Zookeeper 运维实践手册
Zookeeper是一个高可用的分布式数据管理与协调框架,该框架能很好地保证分布式环境中数据一致性。一般用来实现服务发现(类似DNS),配置管理,分布式锁,leader选举等。
一、生产环境中Zookeeper安装部署规范
生产环境建议zookeeper至少为三台集群,统一安装配置,版本号为近期新版本,比如版本为3.4.8
部署路径:/opt/业务模块名/zookeeper
配置文件:/opt/业务模块名/zookeeper/conf/zoo.cfg
存储快照文件snapshot的目录:/opt/业务模块名/zookeeper/data
事务日志输出目录:/var/log/业务模块名/zookeeper
运行日志输出目录:/var/log/业务模块名/zookeeper
Zookeeper所有端口需要提前开通防火墙入站规则
对外服务端口:默认2181,可自定义
通信端口:2888,可自定义
选举端口:3888,可自定义
autoperge默认关闭,建议自行编写脚本在业务低谷期清理快照和事务日志
查询状态:sh /opt/业务模块名/zookeeper/zkServer.sh status
启动服务:sh /opt/业务模块名/zookeeper/zkServer.sh start
停止服务:sh /opt/业务模块名/zookeeper/zkServer.sh stop
配置文件conf/zoo.cfg示例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial# synchronization phase can takeinitLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.dataDir=/opt/kevintest/zookeeper_22181/data# the port at which the clients will connectclientPort=22181# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the# administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1dataLogDir=/var/log/kevintest/zookeeper_22181server.1=192.168.10.91:22888:23888server.2=192.168.10.91:22988:23988server.3=192.168.10.92:22888:23888 |
conf/log4j.properties配置示例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
# Define some default values that can be overridden by system propertieszookeeper.root.logger=INFO,ROLLINGFILEzookeeper.console.threshold=INFOzookeeper.log.dir=.zookeeper.log.file=zookeeper.logzookeeper.log.threshold=DEBUGzookeeper.tracelog.dir=.zookeeper.tracelog.file=zookeeper_trace.log ## ZooKeeper Logging Configuration# # Format is "<default threshold> (, <appender>)+ # DEFAULT: console appender onlylog4j.rootLogger=${zookeeper.root.logger} # Example with rolling log file#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE # Example with rolling log file and tracing#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE ## Log INFO level and above messages to the console#log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppenderlog4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayoutlog4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n ## Add ROLLINGFILE to rootLogger to get log file output# Log DEBUG level and above messages to a log filelog4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file} # Max log file size of 10MB#log4j.appender.ROLLINGFILE.MaxFileSize=10MB# uncomment the next line to limit number of backup fileslog4j.appender.ROLLINGFILE.MaxBackupIndex=10 log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayoutlog4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n ## Add TRACEFILE to rootLogger to get log file output# Log DEBUG level and above messages to a log filelog4j.appender.TRACEFILE=org.apache.log4j.FileAppenderlog4j.appender.TRACEFILE.Threshold=TRACElog4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file} log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout### Notice we are including log4j's NDC here (%x)log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n |
conf/zookeeper-env.sh文件配置示例如下:
|
1
2
|
ZOO_LOG_DIR="/var/log/kevintest/zookeeper_22181/"ZOO_LOG4J_PROP="INFO,ROLLINGFILE |
二、Zookeeper最佳实践
必须了解以下ZK知识点,才能熟练地对ZK进行维护:
- zookeeper集群里分三种角色: Leader, Follower和Observer。Leader和Follower参与投票,Observer只会『听』投票的结果,不参与投票。
- 投票集群里的节点数要求是奇数
- 一个集群容忍挂掉的节点数的等式为 N = 2F + 1,N为投票集群节点数,F为能同时容忍失败节点数。比如一个三节点集群,可以挂掉一个节点,5节点集群可以挂掉两个...
- 一个写操作需要半数以上的节点ack,所以集群节点数越多,整个集群可以抗挂点的节点数越多(越可靠),但是吞吐量越差。
- Zookeeper里所有节点以及节点的数据都会放在内存里,形成一棵树的数据结构。并且定时的dump snapshot到磁盘。
- Zookeeper的Client与Zookeeper之间维持的是长连接,并且保持心跳,Client会与Zookeeper之间协商出一个Session超时时间出来(其实就是Zookeeper
Server里配置了最小值,最大值,如果client的值在这两个值之间则采用client的,小于最小值就是最小值,大于最大值就用最大值),如果在Session超时时间内没有收到心跳,则该Session过期。
- Client可以watch Zookeeper那个树形数据结构里的某个节点或数据,当有变化的时候会得到通知。
1)最小生产集群
要确保Zookeeper能够稳定运行,那么就需要确保投票能够正常进行,最好不要挂一个节点整个就不work了,所以我们一般要求生产环境最少3个节点部署。
2)网络
除了节点外,还要看不能一台物理机器,一个机柜或一个交换机挂掉然后影响了整个集群,所以节点网络结构也要考虑,这个可能就比很多应用服务器的要求更加严格。
3)分Group,保护核心Group
要确保Zookeeper整个集群可靠运行,就是要确保投票集群可靠。那在我们这里,将一个Zookeeper集群划分为多个小的Group,我们称Leader+Follower为核心Group,核心Group我们一般是不向外提供服务的,然后我们会根据不同的业务再加一些Observer,比如一个Zookeeper集群为服务发现,消息,定时任务三个不同的组件提供服务,那么我们为建立三个Observer
Group,分别给这三个组件使用,而Client只会连接分配给它的Observer
Group,不去连接核心Group。这样核心Group就不会给Client提供长连接服务,也不负责长连接的心跳,这大大的减轻了核心Group的压力,因为在实际环境中,一个Zookeeper集群要为上万台机器提供服务,维持长连接和心跳还是要消耗一定的资源的。因为Observer是不参与投票的所以加Observer并不会降低整体的吞吐量,而且Observer挂掉不会影响整个集群的健康。
但是这里要注意的是,分Observer Group只能解决部分问题,因为毕竟所有的写入还是要交给核心Group来处理的,所以对于写入量特别大的应用来说,还是需要进行集群上的隔离,比如Storm和Kafka就对Zookeeper压力比较大,你就不能将其与服务发现的集群放在一起。
4)内存
因为Zookeeper将所有数据都放在内存里,所以对JVM以及机器的内存也要预先计划,如果出现Swap那将严重的影响Zookeeper集群的性能,所以我一般不怎么推荐将Zookeeper用作通用的配置管理服务。因为一般配置数据还是挺大的,这些全部放在内存里不太可控。
5)日志清理
因为Zookeeper要频繁的写txlog (Zookeeper写的一种顺序日志) 以及定期dump内存snapshot到磁盘,这样磁盘占用就越来越大,所以Zookeeper提供了清理这些文件的机制,但是这种机制并不太合理,它只能设置间隔多久清理,而不能设置具体的时间段。那么就有可能碰到高峰期间清理,所以建议将其关闭:autopurge.purgeInterval=0。然后使用crontab等机制,在业务低谷的时候清理。
6)日志,jvm配置
从官网直接下载的包如果直接启动运行是很糟糕的,这个包默认的配置日志是不会轮转的,而且是直接输出到终端。我们最开始并不了解这点,然后运行一段时间后发现生成一个庞大的zookeeper.out的日志文件。除此之外,这个默认配置还没有设置任何jvm相关的参数(所以堆大小是个默认值),这也是不可取的。那么有的同学说那我去修改Zookeeper的启动脚本吧。最好不要这样做,Zookeeper会加载conf文件夹下一个名为zookeeper-env.sh的脚本,所以你可以将一些定制化的配置写在这里,而不是直接去修改Zookeeper自带的脚本。
|
1
2
3
|
#!/usr/bin/env bashZOO_LOG_DIR=/var/log/kevintest/zookeeper_22181/ #日志文件放置的路径ZOO_LOG4J_PROP="INFO,ROLLINGFILE" #设置日志轮转 |
新版本的zk中是用java.env这个参数文件来配置的
|
1
2
3
4
|
if [ -f "$ZOOCFGDIR/java.env" ]then . "$ZOOCFGDIR/java.env"fi |
其中$ZOOCFGDIR/java.env就是设置jvm内存大小的文件,这个文件默认情况下是没有的,需要手动创建,
vim /usr/local/services/zookeeper-3.4.8/conf/java.env
|
1
2
3
4
|
#!/bin/shexport JAVA_HOME=/usr/java/jdk# heap size MUST be modified according to cluster environmentexport JVMFLAGS="-Xms4096m -Xmx4096m $JVMFLAGS" |
7)地址
在实际环境中,我们可能因为各种原因比如机器过保,硬件故障等需要迁移Zookeeper集群,所以Zookeeper的地址是一个很头痛的事情。这个地址有两方面,第一个是提供给Client的地址,建议这个地址通过配置的方式下发,不要让使用方直接使用,这一点我们前期做的不好。另外一个是集群配置里,集群之间需要通讯,也需要地址。我们的处理方式是设置hosts:
|
1
2
3
|
192.168.1.20 zk1192.168.1.21 zk2192.168.1.22 zk3 |
在zoo.cfg配置里:
|
1
2
3
|
server.1=zk1:2081:3801server.2=zk2:2801:3801server.3=zk3:2801:3801 |
这样在需要迁移的时候,我们停老的节点,起新的节点只需要修改hosts映射就可以了。比如现在server.3需要迁移,那我们在hosts里将zk3映射到新的ip地址。但是对于java有一个问题是,java默认会永久缓存DNS cache,即使你将zk3映射到别的ip,如果并不重启server.1, server.2,它是不会解析到新的ip的,这个需要修改$JAVA_HOME/jre/lib/security/java.security文件里的networkaddress.cache.ttl=60,将其修改为一个比较小的数。对于这个迁移的问题,我们还遇到一个比较尴尬的情况,在最后的坑里会有提及。
8)日志位置
Zookeeper主要产生三种IO:
txlog(每个写操作,包括新Session都会记录一条log),Snapshot以及运行的应用日志。一般建议将这三个IO分散到三个不同的盘上。不过我们倒是一直没有这么实验过,我们的Zookeeper也是运行在虚拟机(一般认为虚拟机IO较差)上。
9)监控
我们对Zookeeper做了这样一些监控:
a)是否可写。 就是一个定时任务定时的去创建节点,删节点等操作。这里要注意的是Zookeeper是一个集群,我们监控的时候我还是希望对单个节点做监控,所以这些操作的时候不要连接整个集群,而是直接去连接单个节点。
b)监控watcher数和连接数 特别是这两个数据有较大波动的时候,可以发现使用方是否有误用的情况
c)网络流量以及client ip 这个会记录到监控系统里,这样很快能发现『害群之马』
10)一些使用建议
a)不要强依赖Zookeeper,也就是Zookeeper出现问题业务已然可以正常运行。Zookeeper是一个分布式的协调框架,主要做的事情就是分布式环境的一致性。这是一个非常苛刻的事情,所以它的稳定性受很多方面的影响。比如我们常常使用Zookeeper做服务发现,那么服务发现其实是不需要严格的一致性的,我们可以缓存server
list,当Zookeeper出现问题的时候已然可以正常工作,在这方面etcd要做的更好一些,Zookeeper如果出现分区,少数派是不能提供任何服务的,读都不可以,而etcd的少数派仍然可以提供读服务,这在服务发现的时候还是不错的。
b)不要将很多东西塞到Zookeeper里,这个上面已经提到过。
c)不要使用Zookeeper做细粒度锁,比如很多业务在订单这个粒度上使用Zookeeper做分布式锁,这会频繁的和Zookeeper交互,对Zookeeper压力较大,而且一旦出现问题影响面广。但是可以使用粗粒度的锁(其实leader选举也是一种锁)。
d)不建议做通用配置的第二个理由是,通用配置要提供给特别多特别多系统使用,而且一些公共配置甚至所有系统都会使用,一旦这样的配置发生变更,Zookeeper会广播给所有的watcher,然后所有Client都来拉取,瞬间造成非常大的网络流量,引起所谓的『惊群』。而自己实现通用配置系统的时候,一般会对这种配置采取排队或分批通知的方式。
三、Zookeeper操作命令手册
1)Zookeeper客户端命令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
zkCli.sh -server 127.0.0.1:2181[zk: localhost:2182(CONNECTED) 0] helpZooKeeper -server host:port cmd argsconnect host:portget path [watch]ls path [watch]set path data [version]rmr pathdelquota [-n|-b] pathquitprintwatches on|offcreate [-s] [-e] path data aclstat path [watch]closels2 path [watch]historylistquota pathsetAcl path aclgetAcl pathsync pathredo cmdnoaddauth scheme authdelete path [version]setquota -n|-b val path |
登录后命令行里面的一些简单操作如下:
- 显示根目录下、文件: ls / #使用 ls 命令来查看当前 ZooKeeper 中所包含的内容
- 显示根目录下、文件: ls2 / #查看当前节点数据并能看到更新次数等数据
- 创建文件,并设置初始内容: create /zk "test" #创建一个新的 znode节点“ zk ”以及与它关联的字符串
- 获取文件内容: get /zk #确认 znode 是否包含我们所创建的字符串
- 修改文件内容: set /zk "zkbak" #对 zk 所关联的字符串进行设置
- 删除文件: delete /zk #将刚才创建的 znode 删除
- 退出客户端: quit
- 帮助命令: help
2)Zookeeper服务端命令
在准备好相应的配置之后,可以直接通过zkServer.sh 这个脚本进行服务的相关操作
- 启动ZK服务: sh bin/zkServer.sh start
- 查看ZK服务状态: sh bin/zkServer.sh status
- 停止ZK服务: sh bin/zkServer.sh stop
- 重启ZK服务: sh bin/zkServer.sh restart
3)Zookeeper常用四字命令
ZooKeeper 支持某些特定的四字命令字母与其的交互。它们大多是查询命令,用来获取 ZooKeeper 服务的当前状态及相关信息。用户在客户端可以通过telnet 或 nc 向 ZooKeeper 提交相应的命令。命令语义:

命令操作实例:(机器上要安装netcat-0.7.1-1.i386.rpm服务)
|
1
2
3
4
5
6
7
8
9
10
11
|
# echo stat |nc 127.0.0.1 2182 来查看哪个节点被选择作为follower或者leader# echo ruok |nc 127.0.0.1 2182 测试是否启动了该Server,若回复imok表示已经启动。# echo dump | nc 127.0.0.1 2182 列出未经处理的会话和临时节点。# echo kill | nc 127.0.0.1 2182 关掉server# echo conf | nc 127.0.0.1 2182 输出相关服务配置的详细信息。# echo cons | nc 127.0.0.1 2183 列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息。# echo envi | nc 127.0.0.1 2182 输出关于服务环境的详细信息(区别于 conf 命令)。# echo reqs | nc 127.0.0.1 2183 列出未经处理的请求。# echo wchs | nc 127.0.0.1 2183 列出服务器 watch 的详细信息。# echo wchc | nc 127.0.0.1 2183 通过 session 列出服务器 watch 的详细信息,它的输出是一个与 watch 相关的会话的列表。# echo wchp | nc 127.0.0.1 2183 通过路径列出服务器 watch 的详细信息。它输出一个与 session 相关的路径。 |
四、Zookeeper运维手册
对于长期运行的ZooKeeper ensemble来说, 运维工作是必须做的, 运维人员需要注意以下几点:
1)清理磁盘文件
ZooKeeper中有两处使用到了磁盘:事务日志与内存数据库快照.。ZooKeeper名称空间里的节点发生变更的时候,
就会有内容写入事务日志. 通常情况下, 当单个事务日志文件变的越来越大的时候, 事务日志就需要创建一个新的文件.
但在创建新的事务日志文件之前, ZooKeeper会先把当前的内存数据库的状态写入磁盘先做快照, 然后再生成一个新的事务日志文件.
这样就保证了快照文件和事务日志文件是一一对应的. 但快照落地需要时间, 在快照落地期间如果还有事务来临,
那么这部分事务的日志依然会写向旧的事务日志文件里. 这就导致, 快照文件对应的那个事务日志文件里, 存储的事务日志可能要比当前快照文件要新.
ZooKeeper server进程在默认启动的情况下, 是不会自动删除事务日志文件和快照文件的,当然这是可配置的, 配置项分别是 autopurge.snapRetainCount 和 autopurge.purgeInterval. 这两个配置项的具体含义在有详细描述. 但需要注意:如果你要这样做, 那么最好为每台部署的机器提供不同的配置值, 除非这些机器的规格是完全一摸一样的!
除过在配置文件中设定, 还有一种方法就是调用一个ZooKeeper提供的小工具, 大致如下:
|
1
|
java -cp zookeeper.jar:lib/log4j-1.2.15.jar:conf org.apache.zookeeper.server.PurgeTxnLog <dataDir> <snapDir> -n <count> |
其中<dataDir>是事务日志的保存目录,<snapDir>是快照文件的保存目录,<count>是要保留的个数. 建议大于3.。运行该命令后, 除了最近的<count>对事务日志文件与快照文件, 其它文件都将被删除. 这是一个一次性命令. 如果你想定期清理, 那么只能自己写个脚本咯。
注意以下几点:
- 永远不建议手动删除事务日志文件与快照文件;
- 通过配置项使ZooKeeper server自动删除, 只有在ZooKeeper版本大于3.4后才可用;
- PrugeTxnLog工具是一个一次性工具, 如果需要定期清理, 你需要自己写一个脚本;
- 当机器规格不同的时候, 建议按照不同规格定制不同的清楚阈值;
2)清理运行日志
ZooKeeper 用 log4j 来输出运行日志。如果要更改运行日志的相关配置,你需要独立为log4j提供配置文件。建议使用log4j提供的滚动日志特性,这样就免去了清理运行日志的问题。
3)监控ZooKeeper server进程的死活
ZooKeeper的server进程在错误发生的时候会立即自杀,ZooKeeper的设计哲学是这样的:
- 单个实例挂掉, 或少量实例挂掉不影响整体服务
- 当单个实例遇到错误的时候, 实例会立即挂掉
- 实例被重启后会自动加入ensemble
- 但实例不会自动重启
所以搞一个监控进程, 在实例进程挂掉之后将其立即拉起是一个很好的做法. 比如daemontools或SMF.
4)监控ZooKeeper server服务的状态
要监控ZooKeeper服务的状态, 有两个选择
- 用4字命令去检查。这个在上面的 ZooKeeper4字命令中有详情
- JMX。
5)运行日志
ZooKeeper使用log4j 1.2来输出运行日志,默认的配置文件在zookeeper/conf/log4j.properties中。log4j的配置文件要求要么放在工作目录里, 要么放在类路径里。
6)问题定位
[ 由于文件损坏导致实例不能启动 ]
ZooKeeper的server进程在事务日志文件被损坏的情况下是起不来的。这时运行日志会说在载入ZooKeeper database时出现IOException。这种情况下,你需要做的是:
- 通过四字命令stat检查ensemble中的其它实例是否正常工作
- 如果其它实例正常, 那么把当前实例dataDir目录下的version-2子目录中的所有文件删除, 再把dataLogDir下的version-2子目录下的所有文件删除, 然后重启就可以了。
这种情况是当前实例的事务文件损坏, 不能重建内存数据库, 删除掉事务日志和数据库快照后, 当前的实例在重启后会通过其它实例拉取内在数据库, 重建事务日志和快照文件.
7)配置参数
ZooKeeper的行为受配置文件影响.
所有同一个ensemble中的实例建议使用完全相同的配置文件. 但使用完全相同的配置文件有一个前提条件:
就是所有实例所属的机器上的磁盘布局是相同的.
磁盘布局不同意味着不同的机器下的实例在配置dataDir和dataLogDir的时候配置值可能有差异, 但除此之外,
一个ensemble中的所有实例的配置文件必须保证server.x=xxxx这些配置值是完全一致的。
7.1)最小配置
下面列出来的是要让ensemble正常工作, 每个实例都需要配置的配置项。配置项含义:

7.2)高级可选配置
下面列出来的是一此可选配置, 属于高级选项. 你可以用这些配置项进一步个性化ZooKeeper server的行为. 其中一些配置项的值可以通过在启动server进程的时候写入Java 系统属性来设置。配置项对应的Java系统属性名含义:

7.3)多实例模式下的配置项
下面列出来的配置项是多实例模式下的一些配置项. 有一些配置项可以通过在启动server进程的时候写入Java系统属性来设置。配置项对应的Java系统属性名含义

7.4)身份认证与授权相关的配置项
为了避免看不懂下面的配置项都在干嘛,先大致说一下Zookeeper里的认证与授权。在ZooKeeper
server端, 每个znode存储两部分内容: 数据和状态. 状态中包含ACL信息. 创建一个znode会产生一个ACL表,
每个ACL记录有以下内容:
- 验证模式(scheme)
- 具体内容(id). 比如当scheme=="digest"的时候, id为是用户名和密码, 比如"root:J0sTy9BCUKubtK1y8pkbL7qoxSw="
- 这个ACL拥有的权限
ZooKeeper提供了如下几种验证模式(scheme)
- digest 就是用户名+密码.
- auth 不使用任何id, 表示任何已确认用户
- ip. 用client连接至server时使用的IP地址进行验证
- world 固定ID为"anyone", 为所有client端开放权限
- super 在这种scheme下, 对应的id拥有超级权限.
需要注意:exists操作的getAcl操作不受ACL控制, 任何client都可以执行这两个操作.
znode的权限主要有以下几种:
- create
- read
- write
- delete
- admin 允许对本节点执行setAcl操作
配置项对应的Java系统属性名含义:

7.5)实验性的配置项
配置项对应的Java系统属性名含义

7.6)不安全的配置项
配置项对应的Java系统属性名含义

7.7)使用Netty框架进行通信
这是3.4版本后的一个特性。Netty是一个基于NIO的客户端-服务器通信框架, 这个框架简化了Java在网络通信层上的很多繁操作, 并且内置支持SSL和认证授权, 当然SSL和认证授权是额外的可选功能.
3.4版本之前,ZooKeeper是直接用NIO的,在3.4之后,NIO只是一个可选项,但依然是默认选项,如果要使用Netty的话,需要把zookeeper.serverCnxnFactory替换为org.apache.zookeeper.server.NettyServerCnxnFactory。可以只在client上用Netty,也可在server上用Netty,但通常情况下,建议要改一起改。蛋疼的是相关的文档官方还没有写!
7.8)四字命令
ZooKeeper支持一系列的四字命令, 你可以在client上通过telnte或nc直接向server发送这些四字命令.使用一个四字命令如下所示, 下面使用echo和nc将四字命令ruok发送给本机的server:
|
1
|
echo ruok | nc 127.0.0.1 2182 |
下表是所有支持的四字命令, 注意有些命令仅在特定版本之后才受支持。命令含义:

这里需要注意:
mntr命令的输出大致长下面这样.
输出格式符合java属性格式, 如果你要写个脚本定时发送这个命令以监控ensemble的运行状态, 注意输出的字段的数量可能会有变化,
写脚本的时候注意这一点。另外有一些字段是与操作系统平台相关的, 输出每一行的格式是key \t value, 下面是一个示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# echo mntr | nc localhost 2185zk_version 3.4.0zk_avg_latency 0zk_max_latency 0zk_min_latency 0zk_packets_received 70zk_packets_sent 69zk_outstanding_requests 0zk_server_state leaderzk_znode_count 4zk_watch_count 0zk_ephemerals_count 0zk_approximate_data_size 27zk_followers 4 - only exposed by the Leaderzk_synced_followers 4 - only exposed by the Leaderzk_pending_syncs 0 - only exposed by the Leaderzk_open_file_descriptor_count 23 - only available on Unix platformszk_max_file_descriptor_count 1024 - only available on Unix platforms |
8)数据文件管理
将事务日志文件和快照文件存储在不同的物理磁盘上, 可以提升系统性能.
8.1)快照存储目录
配置项dataDir指向的目录路径中主要存储两种文件:
- myid: 这个文件里写着当前server实例的编号
- snapshot.<zxid>: 这里存储着内存数据库的快照
server实例的编号用在两个场合:myid文件里, 以及配置文件里的server.X配置项中。当前server实例在启动的时候, 先去配置文件里看dataDir的值, 然后去找dataDir/myid这个文件, 查看文件内容, 得知自己的编号, 然后在配置文件里再找对应的server.x查看要开的端口号。
快照文件的后缀, <zxid>, 是一个事务ID. 这是在落地内存数据库这个过程开始时, 成功执行的最后一个事务的ID号, 但蛋疼的是, 在落地快照的过程中, server还在接受请求, 执行事务, 也就是在落地的过程中, 内存数据库中的数据还处于一个变动的过程中, 这就导致落地后的快照文件像是一个扭曲的文件. 像是你在用手机拍摄全景照片的过程中, 有一只猫随着你的镜头走, 然后最终拍摄出来的照片里有一只长度为17米的猫. 最终落地生成的快照文件里的数据状态可能和任何一个时刻内存数据库的状态都对不上, 就是因为这个原因. 但ZooKeeper依然可以用这种扭曲的快照文件重建内存数据库, 这是因为ZooKeeper中的update操作是幂等的, 这就保证了在扭曲的快照文件之上重放事务日志里的日志, 就可以将进程的内存状态恢复到日志结束时的那个时刻。
8.2)事务日志目录
在有update请求的时候,
server的默认行为是先写事务日志, 再执行update操作. 单个事务日志里存储的事务个数超过一个阈值的时候,
就会导致事务日志新开一个文件, 同时会导致内在数据库落地快照, 这个阈值在上面的配置项中有提. 日志文件的后缀是日志文件里第一个日志的ID
8.3)文件管理
快照文件的格式和事务日志文件的格式是死的,这就允许你从现网的server机器上将事务日志和内存快照拷贝至你的开发机,在你的开发环境重现现网的情景, 从而进行一些调试或问题定位操作。
使用旧的事务日志文件和快照文件还能重建过去某个指定时刻server的状态, LogFormatter类可以用来访问事务日志文件, 以获取可读的信息. 当然使用的时候需要有管理员权限, 因为数据是加密的。
server进程本来是没有删除事务日志和快照文件的能力的, 但这在3.4版本中也随着新的配置项autopurge.snapRetainCount和autopurge.purgeInterval添加上了。
9)要避免的事情
下面是几个你应当在部署运维的时候极力避免的事情:
- ensemble中各个server使用的配置文件中,server.X配置表不一致. 所有的配置文件中, 都要以server.X配置项的形式列出当前ensemble中的所有server, 包括自己. 如果这个东西不一致, 会炸。
- 事务日志目录设置不合理。将事务日志目录指向一个IO繁忙的磁盘, 会导致server始终处于一个半死不活的状态;
- 不正确的java heap size。频繁的swap操作会严重拖慢性能. 保守起见, 如果你的机器有4G内存, 把java heap size设置为3G就好了;
- 部署的时候不考虑安全性。建议在生产环境中合理配置防火墙;
五、Zookeeper常见问题汇总
1)zookeeper client 3.4.5 ping时间间隔算法有问题,在遇到网络抖动等原因导致一次ping失败后会断开连接。3.4.6解决了这个问题 Bug1751。
2)zookeeper client如果因为网络抖动断开了连接,如果后来又重连上了,zookeeper client会自动的将之前订阅的watcher等又全部订阅一遍,而Zookeeper默认对单个数据包的大小有个1M的限制,这往往就会超限,最后导致一直不断地的重试。这个问题在较新的版本得到了修复。Bug706
3)抛出UnresolvedAddressException异常导致Zookeeper选举线程退出,整个集群无法再选举,处于崩溃的边缘。这个问题是,某次OPS迁移机器,将老的机器回收了,所以老的机器的IP和机器名不复存在,最后抛出UnresolvedAddressException这个异常,而Zookeeper的选举线程(QuorumCnxManager类里的Listener)只捕获了IOException,导致该线程退出,该线程一旦退出只要现在的leader出现问题,需要重新选举,则不会选出新的leader来,整个集群就会崩溃。Bug2319
4)由于文件损坏导致实例不能启动
ZooKeeper的server进程在事务日志文件被损坏的情况下是起不来的. 这时运行日志会说在载入ZooKeeper database时出现IOException. 这种情况下, 你需要做的是:
- 通过四字命令stat检查ensemble中的其它实例是否正常工作
- 如果其它实例正常, 那么把当前实例dataDir目录下的version-2子目录中的所有文件删除, 再把dataLogDir下的version-2子目录下的所有文件删除, 然后重启就可以了.
这种情况是当前实例的事务文件损坏, 不能重建内存数据库, 删除掉事务日志和数据库快照后, 当前的实例在重启后会通过其它实例拉取内在数据库, 重建事务日志和快照文件.
六、Zookeeper中的Znode特性说明
在ZooKeeper中,节点也称为znode。由于对于程序员来说,对zookeeper的操作主要是对znode的操作,因此,有必要对znode进行深入的了解。 ZooKeeper采用了类似文件系统的的数据模型,其节点构成了一个具有层级关系的树状结构。Zookeeper拥有一个命名空间就像一个精简的文件系统,不同的是它的命名空间中的每个节点拥有它自己或者它下面子节点相关联的数据。Zookeeper中必须使用绝对路径也就是使用“/”开头。例如,下图展示了zookeeper节点的层级树状结构。
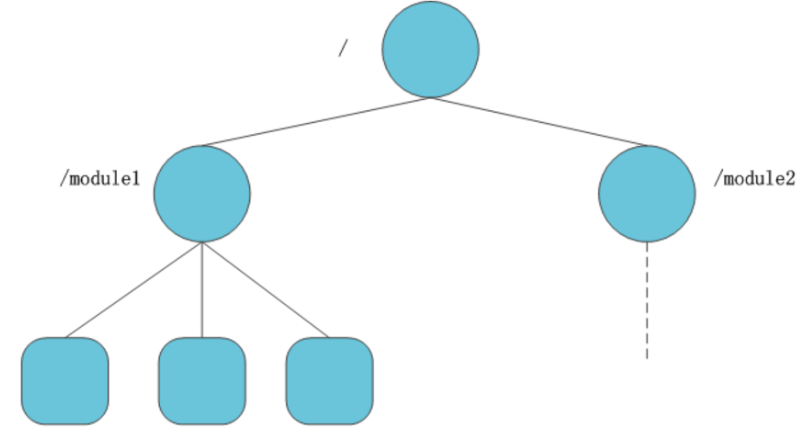
图中,根节点 / 包含了两个字节点 /module1,/module2,而节点 /module1 又包含了三个字节点 /module1/app1,/module1/app2,/module1/app3。在zookeeper中,节点以绝对路径表示,不存在相对路径,且路径最后不能以 / 结尾(根节点除外)。
ZooKeeper以一种类似于文件系统的树形数据结构实现名称空间。名称空间中的每个节点都是一个znode。znode和文件系统的路径不一样,在文件系统中,路径只是一个名称,不包含数据。而znode不仅是一个路径,还携带数据。
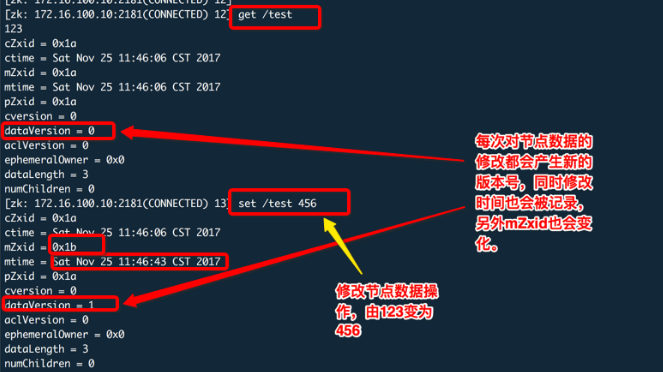
此外,znode还维护了包括版本号和时间戳的状态信息。通过版本号和时间戳信息,可以让ZooKeeper验证缓存、协调每次的更改操作。每当znode数据发生更改时,版本号都会递增。客户端检索znode时,同时也会收到关于该节点的状态信息。当客户端执行更改、删除操作时,它必须提供它正在更改的znode数据的版本,如果它提供的版本与数据的实际版本不匹配,则更新将失败。
Zookeeper目录树中每个节点对应一个Znode。每个Znode维护这一个属性,当前版本、数据版本、建立时间和修改时间等,看下图:

Zookeeper就是使用这些属性来实现特殊功能的。当一个客户端要对某个节点进行修改时,必须提供该数据的版本号,当节点数据发生变化是其版本号就会增加。如下图:
0)Znode节点特性
-> Watches:客户端可以在节点上设置Watches(可以叫做监视器)。当节点状态发生变化时,就会触发监视器对应的操作,当监视器被触发时,zookeeper服务器会向客户端发送且只发送一个通知
-> 数据访问:zookeeper上存储的数据需要被原子性的操作(要么修改成功要么回到原样),也是就读操作将会读取节点相关所有数据,写操作也会修改节点相关所有数据,,而且每个节点都有自己的ACL。
节点类型:zookeeper中有几种节点类型,节点类型在节点创建的时候就被确定且不可改变
-> 临时节点(EPHEMERAL):临时创建的,会话结束节点自动被删除,也可以手动删除,临时节点不能拥有子节点
-> 临时顺序节点(EPHEMERAL_SEQUENTIAL):具有临时节点特征,但是它会有序列号,分布式锁中会用到该类型节点
-> 持久节点(PERSISTENT):创建后永久存在,除非主动删除。
-> 持久顺序节点(PERSISTENT_SEQUENTIAL):该节点创建后持久存在,相对于持久节点它会在节点名称后面自动增加一个10位数字的序列号,这个计数对于此节点的父节点是唯一,如果这个序列号大于2^32-1就会溢出。
1)znode节点类型
根据节点的存活时间,可以对节点划分为持久节点和临时节点。节点的类型在创建时就被确定下来,并且不能改变。
- 持久节点的存活时间不依赖于客户端会话,只有客户端在显式执行删除节点操作时,节点才消失。
- 临时节点的存活时间依赖于客户端会话,当会话结束,临时节点将会被自动删除(当然也可以手动删除临时节点)。利用临时节点的这一特性,我们可以使用临时节点来进行集群管理,包括发现服务的上下线等。 ZooKeeper规定,临时节点不能拥有子节点。
持久节点
使用命令create可以创建一个持久节点
|
1
|
create /module1 module1 |
这样,便创建了一个持久节点/module1,且其数据为"module1"。
临时节点
使用create命令,并加上-e参数,可以创建一个临时节点
|
1
|
create -e /module1/app1 app1 |
这样,便创建了一个临时节点 /module1/app1,数据为"app1"。关闭会话,然后输入命令
|
1
|
get /module1/app1 |
可以看到有以下提示,说明临时节点已经被删除
|
1
|
Node does not exist: /module1/app1 |
顺序节点
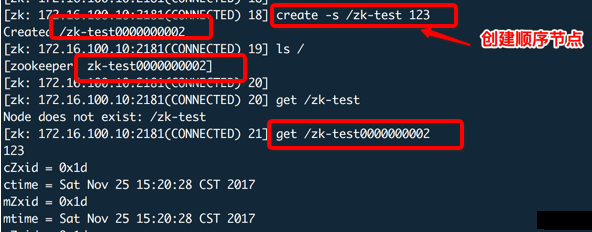
ZooKeeper中还提供了一种顺序节点的节点类型。每次创建顺序节点时,zk都会在路径后面自动添加上10位的数字(计数器),例如
< path >0000000001,< path
>0000000002,……这个计数器可以保证在同一个父节点下是唯一的。在zk内部使用了4个字节的有符号整形来表示这个计数器,也就是说当计数器的大小超过2147483647时,将会发生溢出。
顺序节点为节点的一种特性,也就是,持久节点和临时节点都可以设置为顺序节点。这样一来,znode一共有4种类型:持久的、临时的,持久顺序的,临时顺序的。
使用命令create加上-s参数,可以创建顺序节点(-e参数为创建临时节点,如果不带参数则创建持久节点)。例如
|
1
|
create -s /module1/app app |
输出
|
1
|
Created /module1/app0000000001 |
便创建了一个持久顺序节点 /module1/app0000000001。如果再执行此命令,则会生成节点 /module1/app0000000002。
如果在create -s再添加-e参数,则可以创建一个临时顺序节点。如下示例:
2)znode节点数据
在创建节点时可以指定节点中存储的数据。ZooKeeper保证读和写都是原子操作,且每次读写操作都是对数据的完整读取或完整写入,并不提供对数据进行部分读取或者写入操作。
以下命令创建一个节点/module1/app2,且其存储的数据为app2。
|
1
|
create /module1/app2 app2 |
ZooKeeper虽然提供了在节点存储数据的功能,但它并不将自己定位为一个通用的数据库,也就是说,你不应该在节点存储过多的数据。Zk规定节点的数据大小不能超过1M,但实际上我们在znode的数据量应该尽可能小,因为数据过大会导致zk的性能明显下降。如果确实需要存储大量的数据,一般解决方法是在另外的分布式数据库(例如redis)中保存这部分数据,然后在znode中我们只保留这个数据库中保存位置的索引即可。
3)znode节点属性
每个znode都包含了一系列的属性,通过命令get就可以获得节点的属性。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
get /module1/app2app2 cZxid = 0x20000000e ctime = Thu Jun 30 20:41:55 HKT 2016 mZxid = 0x20000000e mtime = Thu Jun 30 20:41:55 HKT 2016 pZxid = 0x20000000e cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 4 numChildren = 0 |
4)zookeeper中的版本号
version含义:对节点的每次操作都会使节点的版本号增加,有三个版本号dataversion(数据版本号)、cversion(子节点版本号)、aclversion(节点所拥有的ACL版本号)。
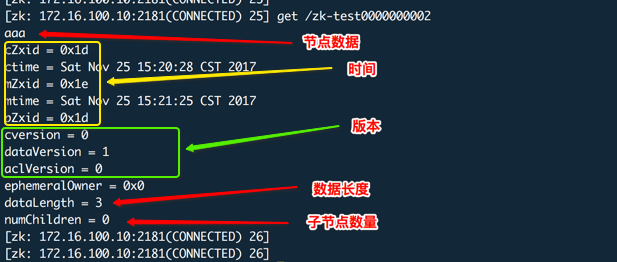
对于每个znode来说,均存在三个版本号:
- dataVersion
数据版本号,每次对节点进行set操作,dataVersion的值都会增加1(即使设置的是相同的数据)。
- cversion
子节点的版本号。当znode的子节点有变化时,cversion 的值就会增加1。
- aclVersion
ACL的版本号,关于znode的ACL(Access Control List,访问控制),可以参考 参考资料1 有关ACL的描述。
以数据版本号来说明zk中版本号的作用。每一个znode都有一个数据版本号,它随着每次数据变化而自增。ZooKeeper提供的一些API例如setData和delete根据版本号有条件地执行。多个客户端对同一个znode进行操作时,版本号的使用就会显得尤为重要。例如,假设客户端C1对znode
/config写入一些配置信息,如果另一个客户端C2同时更新了这个znode,此时C1的版本号已经过期,C1调用setData一定不会成功。这正是版本机制有效避免了数据更新时出现的先后顺序问题。在这个例子中,C1在写入数据时使用的版本号无法匹配,使得操作失败。下图描述了这个情况。下面表示使用版本号来阻止并行操作的不一致性:
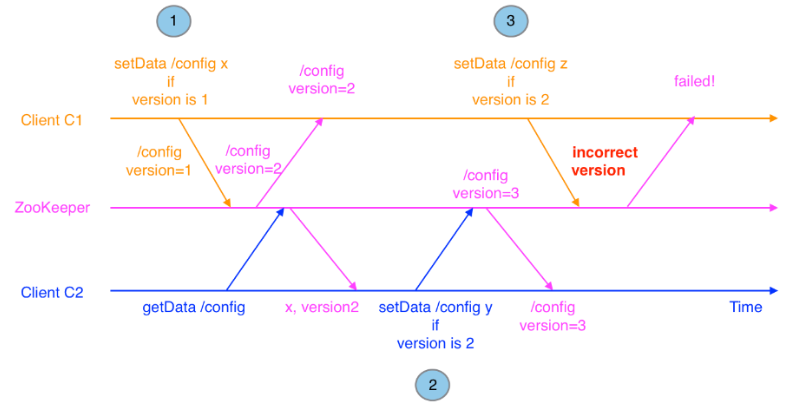
zookeeper中版本号的作用
Zookeeper里面的版本号和我们理解的版本号不同,它表示的是对数据节点的内容、子节点列表或者ACL信息的修改次数。节点创建时dataversion、aclversion,cversion都为0,每次修改响应内容其对应的版本号加1。
这个版本号的用途就和分布式场景的一个锁概念有关。比如演出售票中的一个座位,显然每个场次中的每个座位都只有一个,不可能卖出2次。如果A下单的时候显示可售,他想买,那么为了保证他可以下单成功,此时别人就不能买。这时候就需要有一种机制来保证同一时刻只能有一个人去修改该座位的库存。这就用到了锁,锁有悲观锁和乐观锁。
- 悲观锁:它会假定所有不同事务的处理一定会出现干扰,数据库中最严格的并发控制策略,如果一个事务A正在对数据处理,那么在整个事务过程中,其他事务都无法对这个数据进行更新操作,直到A事务释放了这个锁。
- 乐观锁:它假定所有不同事务的处理不一定会出现干扰,所以在大部分操作里不许加锁,但是既然是并发就有出现干扰的可能,如何解决冲突就是一个问题。在乐观锁中当你在提交更新请求之前,你要先去检查你读取这个数据之后该数据是否发生了变化,如果有那么你此次的提交就要放弃,如果没有就可以提交。
Zookeeper中的版本号就是乐观锁,你修改节点数据之前会读取这个数据并记录该数据版本号,当你需要更新时会携带这个版本号去提交,如果你此时携带的版本号(就是你上次读取出来的)和当前节点的版本号相同则说明该数据没有被修改过,那么你的提交就会成功,如果提交失败说明该数据在你读取之后和提交之前这段时间内被修改了。
这里通过set命令并携带版本号提交更新,版本号相同更新就会成功。
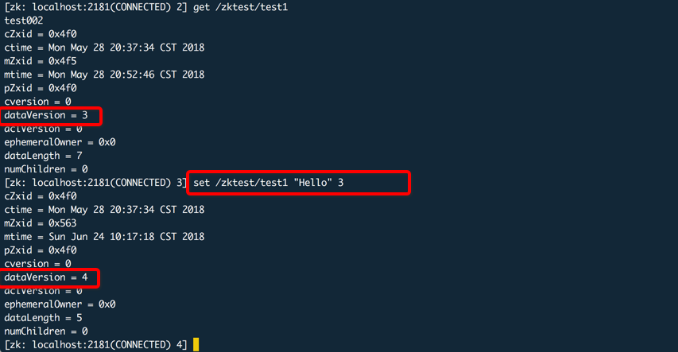
如果你再次更新并使用之前的版本号那么就会失败。

5)zookeeper中的事务ID
对于zookeeper来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction Id)。通过zxid,可以确定更新操作的先后顺序。例如,如果zxid1小于zxid2,说明zxid1操作先于zxid2发生。需要指出的是,zxid对于整个zookeeper都是唯一的,即使操作的是不同的znode。
- cZxid 即Znode创建的事务id。
- mZxid 即Znode被修改的事务id,即每次对znode的修改都会更新mZxid。
下面表示Zxid在客户端重连中的作用:
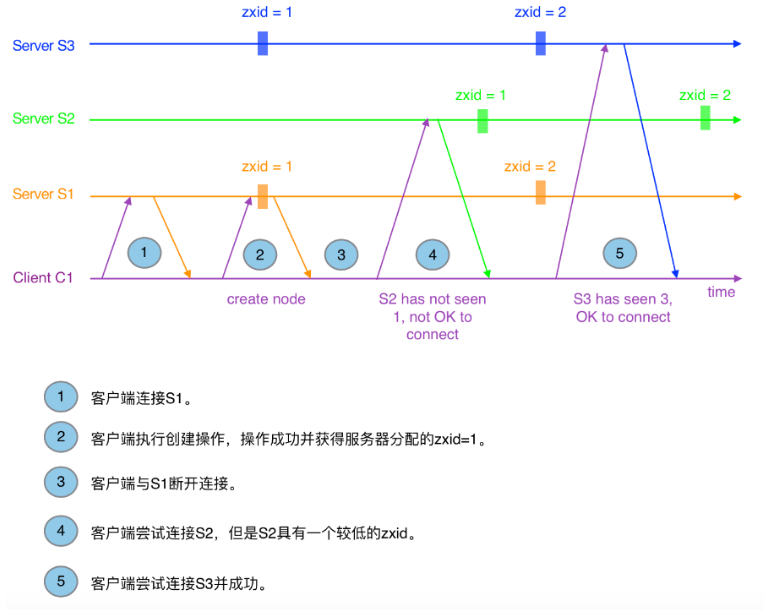
在集群模式下,客户端有多个服务器可以连接,当尝试连接到一个不同的服务器时,这个服务器的状态要与最后连接的服务器的状态要保持一致。Zk正是使用zxid来标识这个状态,图3描述了客户端在重连情况下zxid的作用。当客户端因超时与S1断开连接后,客户端开始尝试连接S2,但S2延迟于客户端所识别的状态。然而,S3的状态与客户端所识别的状态一致,所以客户端可以安全连接上S3。
ZXID含义:ZooKeeper节点状态改变会导致该节点收到一个zxid格式的时间戳,这个时间戳是全局有序的,每次更新都会产生一个新的。如果zxid1的值小于zxid2,那么说明zxid2发生的改变在zxid1之后。zxid是一个唯一的事务ID,具有递增性,一个znode的建立或者更新都会产生一个新的zxid值,具体时间有3个cZxid(节点创建时间)、mZxid(该节点修改时间,与子节点无关)、pZxid(该节点的子节点的最后一次创建或者修改时间,孙子节点无关)
下面对zookeeper的时间和版本号做一说明:

6)zookeeper中的时间戳
包括znode的创建时间和修改时间,创建时间是znode创建时的时间,创建后就不会改变;修改时间在每次更新znode时都会发生变化。以下命令创建了一个 /module2 节点
|
1
2
|
create /module2 module2 Created /module2 |
通过 get 命令,可以看到 /module2的 ctime和mtime均为Sat Jul 02 11:18:32 CST 2018
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
get /module2module2 cZxid = 0x2 ctime = Sat Jul 02 11:18:32 CST 2018 mZxid = 0x2 mtime = Sat Jul 02 11:18:32 CST 2018 pZxid = 0x2 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0 |
修改 /module2,可以看到 ctime 没有发生变化,mtime已更新为最新的时间
|
1
2
3
4
5
6
7
8
9
10
11
12
|
set /module2 module2_1 cZxid = 0x2 ctime = Sat Jul 02 11:18:32 CST 2018 mZxid = 0x3 mtime = Sat Jul 02 11:18:50 CST 2018 pZxid = 0x2 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 9 numChildren = 0 |
7)znode需要关注的点:
- Watches
客户端可在znode上设置watchs。每当该znode发生改变时,就会触发设置在这个znode上的watch。当触发了watch,ZooKeeper会发送一个通知给客户端。
- Data Access
在每个znode名称空间中存储的数据的读、写操作都是原子性的。读操作将获取与znode关联的所有数据(包括数据的状态信息),写操作将替换该znode所携带的所有数据。每个节点都有一个访问控制列表(ACL)来限制谁可以做什么。
ZooKeeper并没有被设计成一般的数据库或大型对象存储。相反,它只是管理协调数据。这些数据可以以配置、状态信息等形式出现。各种形式的协调数据的一个共同特点是它们相对较小,一般以kb作为度量度量。ZooKeeper客户端和服务器实现都有完整的检查功能,以确保znode的数据少于1M,一般来说,协调数据占用的空间都远远小于1M。在相对较大的数据大小上操作会导致一些操作比其他操作花费更多的时间,并且会影响一些操作的延迟,因为它要在网络上传输更多数据。如果需要存储较大数据,可以将它们存储在大型存储系统(如NFS或HDFS)上,然后在ZooKeeper中使用指针指向这些较大数据。
- Ephemeral Nodes
ZooKeeper允许使用临时(ephemeral)节点。只要创建临时znode的会话还存在,临时znode就存在。会话退出,这个会话上创建的临时节点都会删除。因此,临时节点上不允许出现子节点。
- Sequence Nodes -- Unique Naming
创建znode时,还可以请求ZooKeeper将单调递增的计数器追加到znode路径的末尾。这个计数器是父znode独有的。计数器的格式为%010d,即使用0来填充的10位数字(计数器以这种方式进行格式化以简化排序),例如<path>0000000001。注意:用于存储下一个序列号的计数器是由父节点维护的有符号整数(4bytes),当计数器的增量超过2147483647时,计数器将溢出。
8)ZooKeeper中的时间
- Zxid
每次更改ZooKeeper的状态,都会设置到一个zxid(ZooKeeper的事务id)格式的版本戳。zxid暴露了ZooKeeper中所有更改操作的总顺序。因为每次更改都会设置一个全局唯一的zxid值,如果zxid1小于zxid2,说明zxid1对应的操作比zxid2对应的事务先发生。
- Version numbers
每次对某节点进行更改,都会递增这个节点的版本号。有三种版本号:
dataVersion:znode的更改次数。
cversion:子节点的更改次数。
aversion:节点的ACL的更改次数。
- Ticks
当使用多节点(这个节点代表的是组成ZooKeeper的server,而非znode)的ZooKeeper集群时,各节点使用ticks来定义事件的时间。例如传播状态、会话超时时间、节点间连接超时时间等。tick时间间接设置了会话连接的最小超时时长(tick的两倍时长)。如果客户端在2倍tick时间内还没有成功连接server,那么连接失败。
- Real time
除了在创建和修改znode时会将当前实时时间戳放入stat结构之外,ZooKeeper根本不使用实时时间或时钟时间。
9)znode的状态
czxid 创建znode的zxid
mzxid 最近一次修改znode的zxid(创建、删除、set直系子节点、set自身节点都会计数)
pzxid 最近一次修改子节点的zxid(创建、删除直系子节点都会计数,set子节点不会计数)
ctime 创建znode的时间,单位毫秒
mtime 最近一次修改znode的时间,单位毫秒
version 修改znode的次数
cversion 修改子节点的次数(创建、删除直系子节点都会计数,set子节点不会计数)
aversion 该znode的ACL修改次数
ephemeralOwner 临时znode节点的session id,如果不是临时节点,值为0
dataLength znode 携带的数据长度,单位字节
numChildren 直系子节点的数量(不会递归计算孙节点)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号