timeout!")
3.7 认证设置
# 认证设置
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://xxxxx.com', auth=HTTPBasicAuth('user', '123'))
# 这两种写法通用
# r = requests.get('http://xxxxx.com', auth={'user', '123'})
print(r.status_code)
3.8 异常处理
# 异常处理
import requests
from requests.exceptions import ReadTimeout, HTTPError, RequestException
try:
response = requests.get('http://httpbin.org/get', timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('Timeout')
except HTTPError:
print('Http error')
except RequestException:
print('Error')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号