决策树——常用算法说明
决策树模型很早就出现了,当我们使用一连串的 “if...else...” 语句时,就已经具备了决策树的思想了,不过当真正去构建决策树时,就要考虑哪个先 if、哪个后 if,采用什么样的标准来支持我们选定先 if的属性等,这部分内容在《分类:决策树——树的生长》中已经说明了。早期的决策树算法(如ID3算法)的处理能力有限,只能在特定情形下使用,后来经过不断发展,出现了一些新的算法(如CART),处理能力大大提高,使得决策树模型的应用更加广泛。本文就常见的ID3、C4.5、CART算法做一些记录说明。
1. ID3算法
ID3算法是Quinlan教授在上个世纪70年代提出的,算法引入信息论中熵的概念,并将信息增益作为划分属性的度量,这一做法简洁高效,在当时影响较大。关于信息熵
![]()
定义的由来,这里简单的做一下介绍。假设一棵二分类决策树上某一节点包含有个样本,其中正类样本有
,负类样本有
个,(
),则样本的类别组合情况有
种。从样本属性与类别的对应关系上,如何看待
呢?也即是不参考样本的属性值时,我们认为的选定
个样本为正例样本。很显然,在给定
值时,
越小就越表明该结点上样本类别越趋向于单一,结点误分类率越小。下面我们对
做一些分解
(1)
当时,依据
公式,有
(2)
在较大时,
的值较大,为了方便度量可以作对数处理,同时也需要剔除总数
的影响,于是将
处理为如下结果
(3)
将式(2)代入式(3)中,得
(4)
公式(4)就是信息熵定义形式的由来。
ID3算法提出较早,因此也存在一些不足之处,主要为:
- 没有考虑连续取值型属性的处理,这限制了其应用
- 信息增益更偏向于取值更多的属性,这一点在《分类:决策树——树的生长》中已说明
- 对于属性有缺失值的情况没有考虑
- 没有考虑过拟合的问题
2. C4.5算法
C4.5算法也是Quinlan教授提出的,是ID3算法的改进版本,之所以叫C4.5而不是ID4.5,是因为ID3算法提出之后,人们在其基础上做各种改进,“ID4.5”被先使用了。针对ID3算法的不足之处,C4.5算法做了改进。
- 针对连续取值型属性,C4.5算法中做了这样的处理:对结点上给定的样本集D和连续取值型属性a,将D中属性a的取值从小到大排列,得到
 ,对该集合中任意两个相邻取值
,对该集合中任意两个相邻取值 、
、 ,划分值取它们之间任意一个值时,对D来说都不影响划分结果,因此一般取二者平均值即可
,划分值取它们之间任意一个值时,对D来说都不影响划分结果,因此一般取二者平均值即可
![]()
这样就得到属性a的候选划分值集合![]() ,接着分别选取该集合中的候选值对样本集D进行二元划分,计算每种情况下的增益率,将增益率最大的点作为最终的划分点。在计算划分值时,有一个小窍门可以注意一下,当将样本集D中属性a的取值从小到大顺序排列之后,若有一段相邻的样本类别相同,则集合
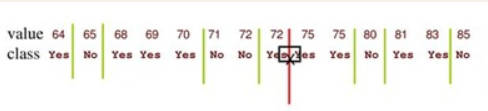
,接着分别选取该集合中的候选值对样本集D进行二元划分,计算每种情况下的增益率,将增益率最大的点作为最终的划分点。在计算划分值时,有一个小窍门可以注意一下,当将样本集D中属性a的取值从小到大顺序排列之后,若有一段相邻的样本类别相同,则集合![]() 中由这一段相邻样本计算出的值可以不予以考虑,有时候这样可以减少许多计算量,例如下图中原本需要计算的68.5和69.5可以不用计算。
中由这一段相邻样本计算出的值可以不予以考虑,有时候这样可以减少许多计算量,例如下图中原本需要计算的68.5和69.5可以不用计算。
![]()
需要注意的是,与离散属性不同,若当前连续型属性作为了划分属性,则在还可以参与子结点上属性的划分过程。
- 提出采用“增益率”来校正使用“信息增益”时出现的问题,这部分内容在《分类:决策树——树的生长》中已说明
- 在属性缺失值的处理上,需要考虑两个情况,一个是有缺失值的属性如何计算其增益率,另一个是划分属性上有缺失值的样本如何划分到子结点上。针对第一种情况,C4.5算法中将结点上的样本分为两部分,一部分是属性(即将计算增益率的属性)上无缺失值的样本,另一部分是属性上有缺失值的,计算无缺失值样本的占比
,然后用无缺失值的样本计算该属性的增益率
,将
与
的乘积作为该属性最终的增益率;针对第二种情况,C4.5算法中将有缺失值的样本同时划分到各个子女结点上,不过需要分别乘以一个系数,该系数为各子女结点上的样本个数占父结点上总样本数的比例。
- 在过拟合问题上,C4.5算法加入了剪枝过程——Error-Based Pruning(EBP)剪枝,这是C4.5算法中使用的剪枝算法,它被认为是Pessimistic Error Pruning(PEP)剪枝方法的改进版。
C4.5算法虽然在ID3算法基础上有了较大改进,但是仍然存在一些不足
- 剪枝算法仍可以改进已达到更好的泛化能力
- C4.5算法建立的决策树只能用于分类,不能用于回归
- C4.5算法中采用的信息增益率度量涉及到对数运算,这会增加一些计算量
3. CART算法
CART算法是Breiman等人提出的,如果不考虑集成学习话,在普通的决策树算法里,CART算法算是比较优的算法了。scikit-learn库的决策树使用的也是CART算法。CART算法也可以用于回归,不过本文只讨论其在分类上的应用。相较于C4.5算法,CART算法做出了如下的改变
- 在剪枝算法上,CART算法使用了Cost-Complexity Pruning(CCP)剪枝方法
- CART算法使用基尼系数作为属性划分时的度量标准,简化计算过程
- CART算法构建的决策树为二叉树。在连续型属性的划分值计算上,和C4.5算法一致,但在离散型属性的划分值计算上,CART算法为了保证二分,有所不同。例如离散型属性
的取值集合为
,则每次从中拿出一个值作为一类,剩余的值作为一类,这样就有
组划分情况
与
、
与
,...,
与
,选择基尼指数最小的一组划分作为属性
的最优划分方式,假如
与
是当前结点上树形
的最优划分方式,由于
还可以继续划分,因此在当前结点的子女结点上,依然可以采用相同的方式对
划分。
尽管CART算法是表现不错的算法了,但是其也存在不足之处:
- 分类决策不应该由单个属性来决定(ID3、C4.5算法也是这样)。实际中的属性大多并不是独立不相关的,因此在选择最优划分属性时应该选择属性的一个最优线性组合,构建多变量决策树,例如OC1算法
- 当构建决策树的样本发生一些变化时,可能导致决策树结构发生较大的变化。当然,这个问题可以通过类似交叉验证的方式进行改善,但一些集成学习方法可能表现更好,如随机森林。
这里还是顺带说一下用CART算法建立回归树的过程吧。建立回归树时,样本上的所有属性应该都是连续型属性,同时预测的值也应该是连续取值的,否则就没必要用回归分析方法来做预测了。CART算法建立回归树的过程与建立分类树的过程主要区别在:属性连续值的处理、预测结果的计算方式,其它地方基本一样
在属性连续值的处理上,回归树在选择最优划分属性时,不是采用基尼指数,而是采用以下的度量
式中表示当前划分属性,
表示属性A上的划分点,
、
表示利用划分点划分属性
后得到的两个样本集,
表示样本
对应的标签值,
和
分别表示
、
上样本标签值的平均值,该度量参数表示的意思是:属性划分后,使两个样本子集上标签值的方差分别最小,同时也使它们的方差和最小,这样的划分点
才是最好的。
在回归树建立完成之后,预测结果是样本标签值的平均值(或者中位值),而不是像分类树那样为样本最多的类别值。
4. 决策树分类的特点总结
- 决策树分类是一种非参数方法,他不需要任何先验假设
- 找到最佳决策树是NP完全问题
- 构建决策树不需要昂贵代价,且一旦决策树构建完成,分类过程非常快,最坏情况下时间复杂度为
,
为树的深度
- 决策树的分类结果易于解释
- 对噪声干扰有较好的鲁棒性
- 冗余属性不会对决策树的准确率造成不利影响,这是由于优先使用最优划分属性来划分结点的机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号