
第一次个人编程作业
| 这个作业属于哪个课程 |计科22级12班|
| ----------------- | --------------- |
| 这个作业要求在哪里|个人项目|
| 这个作业的目标 |设计一个论文查重算法,完成软件设计的个人开发流程|
我的GitHub:GitHub
1.PSP表格
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 20 |
| Estimate | 估计这个任务需要多少时间 | 25 | 20 |
| Development | 开发 | 725 | 705 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 350 |
| Design Spec | 生成设计文档 | 15 | 20 |
| Design Review | 设计复审 | 30 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 60 | 50 |
| Coding | 具体编码 | 240 | 120 |
| Code Review | 代码复审 | 60 | 40 |
| Test | 测试(自我测试,修改代码,提交修改 | 60 | 70 |
| Code Review | 代码复审 | 180 | 229 |
| Reporting | 报告 | 30 | 45 |
| Test Repor | 测试报告 | 30 | 45 |
| Size Measurement | 计算工作量 | 30 | 35 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 150 |
| 合计 | 930 | 955 |
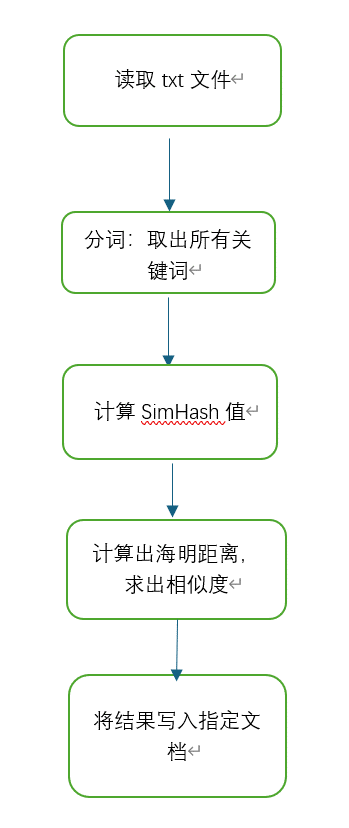
2.整体流程
3.开发环境
编程语言:java
IDE:Intellij IDEA 2024.1
4.算法代码
MainClass:
点击查看代码
package com.my.check;
import java.text.DecimalFormat;
import java.util.Scanner;
public class MainClass {
public static void main(String[] args) {
try (Scanner scn = new Scanner(System.in);){
// StringBuffer sb1 = ReadTxt.readTxt("C:\\Users\\10973\\Desktop\\test\\orig.txt");
// StringBuffer sb2 = ReadTxt.readTxt("C:\\Users\\10973\\Desktop\\test\\orig_0.8_add.txt");
System.out.print("请输入抄袭版论文的文件的绝对路径:");
String path = scn.next();
if(path.indexOf("\\") > 0 && path.indexOf("\\\\") < 0) {
path = path.replace("\\", "\\\\");
System.out.println(path);
}
System.out.println(path);
StringBuffer sb1 = ReadTxt.readTxt(path);
System.out.print("请输入论文原文的绝对路径:");
String txtPath = scn.next();
if(path.indexOf("\\") > 0 && path.indexOf("\\\\") < 0) {
txtPath = txtPath.replaceAll("\\", "\\\\");
System.out.println(txtPath);
}
StringBuffer sb2 = ReadTxt.readTxt(txtPath);
SimHash hash1 = new SimHash(sb1.toString(), 64 );
SimHash hash2 = new SimHash(sb2.toString(), 64 );
int dis = hash1.getDistance(hash1.getStrSimHash() , hash2.getStrSimHash());
DecimalFormat decimalFormat = new DecimalFormat(".00");
System.out.println(hash1.hammingDistance(hash2) + " " + dis);
System.out.println("hash1和hash2的相似率:"+ decimalFormat.format((dis/64.0)));
String outpath = "D:\\develop\\dxadd-main\\dxadd-main\\Check\\test\\output.txt";
String content = "\r\n抄袭版论文的文件的绝对路径:" + path + "\r\n论文原文的绝对路径:" + txtPath + "\r\n论文重复率为:" + decimalFormat.format((dis/64.0));
ReadTxt.writeTxt(outpath, content);
} catch (NullPointerException e1) {
System.out.println("输入路径错误或者文件不存在!");
e1.printStackTrace();
} catch (Exception e) {
System.out.println("输入错误导致程序出错!");
e.printStackTrace();
}
}
}
ReadTxt:
点击查看代码
package com.my.check;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStreamReader;
public class ReadTxt {
/**传入txt路径读取txt文件
* @param txtPath
* @return 返回读取到的内容
*/
public static StringBuffer readTxt(String txtPath) {
File file = new File(txtPath);
if(file.isFile() && file.exists()){
try (FileInputStream fileInputStream = new FileInputStream(file);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);){
// FileInputStream fileInputStream = new FileInputStream(file);
// InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream);
// BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
StringBuffer sb = new StringBuffer();
String text = null;
while((text = bufferedReader.readLine()) != null){
sb.append(text);
}
return sb;
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
/**使用FileOutputStream来写入txt文件
* @param txtPath txt文件路径
* @param content 需要写入的文本
*/
public static void writeTxt(String txtPath,String content){
File file = new File(txtPath);
try (FileOutputStream fileOutputStream = new FileOutputStream(file);){
if(!file.exists()){
//判断文件是否存在,如果不存在就新建一个txt
file.createNewFile();
}
fileOutputStream.write(content.getBytes());
fileOutputStream.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
StringBuffer sb = ReadTxt.readTxt("D:\\develop\\dxadd-main\\dxadd-main\\Check\\test\\orig.txt");
System.out.println(sb.toString());
}
}
SimHash:
点击查看代码
package com.my.check;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
public class SimHash {
private String tokens;
private BigInteger intSimHash;
private String strSimHash;
private int hashbits;
public SimHash(String tokens) {
this .tokens = tokens;
this .intSimHash = this .simHash();
}
public SimHash(String tokens, int hashbits) {
this .tokens = tokens;
this .hashbits = hashbits;
this .intSimHash = this .simHash();
}
// HashMap<String, integer=" "> wordMap = new HashMap<String, integer=" ">();
public BigInteger simHash() {
// 定义特征向量/数组
int [] v = new int [ this .hashbits];
// 1、将文本去掉格式后, 分词.
StringTokenizer stringTokens = new StringTokenizer( this .tokens,",。!、:“”");
while (stringTokens.hasMoreTokens()) {
String temp = stringTokens.nextToken();
// System.out.println(temp);
// 2、将每一个分词hash为一组固定长度的数列.比如 64bit 的一个整数.
BigInteger t = this .hash(temp);
for ( int i = 0 ; i < this .hashbits; i++) {
BigInteger bitmask = new BigInteger( "1" ).shiftLeft(i);
// 3、建立一个长度为64的整数数组(假设要生成64位的数字指纹,也可以是其它数字),
// 对每一个分词hash后的数列进行判断,如果是1000...1,那么数组的第一位和末尾一位加1,
// 中间的62位减一,也就是说,逢1加1,逢0减1.一直到把所有的分词hash数列全部判断完毕.
if (t.and(bitmask).signum() != 0 ) {
// 这里是计算整个文档的所有特征的向量和
// 这里实际使用中需要 +- 权重,而不是简单的 +1/-1,
v[i] += 1 ;
} else {
v[i] -= 1 ;
}
}
}
BigInteger fingerprint = new BigInteger( "0" );
StringBuffer simHashBuffer = new StringBuffer();
for ( int i = 0 ; i < this .hashbits; i++) {
// 4、最后对数组进行判断,大于0的记为1,小于等于0的记为0,得到一个 64bit 的数字指纹/签名.
if (v[i] >= 0 ) {
fingerprint = fingerprint.add( new BigInteger( "1" ).shiftLeft(i));
simHashBuffer.append( "1" );
} else {
simHashBuffer.append( "0" );
}
}
this .strSimHash = simHashBuffer.toString();
// System.out.println( this .strSimHash + " length " + this .strSimHash.length());
return fingerprint;
}
public BigInteger simHash2() {
// 定义特征向量/数组
int [] v = new int [ this .hashbits];
// 1、将文本去掉格式后, 分词.
StringTokenizer stringTokens = new StringTokenizer( this .tokens,",。!、:“”");
while (stringTokens.hasMoreTokens()) {
String temp = stringTokens.nextToken();
// 2、将每一个分词hash为一组固定长度的数列.比如 64bit 的一个整数.
BigInteger t = this .hash(temp);
for ( int i = 0 ; i < this .hashbits; i++) {
BigInteger bitmask = new BigInteger( "1" ).shiftLeft(i);
// 3、建立一个长度为64的整数数组(假设要生成64位的数字指纹,也可以是其它数字),
// 对每一个分词hash后的数列进行判断,如果是1000...1,那么数组的第一位和末尾一位加1,
// 中间的62位减一,也就是说,逢1加1,逢0减1.一直到把所有的分词hash数列全部判断完毕.
if (t.and(bitmask).signum() != 0 ) {
// 这里是计算整个文档的所有特征的向量和
// 这里实际使用中需要 +- 权重,而不是简单的 +1/-1,
v[i] += 1 ;
} else {
v[i] -= 1 ;
}
}
}
BigInteger fingerprint = new BigInteger( "0" );
StringBuffer simHashBuffer = new StringBuffer();
for ( int i = 0 ; i < this .hashbits; i++) {
// 4、最后对数组进行判断,大于0的记为1,小于等于0的记为0,得到一个 64bit 的数字指纹/签名.
if (v[i] >= 0 ) {
fingerprint = fingerprint.add( new BigInteger( "1" ).shiftLeft(i));
simHashBuffer.append( "1" );
} else {
simHashBuffer.append( "0" );
}
}
this .strSimHash = simHashBuffer.toString();
System.out.println( this .strSimHash + " length " + this .strSimHash.length());
return fingerprint;
}
private BigInteger hash(String source) {
if (source == null || source.length() == 0 ) {
return new BigInteger( "0" );
} else {
char [] sourceArray = source.toCharArray();
BigInteger x = BigInteger.valueOf((( long ) sourceArray[ 0 ]) << 7 );
BigInteger m = new BigInteger( "1000003" );
BigInteger mask = new BigInteger( "2" ).pow( this .hashbits).subtract( new BigInteger( "1" ));
for ( char item : sourceArray) {
BigInteger temp = BigInteger.valueOf(( long ) item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor( new BigInteger(String.valueOf(source.length())));
if (x.equals( new BigInteger( "-1" ))) {
x = new BigInteger( "-2" );
}
return x;
}
}
public int hammingDistance(SimHash other) {
BigInteger x = this .intSimHash.xor(other.intSimHash);
int tot = 0 ;
// 统计x中二进制位数为1的个数
// 我们想想,一个二进制数减去1,那么,从最后那个1(包括那个1)后面的数字全都反了,对吧,然后,n&(n-1)就相当于把后面的数字清0,
// 我们看n能做多少次这样的操作就OK了。
while (x.signum() != 0 ) {
tot += 1 ;
x = x.and(x.subtract( new BigInteger( "1" )));
}
return tot;
}
public int getDistance(String str1, String str2) {
int distance;
if (str1.length() != str2.length()) {
distance = - 1 ;
} else {
distance = 0 ;
for ( int i = 0 ; i < str1.length(); i++) {
if (str1.charAt(i) == str2.charAt(i)) {
distance++;
}
}
}
return distance;
}
// public List subByDistance(SimHashDemo simHash, int distance) {
// // 分成几组来检查
// int numEach = this .hashbits / (distance + 1 );
// List characters = new ArrayList();
//
// StringBuffer buffer = new StringBuffer();
//
// int k = 0 ;
// for ( int i = 0 ; i < this .intSimHash.bitLength(); i++) {
// // 当且仅当设置了指定的位时,返回 true
// boolean sr = simHash.intSimHash.testBit(i);
//
// if (sr) {
// buffer.append( "1" );
// } else {
// buffer.append( "0" );
// }
//
// if ((i + 1 ) % numEach == 0 ) {
// // 将二进制转为BigInteger
// BigInteger eachValue = new BigInteger(buffer.toString(), 2 );
// System.out.println( "----" + eachValue);
// buffer.delete( 0 , buffer.length());
// characters.add(eachValue);
// }
// }
//
// return characters;
// }
public String getTokens() {
return tokens;
}
public void setTokens(String tokens) {
this.tokens = tokens;
}
public BigInteger getIntSimHash() {
return intSimHash;
}
public void setIntSimHash(BigInteger intSimHash) {
this.intSimHash = intSimHash;
}
public String getStrSimHash() {
return strSimHash;
}
public void setStrSimHash(String strSimHash) {
this.strSimHash = strSimHash;
}
public static void main(String[] args) {
String s = "This is a test string for testing" ;
SimHash hash1 = new SimHash(s, 64 );
System.out.println(hash1.intSimHash + " " + hash1.intSimHash.bitLength());
// hash1.subByDistance(hash1, 3 );
s = "This is a test string for testing, This is a test string for testing abcdef" ;
SimHash hash2 = new SimHash(s, 64 );
System.out.println(hash2.intSimHash + " " + hash2.intSimHash.bitCount());
// hash1.subByDistance(hash2, 3 );
s = "This is a test string for testing als" ;
SimHash hash3 = new SimHash(s, 64 );
System.out.println(hash3.intSimHash + " " + hash3.intSimHash.bitCount());
// hash1.subByDistance(hash3, 4 );
System.out.println( "============================" );
int dis = hash1.getDistance(hash1.strSimHash, hash2.strSimHash);
System.out.println(hash1.hammingDistance(hash2) + " " + dis);
System.out.println("hash1和hash2的相似率:"+ (dis/64.0));
int dis2 = hash1.getDistance(hash1.strSimHash, hash3.strSimHash);
System.out.println(hash1.hammingDistance(hash3) + " " + dis2);
System.out.println("hash1和hash3的相似率:"+ (dis/64));
//通过Unicode编码来判断中文
// String str = "中国chinese" ;
// for ( int i = 0 ; i < str.length(); i++) {
// System.out.println(str.substring(i, i + 1 ).matches( "[\\u4e00-\\u9fbb]+" ));
// }
}
}
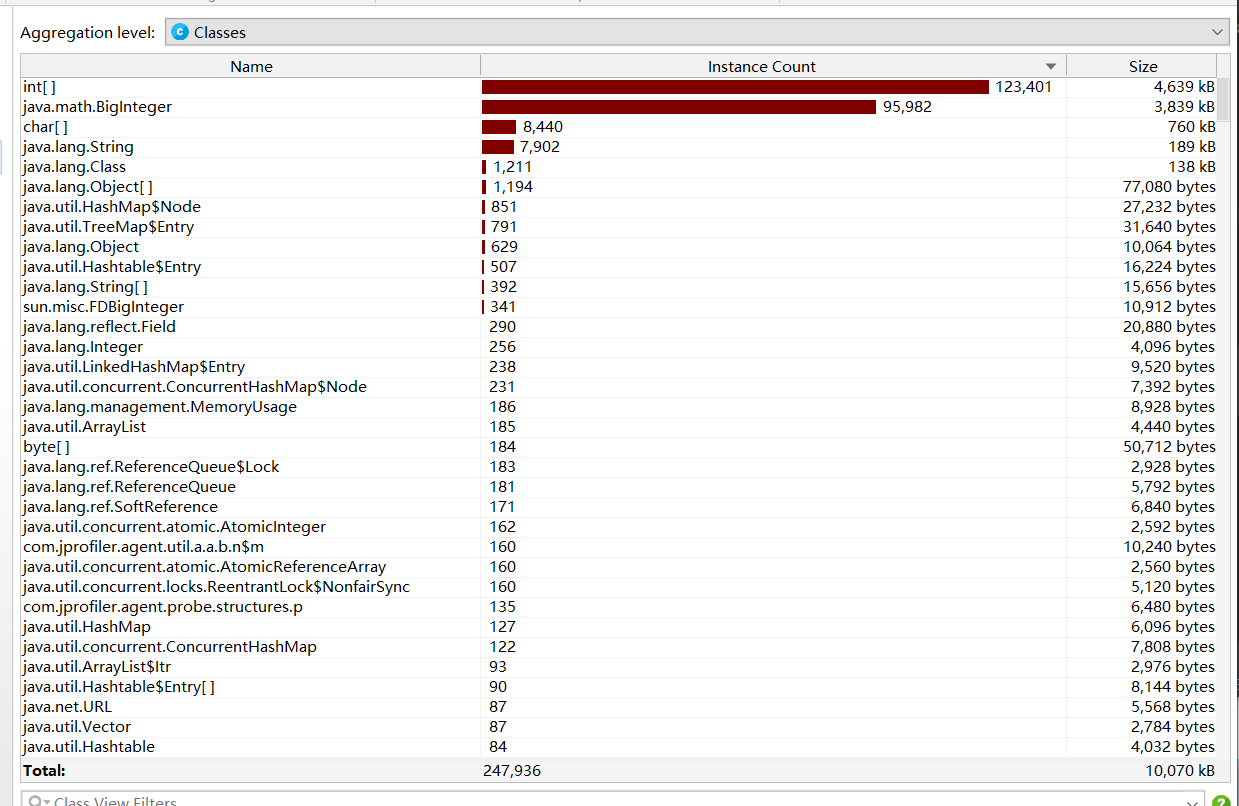
5.JProfile测试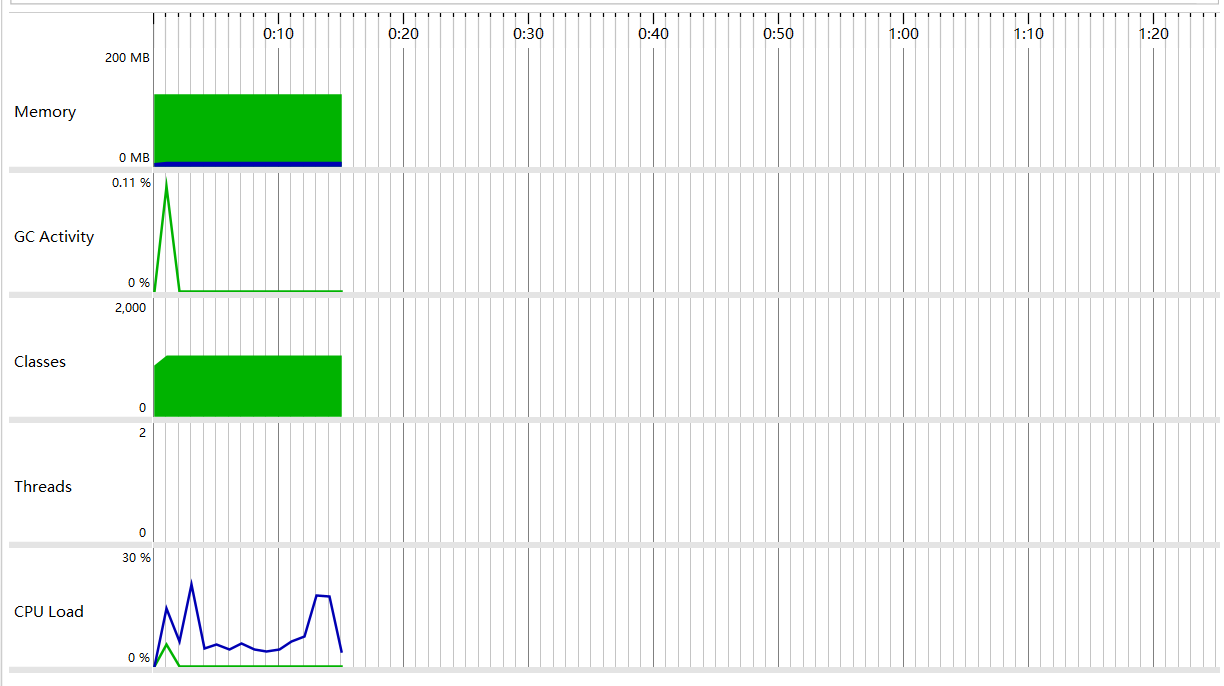
6.结果
输出结果:orig2.txt为我个人创建和原文一模一样的文本
可知输出成功,与原文一致
orig.txt依次与orig_0.8_add.txt,orig_0.8_del.txt,orig_0.8_dis_1.txt,orig_0.8_dis_10.txt,orig_0.8_dis_15.txt比较,并将结果输出到output.txt
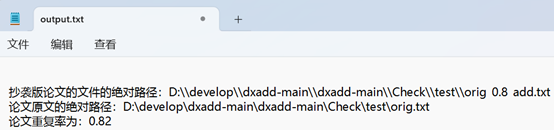
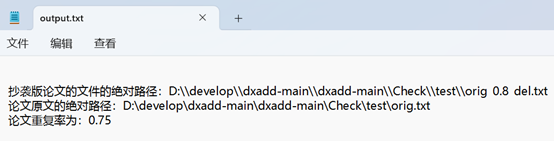
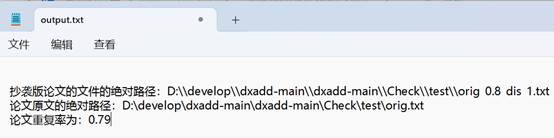
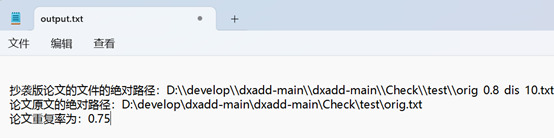
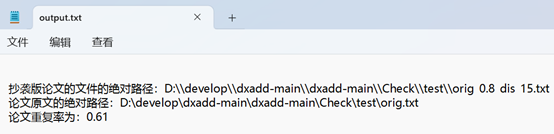
结果文件

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步