
kafka学习笔记01
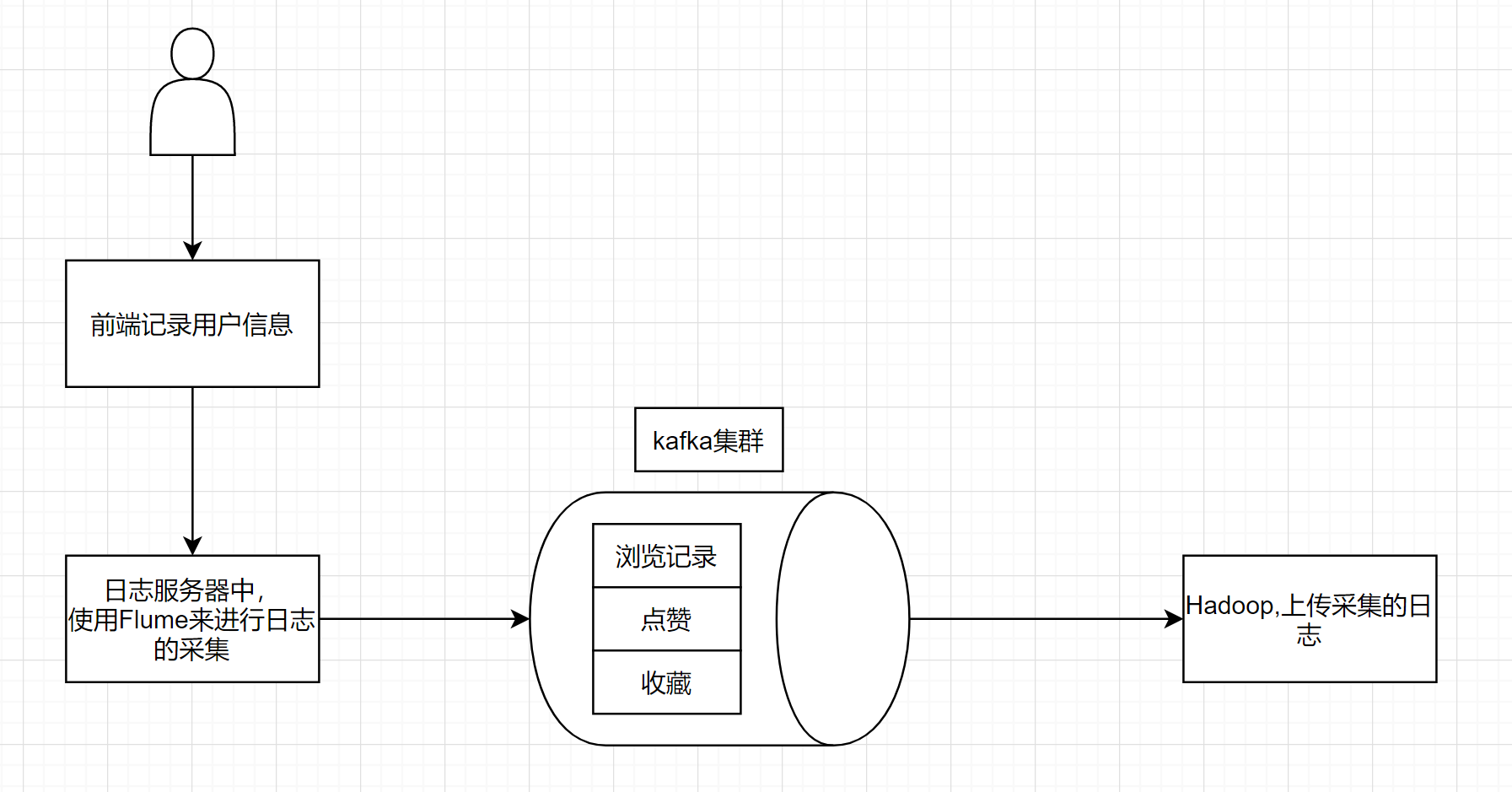
类似于京东商城这种电商系统,一般会在前端页面进行埋点记录仪用户的行为数据,包括浏览、点赞、收藏、评论等。这些行为会被记录到日志服务器中,使用Flume进行采集,然后传入Hadoop中。
Flume采集的数据,在日常中一般是小于每秒100M的,Hadoop的上传速度一般也是每秒100M左右,但是一旦出现双十一这种类似的活动的话,那么就有可能会出现问题,Flume的采集速度就会大于每秒200M,那么我们的Hadoop的上传速度已经跟不上了,所以我们就需要一个方式来讲采集到的日志信息进行一个缓冲,kafka就这样诞生了。
在Flume和Hadoop中间加一个kafka集群来进行处理数据, 大kafka是专门用来处理大量的数据用的,所以将大量的数据存入kafka中,然后Hadoop来进行慢慢的消费上传。
kafka的定义:分布式、发布订阅模式、消息队列,多用于处理大数据实时处理领域。
什么是发布订阅:在kafka中不会将消息发送给特定的订阅者,而是将消息分为不同的类别,消费者只需要去对应的类别进行消息的消费即可,下面已一张图来展示:
本文来自博客园,作者:程序员鲜豪,转载请注明原文链接:https://www.cnblogs.com/hg-blogs/p/17021776.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话