
mysql索引优化-01
1.1索引是什么?
mysql官方对于索引的定义:可以帮助mysql高效的获取数据的数据结构。
mysql在存储数据之外,数据库系统中还维护着满足特定查找算法的数据结构,这些数据结构给以某种引用或者说指向表中的数据,这样我们就可以通过数据结构上实现高级的查找算法来快速查找到我们想要的数据。这种数据结构就是索引。
我们可以简单的理解索引就是“排好序的可以快速查找数据的数据结构!”,类似于新华字典的一个目录。
1.2索引数据结构
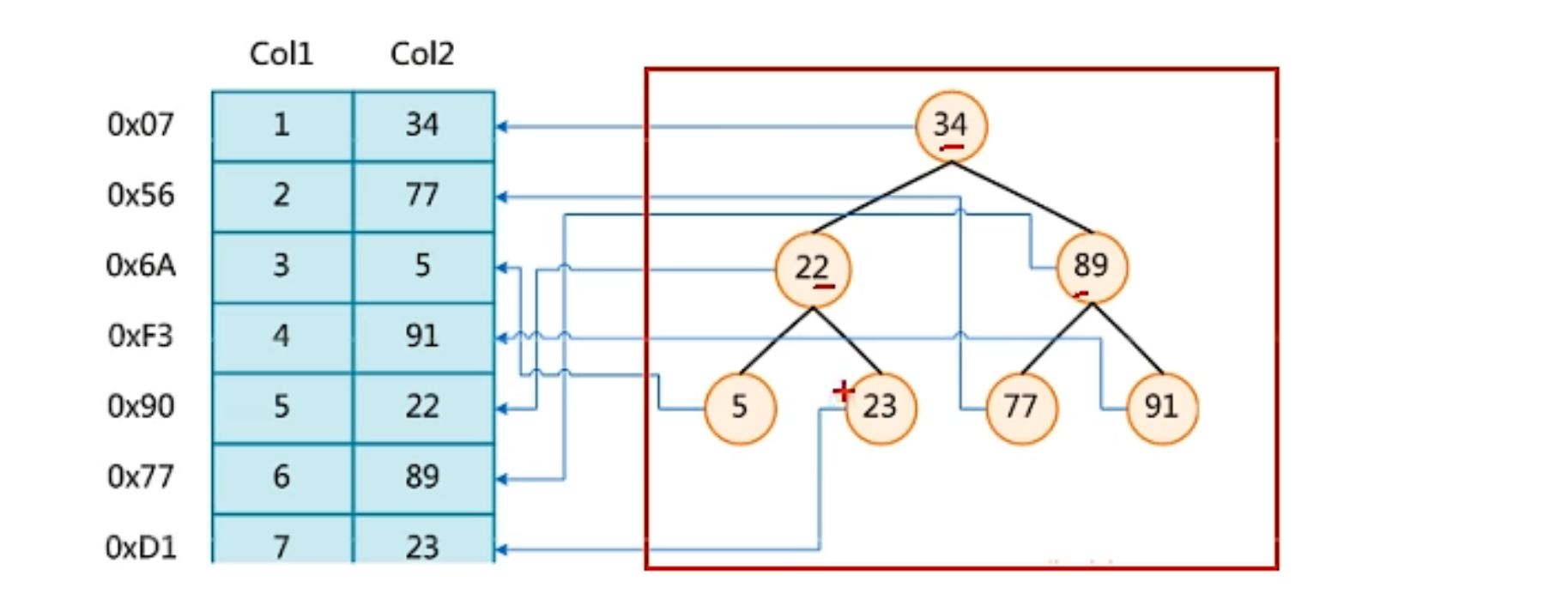
下图就是可能的二叉树的索引方式:左边的是表,总共有2列数据。如果sql查询的条件是where col2 = 89,如果不使用索引的话,那么会一直进行for循环一次一次往下找,那么这里的例子就会找6次,在第6次才会找到这个值,而是用数据结构的话,那么只需要对比1次,刚好比34大,这种情况就直接找到了,对于大数据量来说,这种方式会高效很多!
这种二叉树的弊端:当极端情况下,数据进行递增插入的时候,会一直向右边进行插入,形成链表,查询的效率会降低!因为又会开始进行遍历了。
mysql中常用的数据结构有BTree(Myisam普通索引),B+Tree索引(Innodb普通索引),Hash索引(memory存储引擎)等,但是一般都是使用的Innodb存储引擎。
1.3为什么要使用索引?
提高数据检索的效率,降低数据的IO成本。
通过索引来对数据进行排序,降低数据排序的成本,可以降低CPU的消耗。
1.4索引这么好,那有什么缺点呢?
索引实际上也是一张表,保存的主键和索引的字段,并且指向实体表的记录,所以索引也是需要占用空间的。在索引大大提高查询速度的时候,缺会降低表的更新速度,在对表进行数据CRUD的时候,mysql不仅要更新数据,还需要保存索引文件信息。每次更新添加了索引的列的字段的时候都会去调整因为更新所带来的减值变化后的信息。这些都是需要消耗时间和空间。
1.5索引的使用场景是什么呢?
1.5.1适合创建索引的场景
1.主键自动建立的唯一索引
2.频繁作为查询条件的字段应该创建索引(where 后面的语句)
3.查询中与其他表关联的字段,外键关系建立索引。
4.多字段查询下倾向创建组合索引
5.查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度
6.查询中统计或者分组的字段
1.5.2 不适合创建索引的场景:
1. 表的记录太少
2. 经常增删改的表
3.where 条件里面用不到的字段不建立索引
1.6索引的分类(重点学习)
1.6.1主键索引
1.表中的列添加了主键的约束之后,数据库会自动的建立主键索引
2.单独创建主键索引和删除主键索引的语法:
alter table 表名 add primary key (字段)
drop table 表名 drop primary key
1.6.2 唯一索引
1.表中的列创建了唯一约束时,数据库会自动创建唯一索引。
2.单独创建和删除唯一索引语法:
alter table 表名 add unique on 表名(字段)
或者 create unique index 索引名 on 表名(字段)
drop index 索引名 on 表名
1.6.3 单值索引
单值索引就是一个索引只包含单个列,一个表可以有多个单值索引。
1.建表的时候可以随着表一起建立单值索引
2.单独创建和删除单值索引:
alter table 表名 add index 索引(字段)
或者 create index 索引名 on 表名(字段)
1.6.4符合索引
符合索引就是一个索引包含了多个列:
1.建表的时候可以随着表一起进行简历复合索引
2.单独创建索引和删除复合索引:
create index 索引名 on 表名(字段1,字段2)
或者 alter table 表名 add index 索引名(字段1,字段2)
删除复合索引:drop index 索引名 on 表名
本文来自博客园,作者:程序员鲜豪,转载请注明原文链接:https://www.cnblogs.com/hg-blogs/p/17052669.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律