Mobile Video Object Detection with Temporally-Aware Feature Maps
文章作者来自谷歌,发表在CVPR2018上面。
摘要:
本文提出了一个视频目标检测的在线模型,用于在移动设备和边缘设备上实时运行。我们的方法将速度快的单帧目标检测器和LSTM层结合,得到一个混合循环卷积结构。此外,我们提出一个高效的Bottleneck-LSTM层,和传统LSTM相比减少了计算量。我们的网络使用Bottleneck-LSTM来实现暂态记忆感知,并以此来改善和传播特征。这个方法在Imagenet VID数据集上表现的又快又好,在一个移动CPU上达到了15FPS的实时推理速度。。
1.介绍
视频包含各种时序信息,可以利用这些时序信息来得到更加准确和鲁棒的检测结果。因为视频是连续的,相邻帧中的目标都有相近的位置。因此,可以将之前帧的检测结果用于当前帧结果的校准。例如,网络通过不同的帧可以看到一个目标的不同视角,这样可以帮助提高目标检测的精度。网络也会跟随时间变得更加稳定。
我们想要利用视频帧的连续性在特征空间加入时间感知信息,通过循环网络结构来实现。
我们使用标准卷积层和convLSTM组成的卷积循环单元来得到特征。卷积层输出一个中间特征,随后将这个特征输入LSTM并同包含了之前帧的时序语义的特征进行融合,得到一个更好的特征。Figure 2展示了我们方法的示意图。
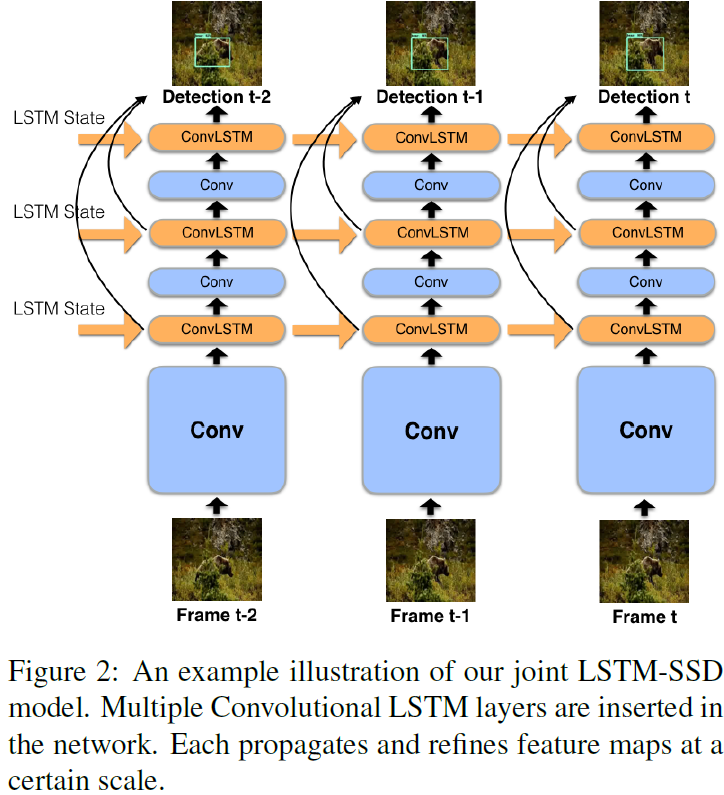
我们可以有效地利用基于图片的目标检测器,将它用我们的卷积循环单元进行扩展。卷积循环层可以在帧间进行时序特征的传播,让网络在视频处理过程中获得更高质量的特征。
为了说明我们模型的有效性,我们在Imagenet VID 2015数据集上做了测试。我们的方法同之前的高效单帧baselines相比更好,由于我们没有增加额外的判别特征,因此性能提升肯定是由成功引入时序性息带来的。我们的模型变体大小从200M到1100M不等,参数量在100万到350万之间,能够直接应用到许多移动端和嵌入式平台。
本文的贡献主要有如下几点:
- 提出了一个计算量小的实时视频目标检测结构。
- 利用循环卷积层在特征中加入时序信息。
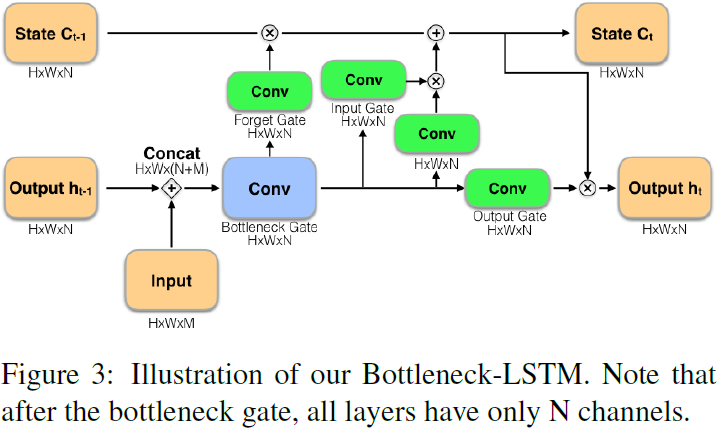
- 通过改进convLSTM使其更加高效,证明了在网络中加入循环层是高效可行的。
- 进行了实验证明设计的有效并和其他单帧图片检测框架进行了比较。