

python数据分析处理库-Pandas
1、读取数据
import pandas
food_info = pandas.read_csv("food_info.csv")
print(type(food_info)) # <class 'pandas.core.frame.DataFrame'>
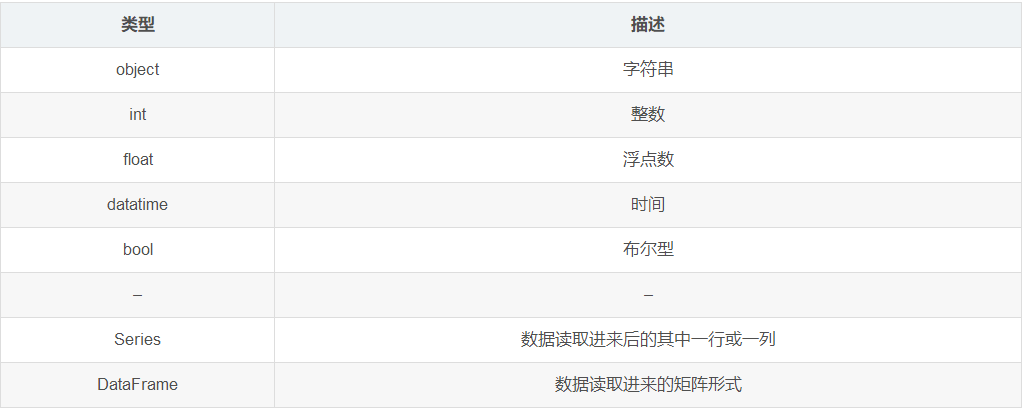
2、数据类型
3、数据显示
food_info.head() # 显示读取数据的前5行
food_info.head(3) # 显示读取数据的前3行
food_info.tail(3) # 显示读取数据的后3行
food_info.columns # 列名
food_indo.shape # 数据规格
food_info.loc[0] # 第0行数据
food_info.loc[3:6] # 第3-6行数据
food_info.log[83,"NDB_No"] # 读取第83行的NDB_No数据
food_info["NDB_No"] # 通过列名读取列
columns = ["Zinc_(mg)", "Copper_(mg)"]
food_info[columns] # 读取多个列
# 读取单位为g的列
col_names = food_info.columns.tolist() # 列名
gram_columns = []
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df = food_info[gram_columns]
4、数据操作
# 对该列每一个值都除以1000,+-*同理
food_info["Iron_(mg)"] / 1000
# 维度相同的列对应元素相乘
water_energy = food_info["Water_(g)"] * food_info["Energ_Kcal"]
# 添加新的一列
iron_grams = food_info["Iron_(mg)"] / 1000
food_info["Iron_(g)"] = iron_grams
# 最大值
food_info["Energ_Kcal"].max()
# 排序 inplace-是否新生成一个DataFrame ascending-默认为True
food_info.sort_values("Sodium_(mg)", inplace=True, ascending=False)
# 将排序后的数据的索引值重置,生成新的索引
new_titanic_survival = titanic_survival.sort_values("Age",ascending=False)
new_titanic_survival.reset_index(drop=True)
5、缺失值处理
# 缺失值 pd.isnull(age) titanic_survival["Age"].mean() # 去掉缺失值后的平均值 #去掉含有缺失值的数据 titanic_survival.dropna(axis=1) # 丢掉含有缺失值的列 titanic_survival.dropna(axis=0,subset=["Age", "Sex"]) # 丢掉"Age"与"Sex"中含有缺失值的行
6、简单的统计函数
# 统计在不同船舱中获救人数的平均值 aggfunc-默认为求均值 passenger_survival = titanic_survival.pivot_table(index="Pclass", values="Survived", aggfunc=np.mean)
7、自定义函数
# 返回行值
def hundredth_row(column):
# Extract the hundredth item
hundredth_item = column.loc[99]
return hundredth_item
hundredth_row = titanic_survival.apply(hundredth_row)
# 置换列值
def which_class(row):
pclass = row['Pclass']
if pd.isnull(pclass):
return "Unknown"
elif pclass == 1:
return "First Class"
elif pclass == 2:
return "Second Class"
elif pclass == 3:
return "Third Class"
classes = titanic_survival.apply(which_class, axis=1)
8、Series结构
from pandas import Series series_custom = Series(rt_scores , index=film_names) series_custom[['Minions (2015)', 'Leviathan (2014)']]

