【Spark2.0源码学习】-8.SparkContext与Application介绍
在前面的内容,我们针对于RpcEndpoint启动以及RpcEndpoint消息处理机制进行了详细的介绍,在我们的大脑里,基本上可以构建Spark各节点的模样。接下来的章节将会从Spark如何从业务代码分解为Spark的任务,并最终调度这些任务进行详细的介绍。
前面针对于Client启动过程以及Driver进行了详细的描述,下面我们根据用户代码中的SparkContext这个API类进行解读,该类Spark用户代码执行的基础,后续我们会陆续介绍,下面针对于SparkContext以及SparkContext运行过程中产生的Application进行介绍。
一、SparkContext创建过程
![]()
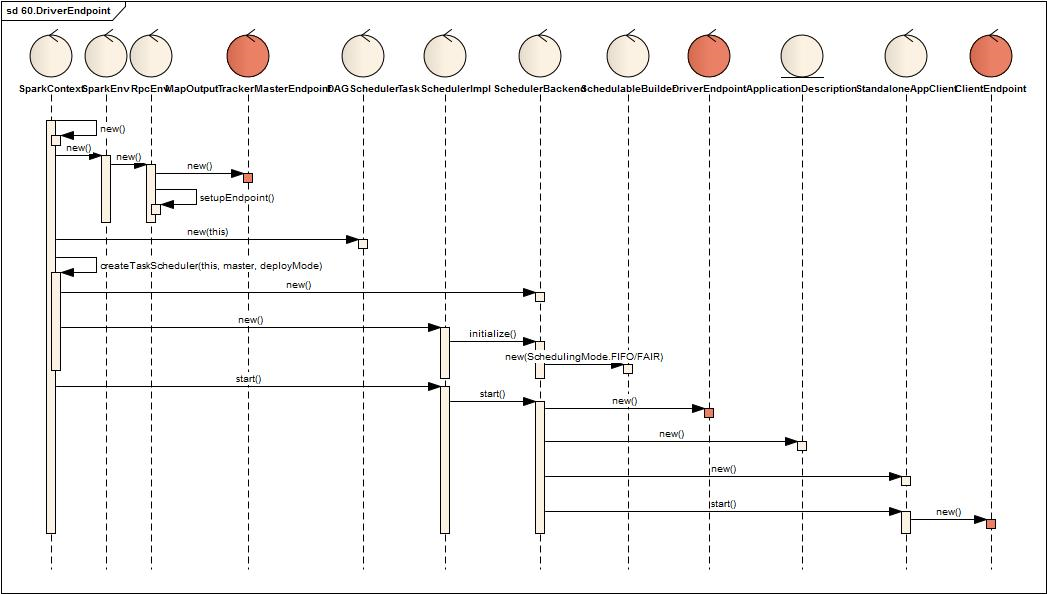
SparkContext在新建时
- 内部创建一个SparkEnv,SparkEnv内部创建一个RpcEnv
-
- RpcEnv内部创建并注册一个MapOutputTrackerMasterEndpoint(该Endpoint暂不介绍)
- 接着创建DAGScheduler,TaskSchedulerImpl,SchedulerBackend
-
- TaskSchedulerImpl创建时创建SchedulableBuilder,SchedulableBuilder根据类型分为FIFOSchedulableBuilder,FairSchedulableBuilder两类
- 最后启动TaskSchedulerImpl,TaskSchedulerImpl启动SchedulerBackend
-
- SchedulerBackend启动时创建ApplicationDescription,DriverEndpoint, StandloneAppClient
- StandloneAppClient内部包括一个ClientEndpoint
二、SparkContext简易结构与交互关系
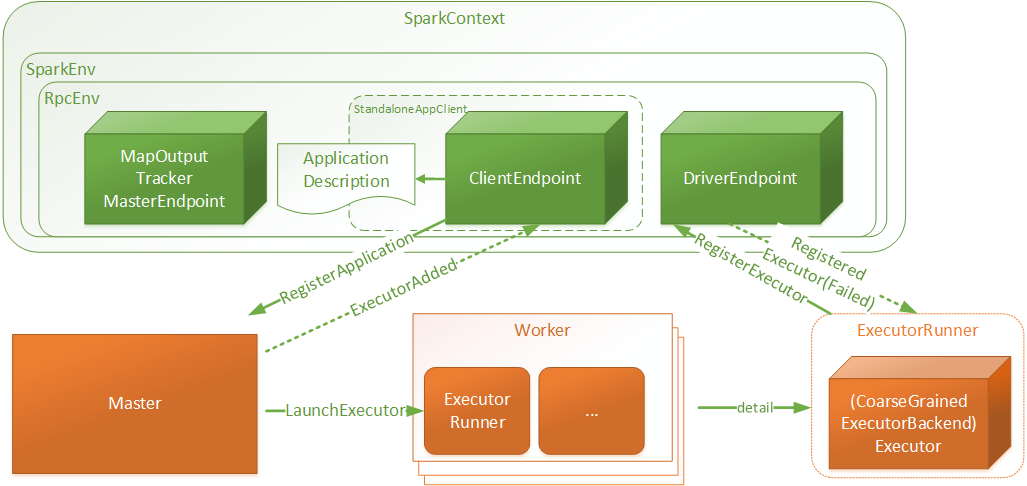
- SparkContext:是用户Spark执行任务的上下文,用户程序内部使用Spark提供的Api直接或间接创建一个SparkContext
- SparkEnv:用户执行的环境信息,包括通信相关的端点
- RpcEnv:SparkContext中远程通信环境
- ApplicationDescription:应用程序描述信息,主要包含appName, maxCores, memoryPerExecutorMB, coresPerExecutor, Command(
CoarseGrainedExecutorBackend), appUiUrl等 - ClientEndpoint:客户端端点,启动后向Master发起注册RegisterApplication请求
- Master:接受RegisterApplication请求后,进行Worker资源分配,并向分配的资源发起LaunchExecutor指令
- Worker:接受LaunchExecutor指令后,运行ExecutorRunner
- ExecutorRunner:运行applicationDescription的Command命令,最终Executor,同时向DriverEndpoint注册Executor信息
三、Master对Application资源分配
当Master接受Driver的RegisterApplication请求后,放入waitingDrivers队列中,在同一调度中进行资源分配,分配过程如下:

waitingApps与aliveWorkers进行资源匹配
- 如果waitingApp配置了app.desc.coresPerExecutor:
-
- 轮询所有有效可分配的worker,每次分配一个executor,executor的核数为minCoresPerExecutor(app.desc.coresPerExecutor),直到不存在有效可分配资源或者app依赖的资源已全部被分配
- 如果waitingApp没有配置app.desc.coresPerExecutor:
-
- 轮询所有有效可分配的worker,每个worker分配一个executor,executor的核数为从minCoresPerExecutor(为固定值1)开始递增,直到不存在有效可分配资源或者app依赖的资源已全部被分配
- 其中有效可分配worker定义为满足一次资源分配的worker:
-
- cores满足:usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor,
- memory满足(如果是新的Executor):usableWorkers(pos).memoryFree - assignedExecutors(pos) * memoryPerExecutor >= memoryPerExecutor
- 注意:Master针对于applicationInfo进行资源分配时,只有存在有效可用的资源就直接分配,而分配剩余的app.coresLeft则等下一次再进行分配
四、Worker创建Executor

(图解:橙色组件是Endpoint组件)
Worker启动Executor
- 在Worker的tempDir下面创建application以及executor的目录,并chmod700操作权限
- 创建并启动ExecutorRunner进行Executor的创建
- 向master发送Executor的状态情况
ExecutorRnner
- 新线程【ExecutorRunner for [executorId]】读取ApplicationDescription将其中Command转化为本地的Command命令
- 调用Command并将日志输出至executor目录下的stdout,stderr日志文件中,Command对应的java类为CoarseGrainedExecutorBackend
CoarseGrainedExecutorBackend
- 创建一个SparkEnv,创建ExecutorEndpoint(CoarseGrainedExecutorBackend),以及WorkerWatcher
- ExecutorEndpoint创建并启动后,向DriverEndpoint发送RegisterExecutor请求并等待返回
- DriverEndpoint处理RegisterExecutor请求,返回ExecutorEndpointRegister的结果
- 如果注册成功,ExecutorEndpoint内部再创建Executor的处理对象
至此,Spark运行任务的容器框架就搭建完成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号