
Detect to Track and Track to Detect
一作来自Graz University of Technology,论文发表在CVPR2017上面。
tracklets:相邻若干帧的目标物体运动轨迹
摘要:
最近的准确率较高的视频目标检测和跟踪方法都包含了复杂的多阶段解决方案。这篇文章中我们提出了一个ConvNet结构,能够同时进行检测和跟踪,以一种简单有效的方法解决了这一任务。
文章的贡献主要是三个方面:
- 设置了一个ConvNet结构来同时进行检测和跟踪,使用了一个多任务目标函数来进行逐帧的检测和跨帧跟踪回归。
- 引入了目标在时间尺度上的相关特征来辅助ConvNet进行跟踪。
- 我们将帧与帧之间的检测结果用跨帧的目标跟踪轨迹联系起来,以此来产生视频上的精确度更高的检测结果。
我们的ConvNet在ImageNet VID这个大规模数据集上做了评估,实现了state-of-the-art的结果。我们的方法的结果比上一次ImageNet竞赛的获胜者更好,同时也更简单。最后,我们表明通过增加时间跨度,
能够显著的增加跟踪的速度。代码在:http://github.com/feichtenhofer/detect-track
1.简介
由于近年来深度卷积网络和RCNN的发展,图片上的目标检测取得了非常大的关注和提升。在做视频中的目标检测和跟踪时,最近的方法大多是首先检测,然后用后处理的方式,比如用一个跟踪器来对检测框进行跟踪。
这样的“tracking by detection”的方法虽然取得了不小的进步,但还是要受限于图片检测器。
视频目标检测最近掀起了一阵研究热潮,尤其是在ImageNet VID竞赛提出之后。不同于ImageNet DET竞赛,VID中目标会在图片序列中出现,并且往往伴随着额外的挑战:
- 数据集大小:VID中有1.3M张图片,作为对比,DET有400K张,COCO有100K张。
- 运动模糊:由相机运动或目标运动造成。
- 图片质量:网络视频片段的质量通常不如静态图片。
- 部分遮挡:由视角变化或者目标移动造成。
- 姿势:不常见的姿态在视频序列中频繁出现。
图1中我们展示了一些从VID数据集中采样的图片。

为了解决这个挑战性的任务,最近的ImageNet VID竞赛中的前几名采用一些基于图片检测器的繁复的后处理方式。比如ILSVRC'15的冠军采用两个多阶段的Faster R-CNN检测框架,上下文抑制,多尺度训练/测试,
ConvNet跟踪器,基于光流的传播和多模型。
这篇文章中,我们提出一个独特的方法来处理真实视频中的目标检测问题。我们的目标是直接在多帧间加入跟踪器来同时进行检测和跟踪。受到当前基于跟踪器的相关与回归的启发,我们在R-FCN中加入了这样的跟踪。
我们用检测和跟踪的损失端到端地训练了一个全卷积网络,我们给他取名叫做D&T,因为能同时进行检测和跟踪。网络的输入包含多帧,首先通过一个ConvNet主干(如ResNet-101)来得到用于检测和跟踪任务的卷积特征。
我们在相邻帧的特征响应上计算卷积互相关,在不同特征尺度上估计局部变化。在最后的卷积特征上,我们使用了一个RoI pooling层用来对bbox进行分类和回归,同时使用了一个RoI-tracking层用来回归bbox在不同帧间的
的变换(移位,尺度,高宽比)。最后,根据目标在多帧上的跟踪轨迹来对整个视频中的检测框进行了推断校准。
在ImageNet VID数据集上的评测显示我们的方法能产生比ILSVRC'16冠军更好的单模型性能,同时我们的方法有更加简单的想法和更快的速度。此外,我们还发现加入tracking损失可以提升特征学习的表征性,来得到更好的静态图片检测器,
同时我们还提出了一个非常快速的D&T版本用于实时对输入图片检测。
3. D&T方法
3.1. D&T概述
我们的目标是在视频中同时进行目标检测和跟踪。图2展示了我们的D&T结构。
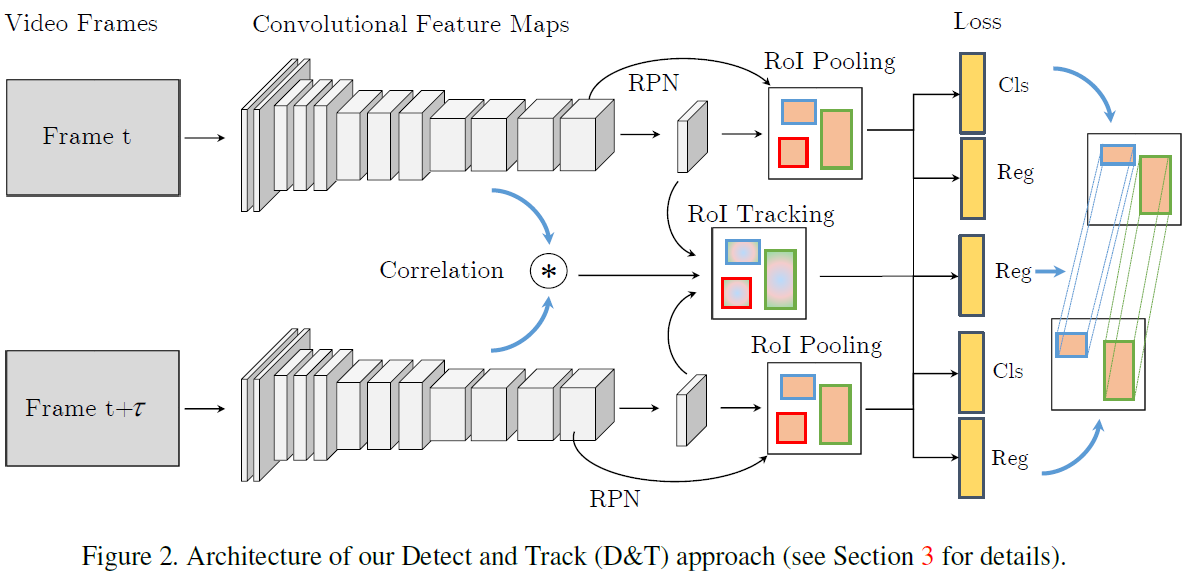
我们以R-FCN为基础,将它扩展成进行多帧检测和跟踪的框架。给定一组由两帧图片组成的数据,我们的框架首先计算出用于检测和跟踪的卷积特征。用RPN来基于anchor产生候选框。
基于这些候选框,在位置敏感分数图和回归图上应用RoI pooling,得到每一个框的分类和回归结果。
我们通过引入一个回归器对这一结构进行了扩展,将两张图片的中间部分的位置敏感回归图与相关图一起输入RoI tracking 层,得到box从一帧到另一帧的的坐标变换。因此两帧间的对应关系
通过在同一候选区域做池化来得到。RoI tracking任务回归了目标在帧间的坐标变换,我们通过在R-FCN损失函数中加入tracking loss 来对它进行了训练。tracking loss在ground truth上进行计算,计算预测的track和GT的track坐标的soft L1.
这样的tracking方式可以看作对论文[13]中的单目标跟踪进行的一个多目标扩展。这个方法的一个缺点是没用利用平移变换性,意味着tracker必须从训练数据中学习所有可能的变换。因此需要在训练过程中进行额外的数据增广(缩放和平移)。
基于相关滤波的tracking方式可以利用平移变化性,因为相关性是平移变换的。最近的相关性tracker通常在high-level的卷积特征上运行,在待搜索图片和跟踪模板之间计算相关性。得到的相关性图衡量了模板和搜索图片间的相似性。因此,
可以通过找相关性响应图的最大值来找目标的位移。
不用于典型的用于单目标跟踪的相关性tracker,我们旨在同时进行多目标跟踪。我们在特征图上的所有位置都计算相关性图,然后让RoI tracking在这些特征图上运行来得到更好的跟踪回归。我们的框架可以进行端到端的训练,输入视频中的帧,
得到目标检测的结果和轨迹。
3.2 object detection and tracking in R-FCN
我们的框架在时刻t输入帧\(I^t\in R^{H_0\times W_0 \times 3}\),然后将其输入一个backbone卷积(i.e. ResNet-101)来得到feature map \(x_l^t \in R^{H_l\times W_l\times D_l}\),其中l代表卷积层l。在R-FCN中,我们通过修改conv5 使其拥有unit spatial stride,让最后一个卷积层的实际stride从32降到16,同时还通过使用膨胀卷积来增加了感受野。
我们总体系统构建在R-FCN的基础上,分两个stage:首先使用RPN网络提取候选的ROI;其次,通过position-sensitive ROI pooling层来进行区域分类,把每个region分为不同的类别或者背景。
现在有一对在时间t和\(t+\tau\)采样的帧\(I^t,I^{t+\tau}\),将其作为网络的输入。现有一个帧间的bbox回归层,它在bbox回归特征\(\{x_{reg}^t,x_{reg}^{t+\tau}\}\)上做position sensitive RoI pooling操作来预测RoI从时间t到\(t+\tau\)的坐标变换\(\Delta^{t+\tau}=(\Delta_x^{t+\tau},\Delta_y^{t+\tau},\Delta_w^{t+\tau},\Delta_h^{t+\tau})\)。图3展示了这个方法的示意图。
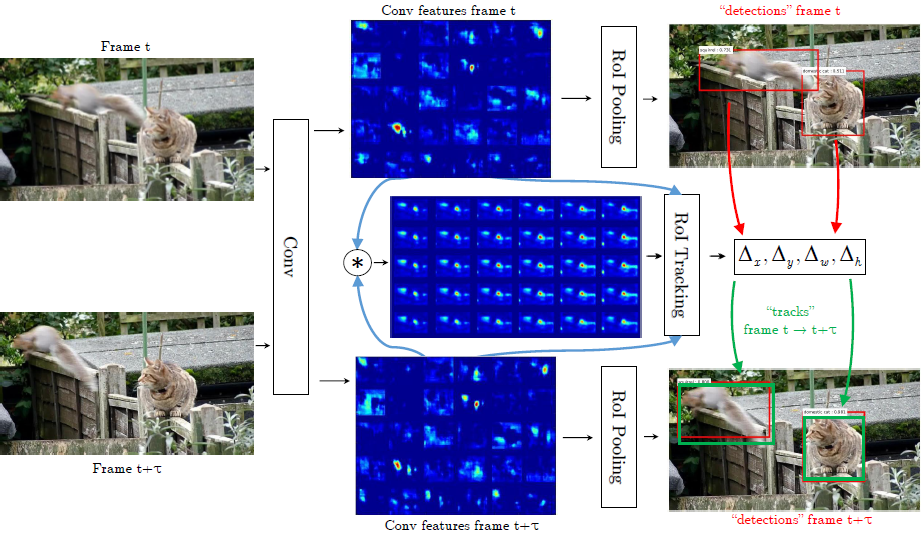
图3.我们的方法图解。输入图片首先通过一个全卷积网络来得到feature maps。在不同尺度的多个feature map上进行关联层操作(图中仅展示了最粗糙的尺度),同时估计两帧的局部特征相似性。最后,position sensitive ROI-pooling在每一帧的卷积特征上产生每一帧的检测结果,同时在堆叠的特征图和关联特征的基础上得到两帧中框的回归偏差(ROI-tracking)。
3.3 multitask detection and tracking objective
为了学习回归器,我们对Fast R-CNN的多任务损失函数进行了扩展,除了分类损失\(L_{cls}\)和回归损失\(L_{reg}\),还加入了一个对两帧间的跟踪结果的度量\(L_{tra}\)。对于一个iteration和一个包含N个ROI的batch,网络预测了softmax probabilities \(\{p_i\}_{i=1}^N\),
回归 offsets \(\{b_i\}_{i=1}^N\), 以及跨帧的 ROI-tracks \(\{\Delta_i^{t+\tau}\}_{i=1}^{N_{tra}}\)。我们总体的目标函数形式为:
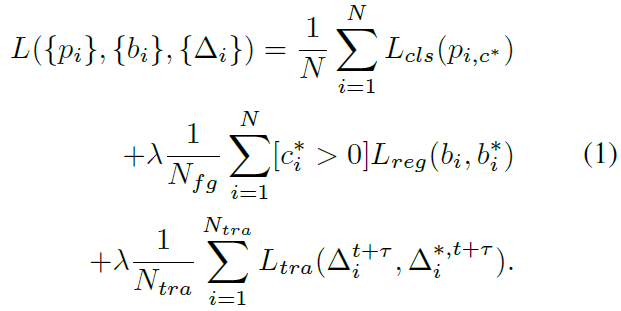
一个ROI的groundtruth 的类别标签为\(c_i^*\),预测标签的softmax 分数为\(p_{i,c^*}\)。\(b_i^*\)是groundtruth regression target,\(\Delta_i^{*,t+\tau}\)是track regression target。\([c_i^*>0]\)函数判断ROI是背景还是前景。\(L_{cls}(p_{i,c^*})=-log(p_{i,c^*})\)是用于box分类的交叉熵损失函数,\(L_{reg}和L_{tra}\)是bbox和track回归的损失,均为smooth L1函数。tradeoff参数被设置为\(\lambda=1\)。ROIs同GT的关系如下:如果RoI和GT box的IOU超过0.5,则将类别\(c^*\)和回归目标\(b^*\)分配给它;仅当GT在两帧中都出现时评估tracking target。因此,公式(1)的第一项用于training batch的所有N个框,第二项仅用于被分类为前景的框,最后一项仅用于在GT在两帧中都出现的框。
在轨迹回归中我们使用了R-CNN中的bbox回归变量。帧t里面的单目标有一个GT框坐标\(B_t=(B_x^t,B_y^t,B_w^t,B_h^t)\),在\(t+\tau\)帧中也有相似的\(B^{t+\tau}\),表示框在水平和竖直方向的中心坐标和框的高宽。目标的tracking 回归的值\(\Delta^{*,t+\tau}=\{\Delta_x^{*,t+\tau},\Delta_y^{*,t+\tau},\Delta_w^{*,t+\tau},\Delta_h^{*,t+\tau}\}\)定义为:
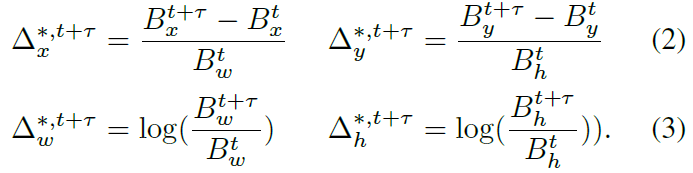
3.4. correlation features for object tracking
不同于典型的单目标相关性tracker,我们希望能够同时跟踪多目标。我们在特征图上的每一个位置都计算相关性响应图,然后让ROI pooling在这些特征图上进行操作得到track 回归结果。考虑到特征图上的所有可能的circular shifts会导致输出一个很大的维度,同时也会产生较大的位置偏移。因此,我们对局部周围的相关性进行了严格的限制。这个idea最早是在flownet中用于光流估计的,其中在卷积块中加入了一个关联层来进行帧间的特征点匹配。关联层在两个特征图\(x_l^t,x_l^{t+\tau}\)上进行了逐点特征比较。
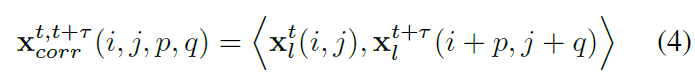
其中p q是以位置i,j为中心的边长为d的方块的偏移量。因此,关联层的输出是一个大小为![]() 的特征图。等式(4)可以被看为两个特征图在局部大小为d的方形窗内的关联。我们在conv3,conv4和conv5都计算了这一特征局部关联。我们在图4中可视化了两个样本序列的关联。
的特征图。等式(4)可以被看为两个特征图在局部大小为d的方形窗内的关联。我们在conv3,conv4和conv5都计算了这一特征局部关联。我们在图4中可视化了两个样本序列的关联。
为了使用这些特征用于track-regression,我们将bbox features和关联特征堆叠在一起得到\(x_{corr}^{t,t+\tau},x_{reg}^t,x_{reg}^{t+\tau}\),然后在堆叠后的特征上做ROI pooling。

4. linking tracklets to object tubes
精度高的目标检测方法的一个弊端是,受限于硬件的限制,一次性能处理的帧数不多。因此,精度和处理数量之间必须做一个权衡。因为视频中有冗余的信息和目标在每一帧中连续出现,我们可以使用帧间track来将检测结果连接起来并建立长时的物体轨迹。最后,我们应用了在动作定位中的一套方法来进行帧间检测结果的连接。
设时间t的帧的检测结果为\(D_i^{t,c}=\{x_i^t,y_i^t,w_i^t,h_i^t,p_{i,c}^t\}\),其中\(D_{I}^{t,c}\)是索引为i的框,中心为\(x_i^t,y_i^t\),宽为\(w_i^t\),高为\(h_i^t\),\(p_{i,c}^t\)是框为c类的概率。同时,设轨迹\(T_i^{t,t+\tau}=\{x_i^t,y_i^t,w_i^t,h_i^t;x_i^t+\Delta_x^{t+\tau},y_i^t+\Delta_y^{t+\tau},w_i^t+\Delta_w^{t+\tau},h_i^t+\Delta_h^{t+\tau}\}\),描述了框从帧t到\(t+\tau\)的变换。现在我们可以定义一个联合了检测结果和跟踪的逐类别的linking score:
![]()
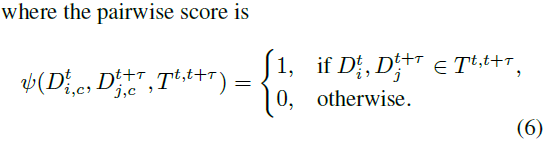
这里\(\psi\)为1,如果track 对应的\(T^{t,t+\tau}\)和检测框\(D_i^t,D_j^{t+\tau}\)的IOU大于0.5。这很重要,因为track regressor的输出不需要和box regressor的输出完全匹配。
然后可以通过最大化持续时间T上的视频的分数来得到最佳路径。
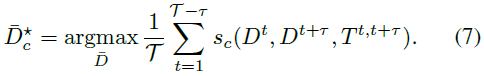
等式(7)可以用Viterbi算法进行高效求解。一旦求得最优路径,相关的检测结果被移除,然后继续在剩下的区域继续找最优路径。
结果:
79.8mAP,7.1fps。backbone:resnet101,\(\tau=1\).GPU:titan x
