
Towards High Performance Video Object Detection
来自MSRA视觉计算组,发表在CVPR2018上,对DFF和FGFA的改进。
- motivation
- 在DFF和FGFA的基础上提出三个改进
- 对速度和精度进行权衡
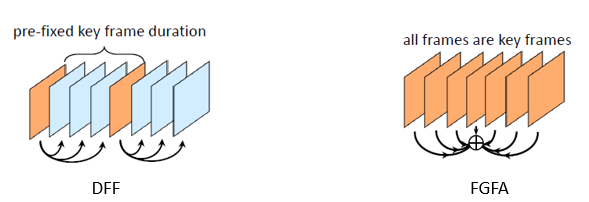
DFF和FGFA分别专注于提高速度和精度,这篇文章尝试把两者的优势结合起来,得到一种速度块精度高的算法。作者在DFF和FGFA的基础上提出三个改进,
在速度和精度上做了一个很好的权衡。
- 特征的稀疏递归聚合

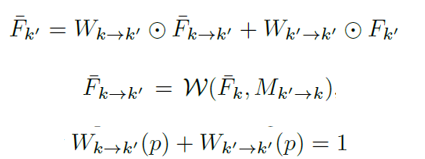
与FGFA在每一帧上就进行特征聚合不同,这里特征只在稀疏的关键帧之间进行聚合。上一个关键帧增强当前关键帧,增强后的关键帧又去增强下一个关键帧。
对于两个连续的关键帧k和k',递归特征聚合采用第一排的公式进行。用上一帧warp过来的特征和当前帧的真实特征进行加权求和,得到聚合的增强特征。聚合后的关键帧
特征包含了之前所有关键帧的历史特征信息。
- 空间自适应局部特征更新

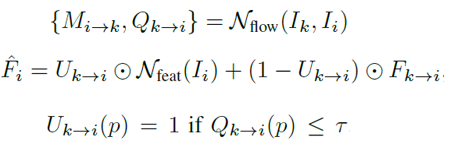
出发点是与关键帧相邻的非关键帧有部分区域变化较大,这部分区域用光流传播的特征容易出错,所以需要预测哪些区域的特征可以很好地传播而哪些区域的特征是需要重新
在图片上计算的。这里引入了一个叫做特征信息时间一致性的判别矩阵Q,有光流网络生成,大小和特征光流场一样大,每一个位置的值表示这个位置的光流的质量。若Q在某位置p
的值小于阈值τ,说明位置p的光流不ok,质量不好,用它来传播的特征与真实特征是不一致的,就是说不能在位置p处使用传播的特征,需要重新计算位置p的特征。由此可以给出非关键帧
i处的空间特征信息局部更新公式。这里的\(N_feat\)应该不是对整幅图做特征提取,文章里没有细说,推测应该是只在选出来的光流不好的位置做卷积运算提取特征,这样达到一个加速的目的。
- 自适应的关键帧选取
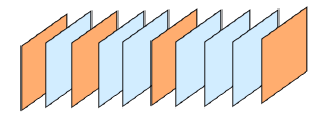

之前的关键帧是固定间隔选取,这里作者调整为动态选取。利用矩阵Q(同上),和is_key这个判别函数算出那些光流质量不好的点占的比例,如果大于设置的阈值γ,就一定程度上说明当前帧和上一关键帧的变化已经太大了,
需要设置成新的关键帧来重新计算特征。作者可视化了这一判别过程。
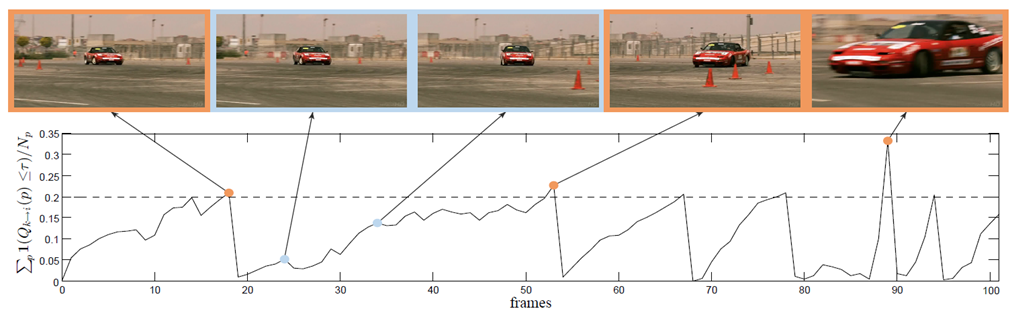
三个橙色的框表示别判别函数判为关键帧的情况,这三张图片内容差距很大,蓝色框被判为非关键帧,这两个图片与之前的关键帧图片内容相似。
- 实验结果
将上面提到的三种改进结合在一起,得到如下示意图。
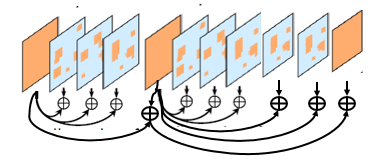
动态选取关键帧,关键帧与关键帧之间采用递归聚合,关键帧与非关键帧之间采用空间自适应局部特征更新。用这种方式得到了最后实验结果。

主要看三条红线,最下面一条是仅采用关键帧递归聚合的结果,比DFF高一个点左右,往上第二高的曲线是继续加上空间自适应局部特征更新的结果,继续提高了一个点左右,
最上面那一条是继续加上动态选取关键帧的结果,略有提升。这个方法较FGFA也实现了一个较大的加速,从图中看在同等性能条件下速度大概提高了4倍。

