



每日博客
MapReduce 互联网精准广告推送算法
实验目的
1.了解TF-IDF算法
2.了解关键字权重公式
3.学习使用MapReduce实现互联网精准广告推送算法
实验原理
TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数。IDF反文档频率(Inverse Document Frequency)的主要思想是:如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
要想精准的向用户推送广告。我们需要知道的一个重要因素是,用户对产品的关注程度,我们可以使用数据建模来将‘关注程度’这样一个抽象的名次转化为一个具体的数字。本次实验我们使用的关注度权重公式为:
W = TF * Log(N/DF)
TF:当前关键字在该条记录中出现的总次数;
N:总的记录数;
DF:当前关键字在所有记录中出现的条数;
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
Hadoop 2.6.0-cdh5.4.5
实验内容
传统的广告形式有很多种,但是由于没有区分用户,盲目大量投送广告导致费用增大且收效甚微,在大数据时代,我们使用协同过滤算法和TF-IDF算法来实现精准广告推送功能,合理分类哪些是确切需要本产品的用户,向其投送相关产品的广告,降低成本且提高成功率。
本实验使用微博数据,找出哪些用户对华为手机感兴趣,关注程度是怎样的,计算出权重值。从而实现选出优质用户,向优质用户精准推送华为手机广告的功能。
原始数据为:
1. 微博用户名: 微博内容:
2. 小时光***糖你好 我最近发现我的华为p10后置摄像头照相模糊。这个对于我个只会手机支付身上不带钱的用户造成很大的困扰。我刚去花粉俱乐部看了下,不只有我一个人有这样的问题。请问下p10的后置摄像头是否是批次硬件问题。以及如何解决,求回应
3. 小媳***结成风5 我的P10耗电太快
4. 人***花u 凤凰古镇
5. 全***信他 360全景图 教你手机拍微博全景图哦。
6. 你说***了没 想去拍茶卡盐湖,一望无际
7. 路***锡 岳麓山
8. 让***忧1 世界任你拍
9. 小***峰 我想去拍青海湖!华为P10plus有了,能送个机票吗
10. 19***潮 喜马拉雅
11. leo***海 最想和她在长江大桥上一起拍摄全景~
12. 花生***商 我微薄有【落霞脆】冬枣转发抽奖哦,欢迎前来围观
13. 愿我***有但是 想去大草原
14. EX***的 我用的去年买的华为 nova现在用着挺好的,以后也会继续支持华为手机的,我想去杭州西湖,可是路上缺一个充电宝
15. 捕风***冷 西藏,超漂亮的!!!而且已经去过了,可惜评论不能发图,不是会员
16. Msh***kp 香港
17. ting***15 北京 北京 上海
18. 没钱***食了 天安门?
19. 御***殿 华山
20. 梁天***博 全景
21. 星***R 迪士尼
22. 毛***狼叼走 转发微博
23. 滑***师 站在鼓楼紫峰大厦楼顶拍一张
结果数据为:
1. 19***潮 喜马拉雅:3.09104
2. EX***的 杭州:3.09104 个:2.3979 也:3.09104 买:3.09104 以后:3.09104 路上:3.09104 手机:1.94591 继续:3.09104 可是:3.09104 的:6.43775 宝:3.09104 想去:1.60944 会:3.09104 充电:3.09104 我:2.77259 现在:3.09104 nova:3.09104 支持:3.09104 华为:3.89182 用着:3.09104 缺一:3.09104 去年:3.09104 挺好:3.09104 用:3.09104 西湖:3.09104
3. Msh***kp 香港:3.09104
4. leo***海 拍摄:3.09104 长江大桥:3.09104 最想:3.09104 上:3.09104 一起:3.09104 和:3.09104 全景:2.3979 她在:3.09104
5. ting***15 上海:3.09104 北京:6.18208
6. 人***花u 凤凰:3.09104 古镇:3.09104
7. 你说***了没 茶:3.09104 卡:3.09104 想去:1.60944 盐湖:3.09104 一望无际:3.09104 拍:1.38629
8. 全***信他 拍:1.38629 360:3.09104 全景图:6.18208 哦:2.3979 微:2.3979 博:2.3979 手机:1.94591 教你:3.09104
9. 小***峰 p10plus:3.09104 青海湖:3.09104 送个:3.09104 我:1.38629 想去:1.60944 吗:3.09104 华为:1.94591 了:3.09104 机票:3.09104 拍:1.38629 能:3.09104 有:1.94591
10. 小媳***结成风5 的:1.60944 耗电:3.09104 p10:2.3979 我:1.38629 太快:3.09104
11. 小时光***糖你好 问题:6.18208 身上:3.09104 花粉:3.09104 求:3.09104 有:3.89182 最近:3.09104 是:3.09104 支付:3.09104 摄像头:6.18208 我:6.93147 很大:3.09104 如何:3.09104 华为:1.94591 以及:3.09104 个:2.3979 不只:3.09104 一个人:3.09104 p10:4.79579 对于:3.09104 造成:3.09104 解决:3.09104 模糊:3.09104 请:3.09104 的:8.04719 刚去:3.09104 硬件:3.09104 困扰:3.09104 下:3.09104 只会:3.09104 发现:3.09104 是否:3.09104 问下:3.09104 照相:3.09104 带钱:3.09104 用户:3.09104 回应:3.09104 后置:6.18208 看了:3.09104 俱乐部:3.09104 这个:3.09104 这样:3.09104 不:3.09104 批次:3.09104 手机:1.94591
12. 御***殿 华山:3.09104
13. 愿我***有但是 大草原:3.09104 想去:1.60944
14. 捕风***冷 漂亮:3.09104 可惜:3.09104 会员:3.09104 不是:3.09104 图:3.09104 已经:3.09104 而且:3.09104 的:1.60944 评论:3.09104 过了:3.09104 西藏:3.09104 超:3.09104 去:3.09104 不能:3.09104 发:3.09104
15. 星***R 迪士尼:3.09104
16. 梁天***博 全景:2.3979
17. 毛***狼叼走 微:2.3979 转发:2.3979 博:2.3979
18. 没钱***食了 天安门:3.09104
19. 滑***师 紫:3.09104 拍:1.38629 大厦:3.09104 鼓楼:3.09104 峰:3.09104 一张:3.09104 站在:3.09104 楼顶:3.09104
20. 花生***商 落霞:3.09104 抽奖:3.09104 哦:2.3979 枣:3.09104 脆:3.09104 围观:3.09104 我:1.38629 有:1.94591 前来:3.09104 冬:3.09104 欢迎:3.09104 微薄:3.09104 转发:2.3979
21. 让***忧1 任你:3.09104 拍:1.38629 世界:3.09104
22. 路***锡 岳麓山:3.09104
通过结果数据我们可以发现,每个关键字的权重已经计算出来了,如果我们想找到比较关注华为手机的用户,我们只需要把‘手机’、‘华为’、‘买’等关键字权重值高的用户提取出来即可。
实验步骤
1.首先,我们来准备实验需要用到的数据,切换到/data/mydata目录下,使用vim编辑一个tj_data.txt文件
1. cd /data/mydata
2. vim tj_data.txt
将如下数据写入其中:
1. 小时光***糖你好 我最近发现我的华为p10后置摄像头照相模糊。这个对于我个只会手机支付身上不带钱的用户造成很大的困扰。我刚去花粉俱乐部看了下,不只有我一个人有这样的问题。请问下p10的后置摄像头是否是批次硬件问题。以及如何解决,求回应
2. 小媳***结成风5 我的P10耗电太快
3. 人***花u 凤凰古镇
4. 全***信他 360全景图 教你手机拍微博全景图哦。
5. 你说***了没 想去拍茶卡盐湖,一望无际
6. 路***锡 岳麓山
7. 让***忧1 世界任你拍
8. 小***峰 我想去拍青海湖!华为P10plus有了,能送个机票吗
9. 19***潮 喜马拉雅
10. leo***海 最想和她在长江大桥上一起拍摄全景~
11. 花生***商 我微薄有【落霞脆】冬枣转发抽奖哦,欢迎前来围观
12. 愿我***有但是 想去大草原
13. EX***的 我用的去年买的华为 nova现在用着挺好的,以后也会继续支持华为手机的,我想去杭州西湖,可是路上缺一个充电宝
14. 捕风***冷 西藏,超漂亮的!!!而且已经去过了,可惜评论不能发图,不是会员
15. Msh***kp 香港
16. ting***15 北京 北京 上海
17. 没钱***食了 天安门?
18. 御***殿 华山
19. 梁天***博 全景
20. 星***R 迪士尼
21. 毛***狼叼走 转发微博
22. 滑***师 站在鼓楼紫峰大厦楼顶拍一张
2.使用wget命令下载IKAnalyzer2012_u6.jar包
1. wget http://192.168.1.100:60000/allfiles/mr_sf/IKAnalyzer2012_u6.jar
3.切换到/apps/hadoop/sbin目录下,开启Hadoop相关进程
1. cd /apps/hadoop/sbin
2. ./start-all.sh
4.输入JPS查看一下相关进程是否已经启动。
1. jps

5.在HDFS的根下创建一个/tj/input目录,并将tj_data.txt文件上传到HDFS上的/tj/input文件夹下
1. hadoop fs -mkdir /tj
2. hadoop fs -mkdir /tj/input
3. hadoop fs -put /data/mydata/tj_data.txt /tj/input
6.打开Eclipse,创建一个Java项目
项目名为:mr_sf
7.右键单击mr_sf项目,创建一个名为:mr_tj的包
8.创建一个名为:libs 的文件夹,用于存放项目所需的jar包
9.将/data/mydata文件夹下的IKAnalyzer2012_u6.jar包导入到libs文件夹下
10.右键选中IKAnalyzer2012_u6.jar,依次选择Build Path=>Add to Build Path
11.下面创建第一个MapReduce。
创建一个名为FirstMapper的类,功能为:计算该条微博中,每个词出现的次数,也就是TF功能和微博总条数(N值)
完成代码为:
1. package mr_tj;
- 2.
3. import java.io.IOException;
4. import java.io.StringReader;
- 5.
6. import org.apache.hadoop.io.IntWritable;
7. import org.apache.hadoop.io.LongWritable;
8. import org.apache.hadoop.io.Text;
9. import org.apache.hadoop.mapreduce.Mapper;
10. import org.wltea.analyzer.core.IKSegmenter;
11. import org.wltea.analyzer.core.Lexeme;
- 12.
13. public class FirstMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- 14. @Override
- 15. protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- 16. String[] line = value.toString().split("\t"); //以tab键为分隔符
- 17. if (line.length >= 2) {
- 18. String id = line[0].trim(); //微博的ID
- 19. String content = line[1].trim(); //微博的内容
- 20. StringReader sr = new StringReader(content);
- 21. IKSegmenter iks = new IKSegmenter(sr, true); //使用
- 22. Lexeme lexeme = null;
- 23. while ((lexeme = iks.next()) != null) {
- 24. String word = lexeme.getLexemeText(); //word就是分完的每个词
- 25. context.write(new Text(word + "_" + id), new IntWritable(1));//
- 26. }
- 27. sr.close();
- 28. context.write(new Text("count"), new IntWritable(1));//
- 29. } else {
- 30. System.err.println("error:" + value.toString() + "-----------------------");
- 31. }
- 32. }
33. }
12.接下来,创建一个FirstReducer类,功能为:合并相同key值的数据,输出TF及N
完整代码为:
1. package mr_tj;
2. import java.io.IOException;
3. import org.apache.hadoop.io.IntWritable;
4. import org.apache.hadoop.io.Text;
5. import org.apache.hadoop.mapreduce.Reducer;
6. public class FirstReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
- 7. @Override //text就是map中计算出来的key值
- 8. protected void reduce(Text text, Iterable<IntWritable> iterable, Context context) throws IOException, InterruptedException {
- 9. int sum = 0;
- 10. for (IntWritable intWritable : iterable) {
- 11. sum += intWritable.get();
- 12. }//计算微博总条数,并进行输出
- 13. if (text.equals("count")) {
- 14. System.out.println(text.toString() + "==" + sum);
- 15. }
- 16. context.write(text, new IntWritable(sum));
- 17. }
- 18. }
13.创建一个FirstPartition类,功能为:分区,如果key值为count,就将数据放入一个单独的分区,如果key值为其他的,就平均分配到三个分区
完整代码为:
1. package mr_tj;
2. import org.apache.hadoop.io.IntWritable;
3. import org.apache.hadoop.io.Text;
4. import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
- 5.
6. public class FirstPartition extends HashPartitioner<text, intwritable=""> {
- 7.
- 8. @Override
- 9. public int getPartition(Text key, IntWritable value, int numReduceTasks) {
- 10. //如果key值为count,就返回3,其他的key值就平均分配到三个分区,
- 11. if (key.equals(new Text("count"))) {
- 12. return 3;
- 13. } else {
- 14. return super.getPartition(key, value, numReduceTasks - 1);
15. //numReduceTasks - 1的意思是有4个reduce,其中一个已经被key值为count的占用了,所以数据只能分配到剩下的三个分区中了
16. //使用super,可以调用父类的HashPartitioner
- 17. }
- 18. }
- 19.
20. }
21. </text,>
14.创建一个FirstJob类,功能为:执行计算,得到TF和N
完整代码为:
1. package mr_tj;
2. import org.apache.hadoop.conf.Configuration;
3. import org.apache.hadoop.fs.Path;
4. import org.apache.hadoop.io.IntWritable;
5. import org.apache.hadoop.io.Text;
6. import org.apache.hadoop.mapreduce.Job;
7. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
8. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
9. public class FirstJob {
- 10. public static void main(String[] args) {
- 11. Configuration conf = new Configuration();
- 12. conf.set("yarn.resourcemanager.hostname", "zhangyu@d2e674ec1e78");
- 13. try {
- 14. Job job = Job.getInstance(conf, "weibo1");
- 15. job.setJarByClass(FirstJob.class);
- 16. //设置map任务的输出key类型,value类型
- 17. job.setOutputKeyClass(Text.class);
- 18. job.setOutputValueClass(IntWritable.class);
- 19. //设置reduce个数为4
- 20. job.setNumReduceTasks(4);
- 21. //定义一个partition表分区,哪些数据应该进入哪些分区
- 22. job.setPartitionerClass(FirstPartition.class);
- 23. job.setMapperClass(FirstMapper.class);
- 24. job.setCombinerClass(FirstReducer.class);
- 25. job.setReducerClass(FirstReducer.class);
- 26. //设置执行任务时,数据获取的目录及数据输出的目录
- 27. FileInputFormat.addInputPath(job, new Path(Paths.TJ_INPUT));
- 28. FileOutputFormat.setOutputPath(job, new Path(Paths.TJ_OUTPUT1));
- 29. if (job.waitForCompletion(true)) {
- 30. System.out.println("FirstJob-执行完毕");
- 31. TwoJob.mainJob();
- 32. }
- 33. } catch (Exception e) {
- 34. e.printStackTrace();
- 35. }
- 36. }
37. }
创建第二个MapReduce。
15.创建一个TwoMapper类,功能为:统计每个词的DF
完整代码为:
1. package mr_tj;
2. import java.io.IOException;
3. import org.apache.hadoop.io.IntWritable;
4. import org.apache.hadoop.io.LongWritable;
5. import org.apache.hadoop.io.Text;
6. import org.apache.hadoop.mapreduce.Mapper;
7. import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- 8.
9. public class TwoMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- 10.
- 11. protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- 12.
- 13. FileSplit fs = (FileSplit) context.getInputSplit();
- 14. //map时拿到split片段所在文件的文件名
- 15. if (!fs.getPath().getName().contains("part-r-00003")) {
- 16. //拿到TF的统计结果
- 17. String[] line = value.toString().trim().split("\t");
- 18. if (line.length >= 2) {
- 19. String[] ss = line[0].split("_");
- 20. if (ss.length >= 2) {
- 21. String w = ss[0];
- 22. //统计DF,该词在所有微博中出现的条数,一条微博即使出现两次该词,也算一条
- 23. context.write(new Text(w), new IntWritable(1));
- 24. }
- 25. } else {
- 26. System.out.println("error:" + value.toString() + "-------------");
- 27. }
- 28. }
- 29. }
30. }
16.创建一个TwoReducer类
完整代码为:
1. package mr_tj;
- 2.
3. import java.io.IOException;
- 4.
5. import org.apache.hadoop.io.IntWritable;
6. import org.apache.hadoop.io.Text;
7. import org.apache.hadoop.mapreduce.Reducer;
- 8.
9. public class TwoReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
- 10.
- 11. protected void reduce(Text key, Iterable<IntWritable> arg1, Context context) throws IOException, InterruptedException {
- 12.
- 13. int sum = 0;
- 14. for (IntWritable i : arg1) {
- 15. sum = sum + i.get();
- 16. }
- 17.
- 18. context.write(key, new IntWritable(sum));
- 19. }
- 20.
- 21. }
17.创建一个TwoJob类,功能为:执行计算,得到DF
完整代码为:
1. package mr_tj;
2. import org.apache.hadoop.conf.Configuration;
3. import org.apache.hadoop.fs.Path;
4. import org.apache.hadoop.io.IntWritable;
5. import org.apache.hadoop.io.Text;
6. import org.apache.hadoop.mapreduce.Job;
7. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
8. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- 9.
10. public class TwoJob {
- 11.
- 12. public static void mainJob() {
- 13. Configuration config = new Configuration();
- 14. config.set("yarn.resourcemanager.hostname", "zhangyu@d2e674ec1e78");
- 15. try {
- 16. Job job = Job.getInstance(config, "weibo2");
- 17. job.setJarByClass(TwoJob.class);
- 18. //设置map任务的输出key类型,value类型
- 19. job.setOutputKeyClass(Text.class);
- 20. job.setOutputValueClass(IntWritable.class);
- 21. job.setMapperClass(TwoMapper.class);
- 22. job.setCombinerClass(TwoReducer.class);
- 23. job.setReducerClass(TwoReducer.class);
- 24. //设置任务运行时,数据的输入输出目录,这里的输入数据是上一个mapreduce的输出
- 25. FileInputFormat.addInputPath(job, new Path(Paths.TJ_OUTPUT1));
- 26. FileOutputFormat.setOutputPath(job, new Path(Paths.TJ_OUTPUT2));
- 27. if (job.waitForCompletion(true)) {
- 28. System.out.println("TwoJob-执行完毕");
- 29. LastJob.mainJob();
- 30. }
- 31. } catch (Exception e) {
- 32. e.printStackTrace();
- 33. }
- 34. }
35. }
创建第三个MapReduce。
18.创建一个LastMapper类,功能为:执行W = TF * Log(N/DF)计算
完整代码为:
1. package mr_tj;
2. import java.io.BufferedReader;
3. import java.io.FileReader;
4. import java.io.IOException;
5. import java.net.URI;
6. import java.text.NumberFormat;
7. import java.util.HashMap;
8. import java.util.Map;
- 9.
10. import org.apache.hadoop.fs.Path;
11. import org.apache.hadoop.io.LongWritable;
12. import org.apache.hadoop.io.Text;
13. import org.apache.hadoop.mapreduce.Mapper;
14. import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- 15.
16. public class LastMapper extends Mapper<longwritable, text,="" text=""> {
- 17. public static Map<string, integer=""> cmap = null; //cmap为count
- 18. public static Map<string, integer=""> df = null;
- 19. //setup方法,表示在map之前
- 20. protected void setup(Context context) throws IOException, InterruptedException {
- 21. if (cmap == null || cmap.size() == 0 || df == null || df.size() == 0) {
- 22.
- 23. URI[] ss = context.getCacheFiles();
- 24. if (ss != null) {
- 25. for (int i = 0; i < ss.length; i++) {
- 26. URI uri = ss[i];
- 27. //判断如果该文件是part-r-00003,那就是count文件,将数据取出来放入到一个cmap中
- 28. if (uri.getPath().endsWith("part-r-00003")) {
- 29. Path path = new Path(uri.getPath());
- 30. BufferedReader br = new BufferedReader(new FileReader(path.getName()));
- 31. String line = br.readLine();
- 32. if (line.startsWith("count")) {
- 33. String[] ls = line.split("\t");
- 34. cmap = new HashMap<string, integer="">();
- 35. cmap.put(ls[0], Integer.parseInt(ls[1].trim()));
- 36. }
- 37. br.close();
- 38. } else {
- 39. //其他的认为是DF文件,将数据取出来放到df中
- 40. df = new HashMap<string, integer="">();
- 41. Path path = new Path(uri.getPath());
- 42. BufferedReader br = new BufferedReader(new FileReader(path.getName()));
- 43. String line;
- 44. while ((line = br.readLine()) != null) {
- 45. String[] ls = line.split("\t");
- 46. df.put(ls[0], Integer.parseInt(ls[1].trim()));
- 47. //df这个map以单词作为key,以单词的df值作为value
- 48. }
- 49. br.close();
- 50. }
- 51. }
- 52. }
- 53. }
- 54. }
- 55.
- 56. protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- 57. FileSplit fs = (FileSplit) context.getInputSplit();
- 58.
- 59. if (!fs.getPath().getName().contains("part-r-00003")) {
- 60.
- 61. String[] v = value.toString().trim().split("\t");
- 62. if (v.length >= 2) {
- 63. int tf = Integer.parseInt(v[1].trim());
- 64. String[] ss = v[0].split("_");
- 65. if (ss.length >= 2) {
- 66. String w = ss[0];
- 67. String id = ss[1];
- 68. //执行W = TF * Log(N/DF)计算
- 69. double s = tf * Math.log(cmap.get("count") / df.get(w));
- 70. //格式化,保留小数点后五位
- 71. NumberFormat nf = NumberFormat.getInstance();
- 72. nf.setMaximumFractionDigits(5);
- 73. //以 微博id+词:权重 输出
- 74. context.write(new Text(id), new Text(w + ":" + nf.format(s)));
- 75. }
- 76. } else {
- 77. System.out.println(value.toString() + "-------------");
- 78. }
- 79. }
- 80. }
81. }
82. </string,></string,></string,></string,></longwritable,>
19.创建一个LastReduce类
完整代码为:
1. package mr_tj;
- 2.
3. import java.io.IOException;
- 4.
5. import org.apache.hadoop.io.Text;
6. import org.apache.hadoop.mapreduce.Reducer;
- 7.
8. public class LastReduce extends Reducer<Text, Text, Text, Text> {
- 9.
- 10. protected void reduce(Text key, Iterable<Text> arg1, Context context) throws IOException, InterruptedException {
- 11.
- 12. StringBuffer sb = new StringBuffer();
- 13.
- 14. for (Text i : arg1) {
- 15. sb.append(i.toString() + "\t");
- 16. }
- 17.
- 18. context.write(key, new Text(sb.toString()));
- 19. }
- 20.
- 21. }
20.创建一个LastJob类,功能为:运行第三个MR
完整代码为:
1. package mr_tj;
- 2.
3. import org.apache.hadoop.conf.Configuration;
4. import org.apache.hadoop.fs.Path;
5. import org.apache.hadoop.io.Text;
6. import org.apache.hadoop.mapreduce.Job;
7. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
8. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- 9.
10. public class LastJob {
- 11.
- 12. public static void mainJob() {
- 13. Configuration config = new Configuration();
- 14. config.set("yarn.resourcemanager.hostname", "zhangyu@d2e674ec1e78");
- 15. try {
- 16. Job job = Job.getInstance(config, "weibo3");
- 17. job.setJarByClass(LastJob.class);
- 18. //将第一个job和第二个job的输出作为第三个job的输入
- 19. //
- 20. job.addCacheFile(new Path(Paths.TJ_OUTPUT1 + "/part-r-00003").toUri());
- 21. //
- 22. job.addCacheFile(new Path(Paths.TJ_OUTPUT2 + "/part-r-00000").toUri());
- 23.
- 24. job.setOutputKeyClass(Text.class);
- 25. job.setOutputValueClass(Text.class);
- 26. // job.setMapperClass();
- 27. job.setMapperClass(LastMapper.class);
- 28. job.setCombinerClass(LastReduce.class);
- 29. job.setReducerClass(LastReduce.class);
- 30.
- 31. FileInputFormat.addInputPath(job, new Path(Paths.TJ_OUTPUT1));
- 32. FileOutputFormat.setOutputPath(job, new Path(Paths.TJ_OUTPUT3));
- 33. if (job.waitForCompletion(true)) {
- 34. System.out.println("LastJob-执行完毕");
- 35. System.out.println("全部工作执行完毕");
- 36. }
- 37. } catch (Exception e) {
- 38. e.printStackTrace();
- 39. }
- 40. }
41. }
21.创建一个Paths类,功能为:定义输入输出目录
完整代码为:
1. package mr_tj;
- 2.
3. public class Paths {
- 4. public static final String TJ_INPUT = "hdfs://localhost:9000/tj/input";
- 5. public static final String TJ_OUTPUT1 = "hdfs://localhost:9000/tj/output1";
- 6. public static final String TJ_OUTPUT2 = "hdfs://localhost:9000/tj/output2";
- 7. public static final String TJ_OUTPUT3 = "hdfs://localhost:9000/tj/output3";
8. }
22.在FirstJob类中,单机右键,依次选择Run As=> Run on Hadoop
可以在Console界面看到执行进度
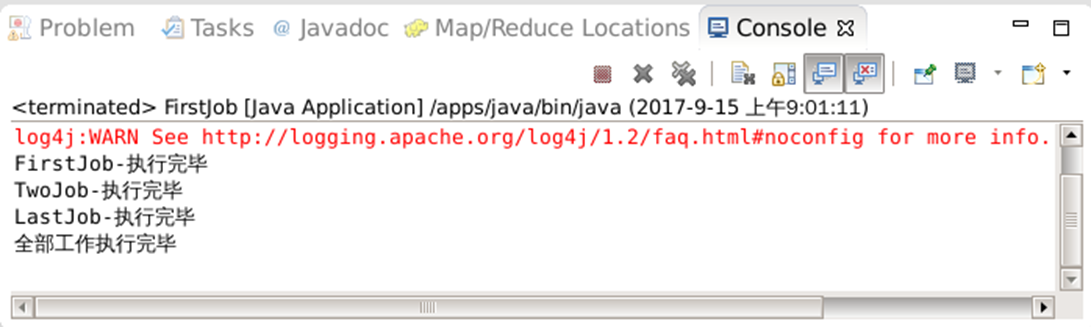
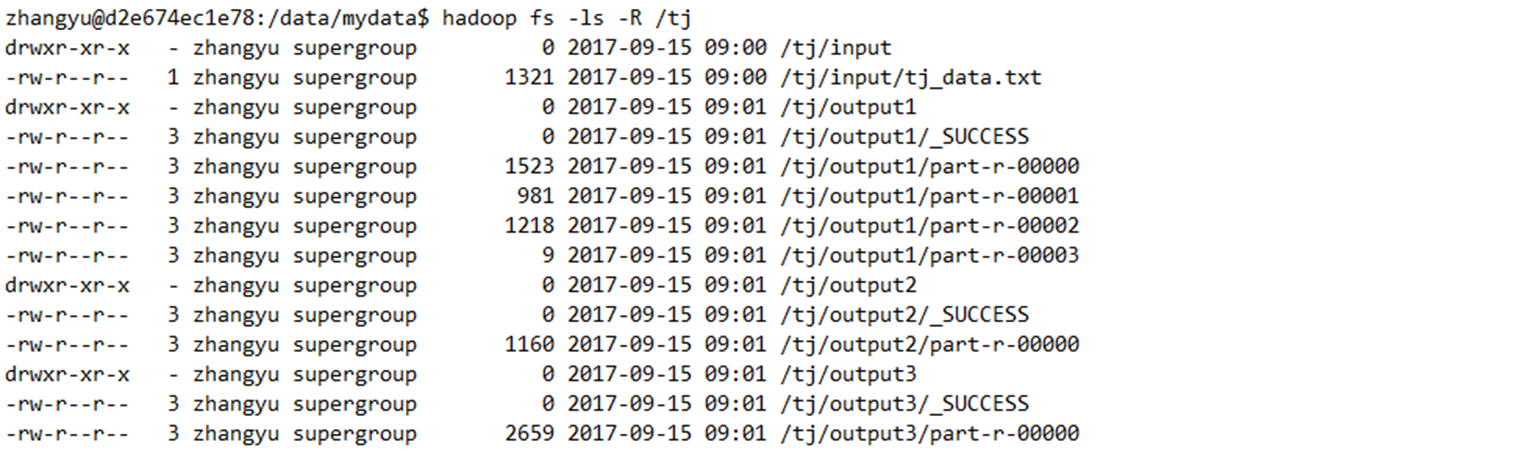
23.在HDFS上查看一下结果数据
1. hadoop fs -ls -R /tj
24.查看一下各关键字的权重
1. hadoop fs -cat /tj/output3/part-r-00000

得到各关键字的权重后就可以知道哪些是关注华为手机的优质用户了,我们再向这些优质用户投送华为手机的广告,就可以达到精准广告推送的效果了。

