
Deep Feature Flow for Video Recognition
来自MSRA视觉计算组,发表在CVPR2017上。这篇文章提出了一个结合光流的快速视频目标检测和视频语义分割方法。
- motivation
- 在视频流的每一帧上用CNN计算特征太慢了。
- 两个相邻帧有相似的feature map
- 结合光流将特征进行传播

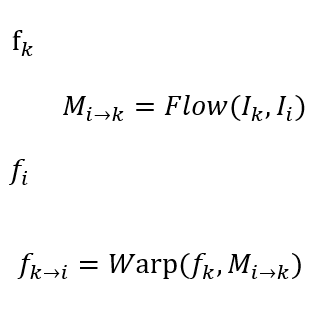
在目标检测和语义分割任务中,通用的做法是首先将图片送到一个深层卷积网络提取特征,再将特征送入相应的任务网络得到结果。在视频上进行目标检测或者语义分割任务时,
如果继续使用单帧图片的方法,将有大量的时间耗在特征提取上面,无法做到实时性。而由于视频的连续性,相邻两帧的feature map其实具有很高相似度,这里作者通过可视化resnet101
最后一个卷积层里面的两个卷积核输出的特征来进行了验证。
第一排和第二排分别是同一视频中的相邻的两帧,第一列是原始图片,后两列是可视化之后的卷积特征,可以看到上下两排卷积特征非常相似。同时卷积特征与图像内容保持了空间的
对应性,可以看到中间的特征图上激活的汽车特征的位置和原始图片上汽车的位置是对应的,而这种对应性能够提供使用空间warp,将临近帧的特征进行轻量传播,以此来避免在每一帧上
都进行特征提取。这里作者使用了光流信息进行特征传播,将第一帧的特征\(f_k\)与两帧的光流\(M_{i\to k}\)结合,warp得到第二帧的特征估计\(f_{k\to i}\)。第三排就是warp得到的结果,与
CNN计算的真实效果,也就是第二排差不多。通常光流估计和特征传播比卷积特征的计算快得多,能够实现显著的加速。
- 什么是warp操作?

warp最开始是用在对图片像素点进行对齐的操作。光流本质就是记录了某帧图片上的像素点到另一帧的运动场,光流图上每一个点对应着图片上该点的二位运动矢量。假设我们知道
第t帧中的点P会运动到第t+1帧,这样就得到了运动矢量。这时如果我们已知第t帧的像素值和第t+1帧每个像素点的运动矢量,则可倒推出t+1帧上的点在第t帧的位置,则可以通过双线
性插值来得到对应的点的像素值。由于光流值通常不是整数值,因此用双线性插值。
- deep feature flow算法
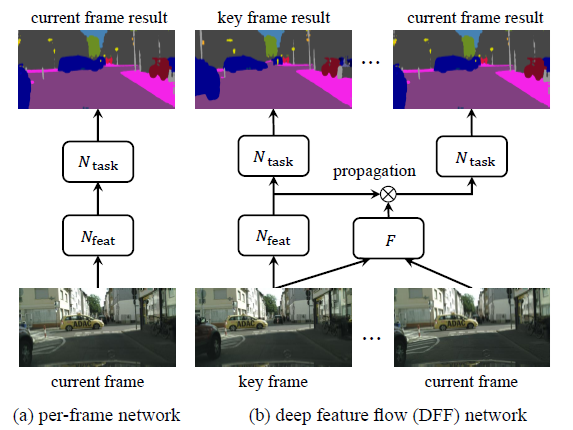
文章中将目标检测或者语义分割网络分解成两个连续的子网络,\(N_{feat}\)是特征网络,一般用resnet,\(N_{task}\)是任务网络,在特征图上进行语义分割或者目标检测任务。
图中的F是光流估计网络,这里用的是改造过的flownet,输入相邻的两帧图片,得到和feature map大小一样的特征光流图,flownet已经在光流估计的数据集上预训练过。
DFF在一段视频帧里面以固定间隔选取关键帧,其他的帧为非关键帧。对于关键帧,DFF用一个特征提取网络去提取feature map,进而任务网络以这些特征为输入得到结果;
对于非关键帧,DFF先经过光流网络计算该非关键帧与此之前最近的关键帧的特征光流图,然后利用得到的光流图和关键帧的feature map进行warp操作,从而将关键帧的特征
对齐并传播到该非关键帧,然后任务网络基于此特征输出该非关键帧的任务结果。
DFF利用相对轻量的光流网络和warp操作代替原来的特征提取网络来得到相应的特征,达到节省计算量来加速的目的。
- result
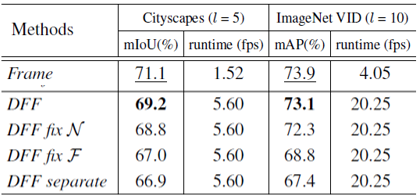
左边是在cityscapes上进行的视频语义分割实验,右边是在imagenet VID上进行的视频目标检测实验,第一排是单帧图片的baseline,用的R-FCN检测算法。
最终在关键帧间隔取为10的情况下,达到了73.1的mAP和20.25的帧率,这个结果比单帧图片的baseline损失了0.8的mAP但是得到了5倍的提速。此外作者还比较了DFF
网络中的特征网络和光流网络是否一起进行端到端学习的结果,实验显示所有部件一起端到端训练时效果最好。

