【Spark2.0源码学习】-9.Job提交与Task的拆分
在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用户任务类(或者任务代码)进行分析
一、整体预览
基于上篇图做了扩展,增加任务执行的相关交互
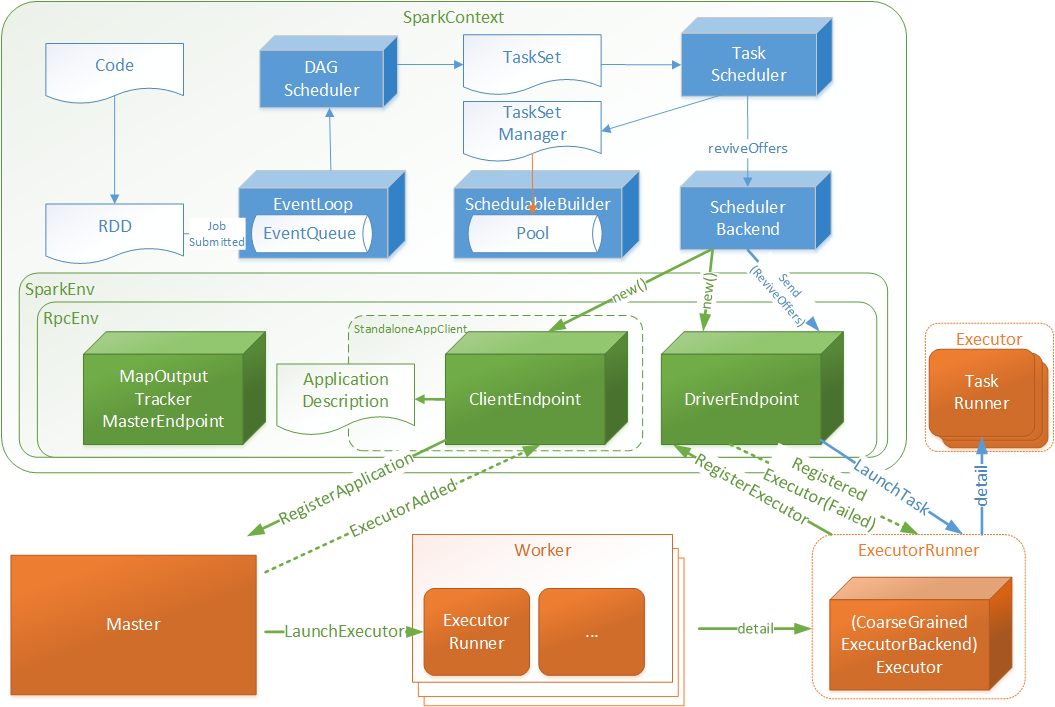
- Code:指的用户编写的代码
- RDD:弹性分布式数据集,用户编码根据SparkContext与RDD的api能够很好的将Code转化为RDD数据结构(下文将做转化细节介绍)
- DAGScheduler:有向无环图调度器,将RDD封装为JobSubmitted对象存入EventLoop(实现类DAGSchedulerEventProcessLoop)队列中
- EventLoop: 定时扫描未处理JobSubmitted对象,将JobSubmitted对象提交给DAGScheduler
- DAGScheduler:针对于JobSubmitted进行处理,最终将RDD转化为执行TaskSet,并将TaskSet提交至TaskScheduler
- TaskScheduler: 根据TaskSet创建TaskSetManager对象存入SchedulableBuilder的数据池(Pool)中,并调用DriverEndpoint唤起消费(ReviveOffers)操作
- DriverEndpoint:接受ReviveOffers指令后将TaskSet中的Tasks根据相关规则均匀分配给Executor
- Executor:启动一个TaskRunner执行一个Task
二、Code转化为初始RDDs
我们的用户代码通过调用Spark的Api(比如:SparkSession.builder.appName("Spark Pi").getOrCreate()),该Api会创建Spark的上下文(SparkContext),当我们调用transform类方法 (如:parallelize(),map())都会创建(或者装饰已有的) Spark数据结构(RDD), 如果是action类操作(如:reduce()),那么将最后封装的RDD作为一次Job提交,存入待调度队列中(DAGSchedulerEventProcessLoop )待后续异步处理。
如果多次调用action类操作,那么封装的多个RDD作为多个Job提交。
流程如下:
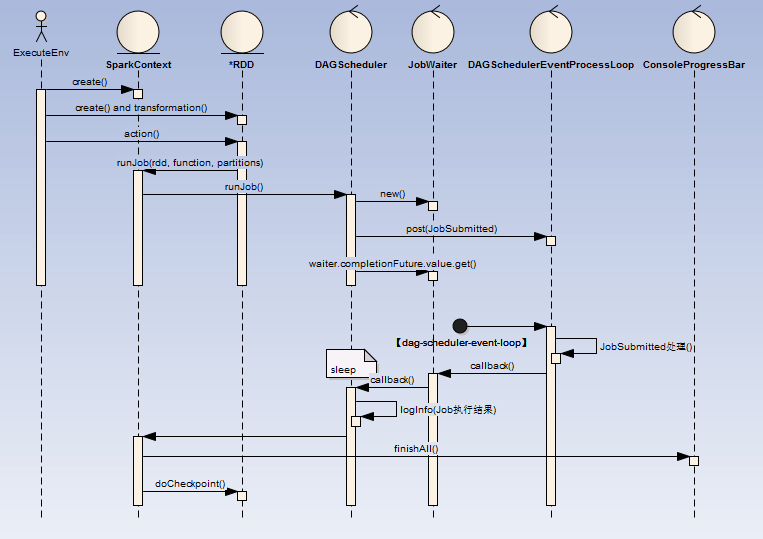
- ExecuteEnv(执行环境 )
-
- 这里可以是通过spark-submit提交的MainClass,也可以是spark-shell脚本
- MainClass : 代码中必定会创建或者获取一个SparkContext
- spark-shell:默认会创建一个SparkContext
- RDD(弹性分布式数据集)
-
- create:可以直接创建(如:sc.parallelize(1 until n, slices) ),也可以在其他地方读取(如:sc.textFile("README.md"))等
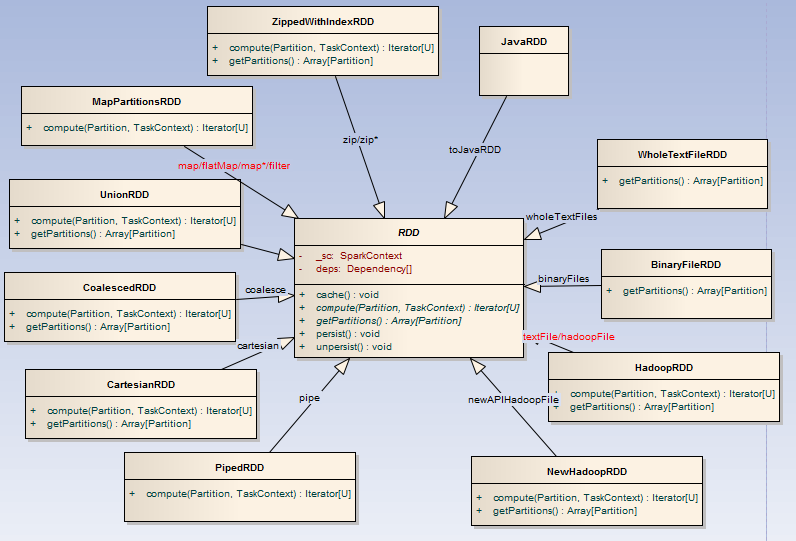
- transformation:rdd提供了一组api可以进行对已有RDD进行反复封装成为新的RDD,这里采用的是装饰者设计模式,下面为部分装饰器类图
![]()
- action:当调用RDD的action类操作方法时(collect、reduce、lookup、save ),这触发DAGScheduler的Job提交
- DAGScheduler:创建一个名为JobSubmitted的消息至DAGSchedulerEventProcessLoop阻塞消息队列(LinkedBlockingDeque)中
- DAGSchedulerEventProcessLoop:启动名为【dag-scheduler-event-loop】的线程实时消费消息队列
- 【dag-scheduler-event-loop】处理完成后回调JobWaiter
- DAGScheduler:打印Job执行结果
- JobSubmitted:相关代码如下(其中jobId为DAGScheduler全局递增Id):
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
- 最终示例:
![]()
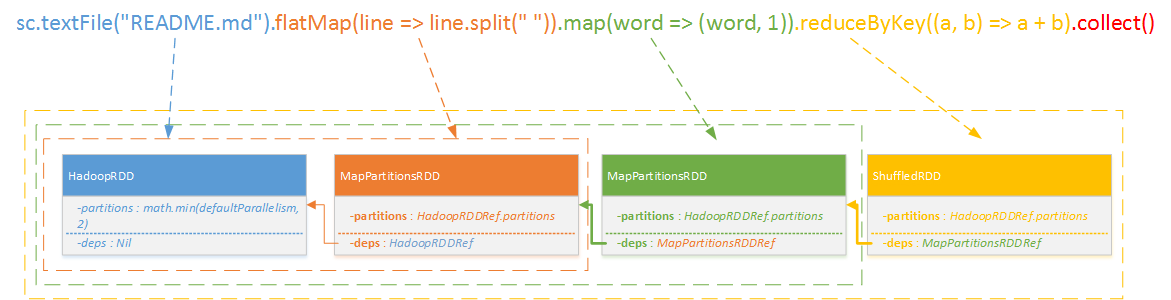
最终转化的RDD分为四层,每层都依赖于上层RDD,将ShffleRDD封装为一个Job存入DAGSchedulerEventProcessLoop待处理,如果我们的代码中存在几段上面示例代码,那么就会创建对应对的几个ShffleRDD分别存入DAGSchedulerEventProcessLoop
三、RDD分解为待执行任务集合(TaskSet)
Job提交后,DAGScheduler根据RDD层次关系解析为对应的Stages,同时维护Job与Stage的关系。
将最上层的Stage根据并发关系(findMissingPartitions )分解为多个Task,将这个多个Task封装为TaskSet提交给TaskScheduler。非最上层的Stage的存入处理的列表中(waitingStages += stage)
流程如下:
![]()
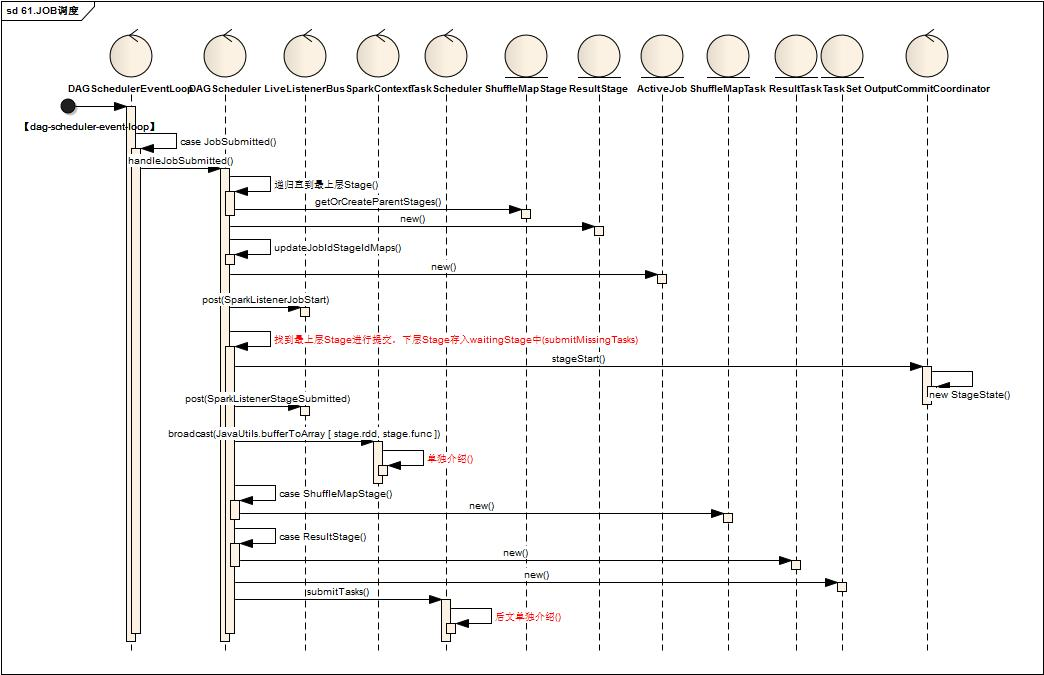
- DAGSchedulerEventProcessLoop中,线程【dag-scheduler-event-loop】处理到JobSubmitted
- 调用DAGScheduler进行handleJobSubmitted
-
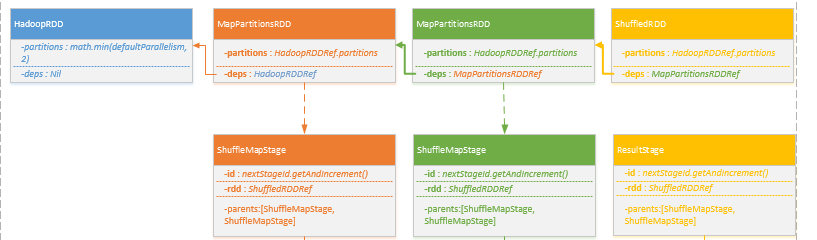
- 首先根据RDD依赖关系依次创建Stage族,Stage分为ShuffleMapStage,ResultStage两类
![]()
- 更新jobId与StageId关系Map
- 创建ActiveJob,调用LiveListenerBug,发送SparkListenerJobStart指令
- 找到最上层Stage进行提交,下层Stage存入waitingStage中待后续处理
-
- 调用OutputCommitCoordinator进行stageStart()处理
- 调用LiveListenerBug, 发送 SparkListenerStageSubmitted指令
- 调用SparkContext的broadcast方法获取Broadcast对象
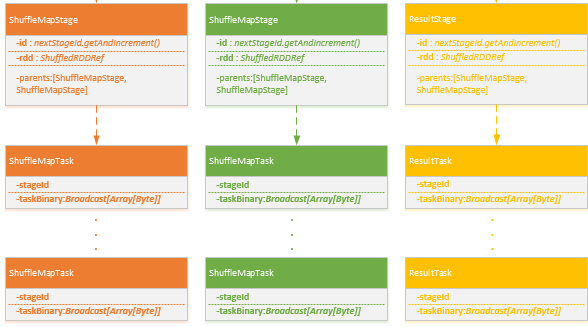
- 根据Stage类型创建对应多个Task,一个Stage根据findMissingPartitions分为多个对应的Task,Task分为ShuffleMapTask,ResultTask
![]()
- 将Task封装为TaskSet,调用TaskScheduler.submitTasks(taskSet)进行Task调度,关键代码如下:
- 首先根据RDD依赖关系依次创建Stage族,Stage分为ShuffleMapStage,ResultStage两类
taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
四、TaskSet封装为TaskSetManager并提交至Driver
TaskScheduler将TaskSet封装为TaskSetManager(new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)),存入待处理任务池(Pool)中,发送DriverEndpoint唤起消费(ReviveOffers)指令
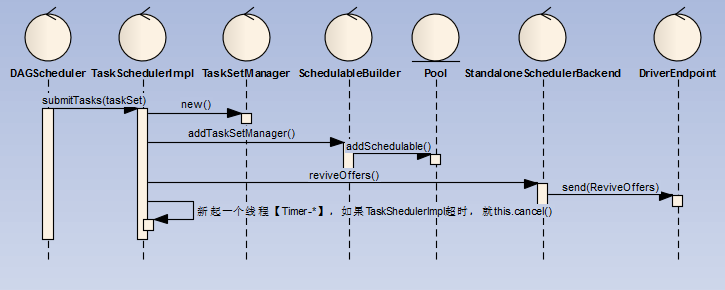
- DAGSheduler将TaskSet提交给TaskScheduler的实现类,这里是TaskChedulerImpl
- TaskSchedulerImpl创建一个TaskSetManager管理TaskSet,关键代码如下:
new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)
- 同时将TaskSetManager添加SchedduableBuilder的任务池Poll中
- 调用SchedulerBackend的实现类进行reviveOffers,这里是standlone模式的实现类StandaloneSchedulerBackend
- SchedulerBackend发送ReviveOffers指令至DriverEndpoint
五、Driver将TaskSetManager分解为TaskDescriptions并发布任务到Executor
Driver接受唤起消费指令后,将所有待处理的TaskSetManager与Driver中注册的Executor资源进行匹配,最终一个TaskSetManager得到多个TaskDescription对象,按照TaskDescription想对应的Executor发送LaunchTask指令
![]()
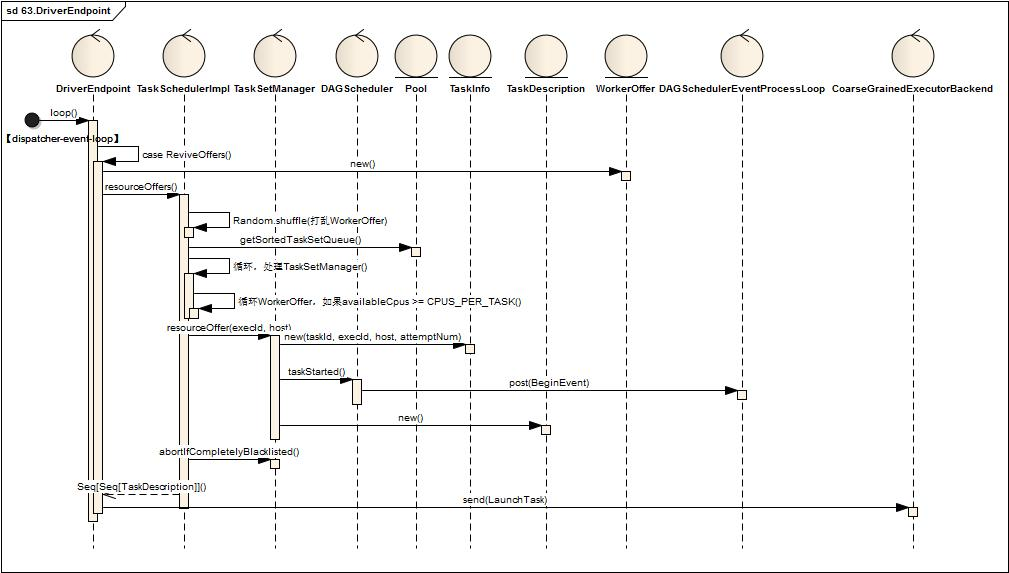
当Driver获取到ReviveOffers(请求消费)指令时
- 首先根据executorDataMap缓存信息得到可用的Executor资源信息(WorkerOffer),关键代码如下
val activeExecutors = executorDataMap.filterKeys(executorIsAlive) val workOffers = activeExecutors.map { case (id, executorData) => new WorkerOffer(id, executorData.executorHost, executorData.freeCores) }.toIndexedSeq
- 接着调用TaskScheduler进行资源匹配,方法定义如下:
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {..}
-
- 将WorkerOffer资源打乱(val shuffledOffers = Random.shuffle(offers))
- 将Poo中待处理的TaskSetManager取出(val sortedTaskSets = rootPool.getSortedTaskSetQueue),
- 并循环处理sortedTaskSets并与shuffledOffers循环匹配,如果shuffledOffers(i)有足够的Cpu资源( if (availableCpus(i) >= CPUS_PER_TASK) ),调用TaskSetManager创建TaskDescription对象(taskSet.resourceOffer(execId, host, maxLocality)),最终创建了多个TaskDescription,TaskDescription定义如下:
new TaskDescription( taskId, attemptNum, execId, taskName, index, sched.sc.addedFiles, sched.sc.addedJars, task.localProperties, serializedTask)
- 如果TaskDescriptions不为空,循环TaskDescriptions,序列化TaskDescription对象,并向ExecutorEndpoint发送LaunchTask指令,关键代码如下:
for (task <- taskDescriptions.flatten) { val serializedTask = TaskDescription.encode(task) val executorData = executorDataMap(task.executorId) executorData.freeCores -= scheduler.CPUS_PER_TASK executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))) }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号