Progressive Sparse Local Attention for Video object detection
motivation:
之前使用flownet的方法有诸多弊端。
1.在检测框架中加入光流网络极大地增加了检测器模型的参数,无法用在移动端。
2.光流原本是描述两张图片间像素点的位移的,直接将其用在high-level的feature map上会引入人为的干扰。特别的,high-level的feature map上的像素点移动一格,对应的图片上可能存在10-20个像素点的位移,光流估计大位移容易出错。
因此本文舍弃了光流网络,提出了一个叫做Progressive Sparse Local Attention(PSLA)的新模型用来替代光流网络,在高层语义特征之间做特征传播。
具体来说,\(F_t,F_{t+\epsilon}\)分别为帧\(I_t,I_{t+1}\)的特征,PSLA首先计算两特征之间的correspondence weights,然后用这个计算出的权重与特征做卷积来进行特征对齐。这个机制和attention很像但有不同之处,后面会介绍。
和之前的视频目标检测方法类似,本文也是仅在稀疏的关键帧上做特征提取,并用PSLA得到非关键帧的特征。PSLA用在两个地方:
1.将关键帧的特征传播到非关键帧;此外,一个轻量的质量网络被用在非关键帧上,将非关键帧的low-level feature用来同传播来的high-level feature做补充。文章称之为Dense Feature Transforming(DFT).
2.在关键帧之间进行特征传播;此外,一个更新网络被用来递归地更新关键帧上的特征。文章称之为Recursive Feature Updating(RFU).
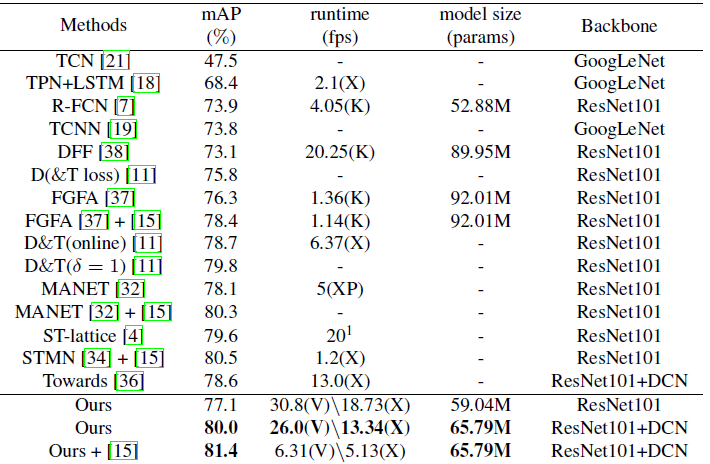
所提出的框架概览:
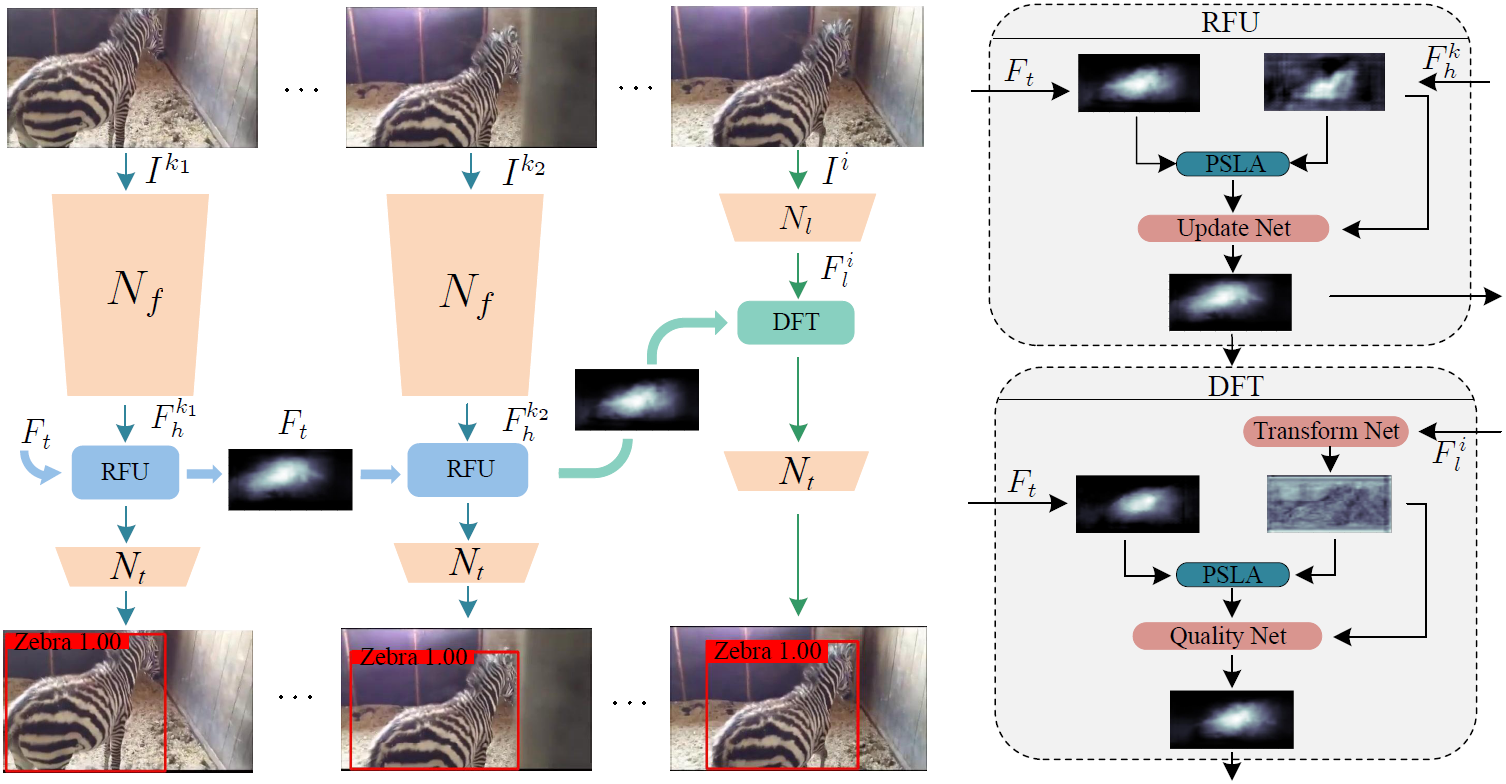
图1.以两张关键帧\(I^{K1},I^{k2}\)和一张非关键帧\(I^i\)为例来简单说明文章的算法框架。关键帧首先送到\(N_f\)来得到高层特征\(F_h^k\),非关键帧送入一个轻量的网络\(N_l\)来提取低层特征\(F_l^i\)。
时序特征\(F_t)用RFU来增强高层特征,其中\(F_t\)是由更新网络结合高层特征来递归更新得到的。与此同时,用DFT在关键帧和非关键帧之间传播特征。
PSLA:
用来进行特征传播过程中的特征对齐,是本文的核心。这一操作的motivation如图2所示;
作者随机选了100段视频用flownet提取了光流,然后对光流的值进行了统计,分为水平和竖直方向分别进行了统计。可以看到光流值大部分集中在0附近。
这说明用来计算关联权重的特征单元可以被限制到一个较小的区域,在这个区域里用渐进式稀疏步幅来选择参与计算的特征pixel。渐进式稀疏步幅使PSLA更关注于近邻的具有小光流的区域。
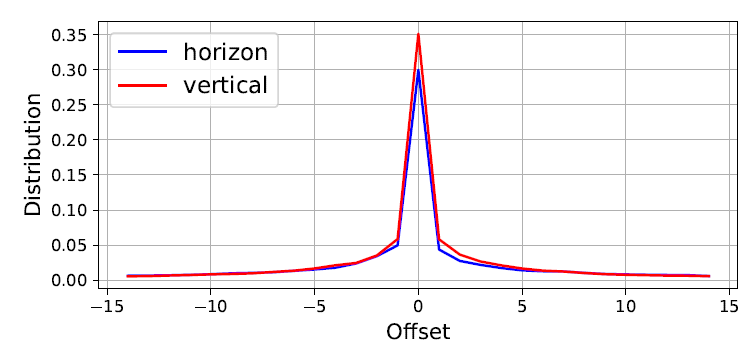
PSLA的操作可以归纳为两步,如下图所示:
第一步,基于两个特征的相似性计算稀疏关联权重值(sparse correspondence weights)。计算公式如下:
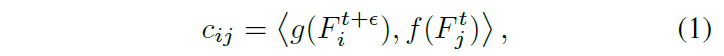
值得说明的是,这里的i,和j均代表一个二维坐标。
![]() ,这里计算两个一维向量的内积,代表两个向量的相似度。
,这里计算两个一维向量的内积,代表两个向量的相似度。
其中i代表上图中第一个方格图中的深色点坐标,j代表第二个方格图中的方框内的深色点坐标。第二个方格图中深色点坐标的产生具体可看原文。
最后将计算的得到的权重系数用softmax做归一化,
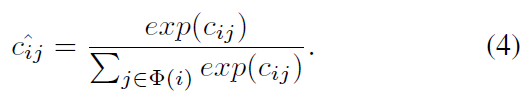
然后得到对齐后的特征:
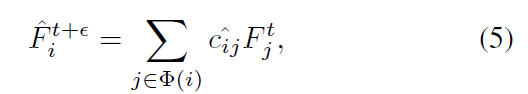
这个过程其实就是首先求一个卷积核的权重,然后用卷积核在特征图上做卷积操作得到待估计图片的特征。
递归特征更新:
被用在稀疏关键帧之间进行特征聚合增强的操作。为了利用之前帧的时序语义信息,在关键帧上不仅要进行特征提取,还要聚合之前关键帧的时序信息,得到一个更强的特征表达。
具体的方法和之前的文章类似,这里就不过多赘述。
稠密特征传播:
被用在关键帧和非关键帧之间,使用PSLA将之前关键帧的增强后特征传播到当前非关键帧。这里还用了非关键帧的low-level和传播来的特征进行了一个融合,增强了细节表达。
实验结果:mAP=77.1,titan x上18.73fps,比之前的工作有一些提升。