
Flow-Guided Feature Aggregation for Video Object Detection
来自MSRA视觉计算组,发表在ICCV2017上,提出了一个通过特征聚合来增强特征的方法。
- motivation
- 视频中的退化现象很严重
- 通过聚合多帧的特征来对每一帧特征进行增强
- 用光流传播特征

视频目标检测中,存在图像质量退化的问题,具体的如图,有运动模糊、视频失焦、部分遮挡、奇特姿势等。现有的目标检测算法不能很好地应对这些问题。作者打算
利用视频的连续性,视频中短时间内同一目标会被多次观察到,用质量好的图像特征来增强质量差的图像特征,来达到提高检测精度的目的,总结为一句话就是:单帧不够,多帧来凑。
这里也用到了光流对特征进行warp。
- FGFA的算法
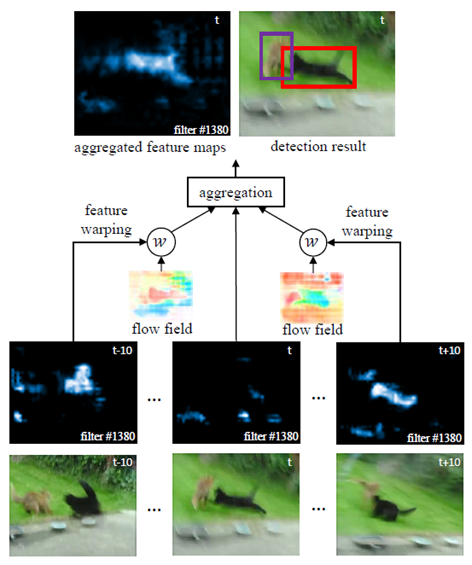
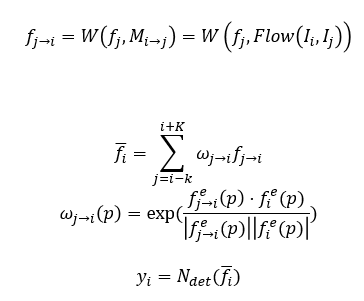
与DFF不同,FGFA追求精度而不考虑速度,对于视频中的所有帧都做同样的处理,就是说把每一帧都当作关键帧。同时提取关键帧和其前后相邻K帧的特征,一共提取2K+1帧的图片特征,
并计算每一相邻帧和关键帧的特征光流图,然后将相邻帧的特征warp到关键帧,最后通过加权求和得到关键帧的增强特征,这里对feature map上每一个点都求一个权值,这里每一个点的权值
代表了这个点对关键帧上对应点的重要性,如果warp后的特征与关键帧的特征越接近,就给予更大的权值,否则分配较小的权值。这里用余弦相似度来衡量两个特征的相似度,最后通过softmax
对权值进行归一化,将增强后的特征送入检测网络,得到检测结果。
- result
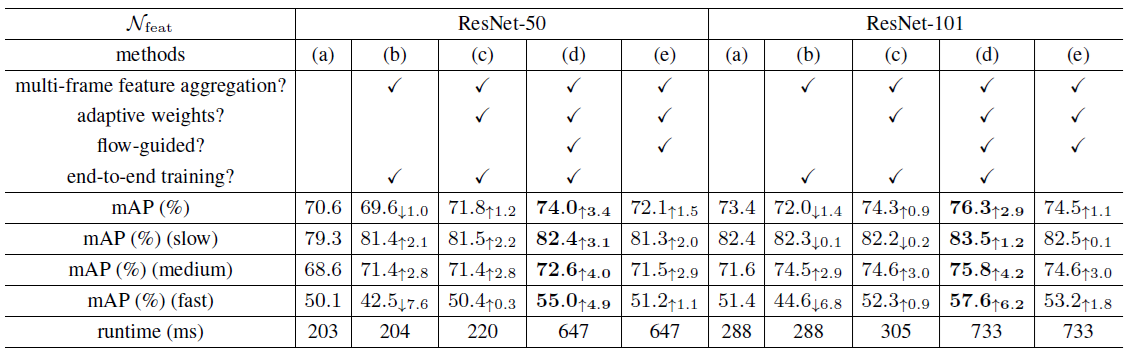
通过特征聚合的方式,FGFA得到了更高的精度,用resnet101做特征提取时,与单帧图片检测的baseline的73.4mAP相比,本文提出的方法达到了76.3的mAP,但是损失了很多速度,帧率只有1.36。
同时作者还做了一些额外的实验,他将测试的图片根据运动物体的快慢分成了三类,慢速、中速和快速,分别测试了算法在这三类图片上的实验结果,中速和慢速的mAP都挺高的,但是快速的mAP只有57.6。
同时与baseline相比,FGFA对中速和快速类的图片检测精度提升都挺高的,对慢速类的提升较小。此外还通过消融学习的方法说明了文章提出的加权特征聚合、光流warp、端到端训练的有效性。
