

CATDET: Cascaded Tracked Detector for Efficient Object Detection from Video
文章提出了一个利用视频时序相关信息来加速视频目标检测的方法叫CaTDet。CaTDet包含了两部分,一个检测器和一个额外的基于之前检测结果的跟踪器用来预测RoI。
算法大概流程是这样的:用一个轻量的proposal网络来预测可能的存在目标的区域;用一个tracker来跟踪当前帧的检测结果中置信度高的bbox,预测出被跟踪的bbox在下一帧中的位置;
对每一帧来说,将proposal网络的检测结果和tracker的跟踪框结合在一起得到一个可能存在目标的区域(相比于原图更小),并输入refinement网络对检测结果进行校准。
CaTDet是基于验证和校准比重新检测要简单的想法,在某一帧中被检测到的目标极有可能会继续出现在下一帧中。基于这个先验知识,在之前物体存在的区域运行一个高精度的检测器能节省运算量并保持精度。
然而这个简单的想法会面临两个问题:
1.当有新的目标出现在下一帧时是很难预测的。文章用了一个快速、低精度的proposal network检测器来定位可能的目标。很高的fp也是可以接受的,因为后面有高精度的检测器对结果进行校准。这里提出的proposal network和
Faster R-CNN中的RPN网络十分相似。
2.目标或者相机的移动会导致定位偏移。有些情况下,由于遮挡目标会暂时消失。如果校准网络仅简单关注之前的物体框的位置,一些很小的不匹配或者时间丢失会导致永久的损失。因此,这里用了一个跟踪器来作为鲁棒特征定位预测器。
一个CatdET的工作过程图如下所示:
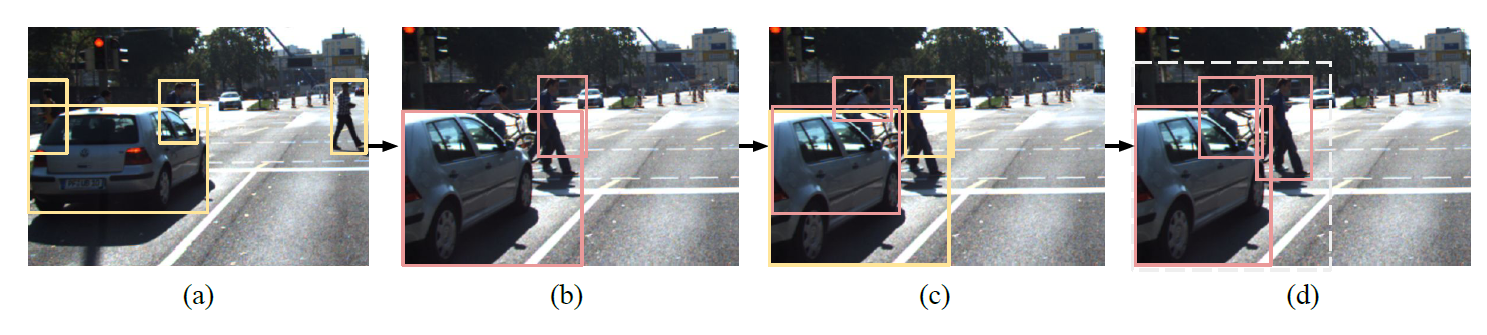
图1.每一步输出中的新物体标注为红色框,之前的物体标注为黄色框。(a).上一帧的检测结果,(b). 用跟踪器预测的已存在物体的位置。离开当前帧的物体框都被删掉了。(c). 加入新的用proposal网络检测的物体。(d). 校准网络对选出来的虚线框内的结果进行校准。

