
[Kubernetes] Device Plugin
Device Plugin
[TOC]
Device Plugin 原理
容器要中使用GPU或者FPGA设备,需要在容器内看到如下两部分设备和目录:
- gpu 设备:
/dev/nvidia0 - gpu 驱动目录:
/usr/local/nvidia/
GPu 设备可以在容器启动时通过Device参数指定,GPU 驱动可以通过Volume参数指定。
Kubernetes 对 GPU 等额外设备支持的实现中,实际上就是通过kubelet将上述两个参数写进了创建该容器时使用的CRI(Container Runtime Interface)参数里。
Kubernetes 中 Node 对象的 Status 字段记录了该节点上自定义资源的信息,比如执行kubectl describe nodes amax-80:
Name: amax-80
Roles: GPU-node
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=amax-80
kubernetes.io/os=linux
node-role.kubernetes.io/GPU-node=
nodetype=gpuNode
...
Hostname: amax-80
Capacity:
cpu: 32
ephemeral-storage: 3844077672Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32575308Ki
pods: 110
nvidia.com/gpu: 4
Allocatable:
cpu: 32
ephemeral-storage: 3542701976650
pods: 110
nvidia.com/gpu: 4
为了能够在上述字段中添加我们自定义的资源,比如nvidia.com/gpu,那么我们必须使用PATCH API向kubelet汇报,加上自己定义的资源的数量。这个操作可以简单的通过curl命令来执行。
# 启动 Kubernetes 的客户端 proxy,这样你就可以直接使用 curl 来跟 Kubernetes 的API Server 进行交互了
$ kubectl proxy
# 执行 PACTH 操作
$ curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/nvidia.com/gpu", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
实际中,上述工作是通过Device Plugin插件完成的
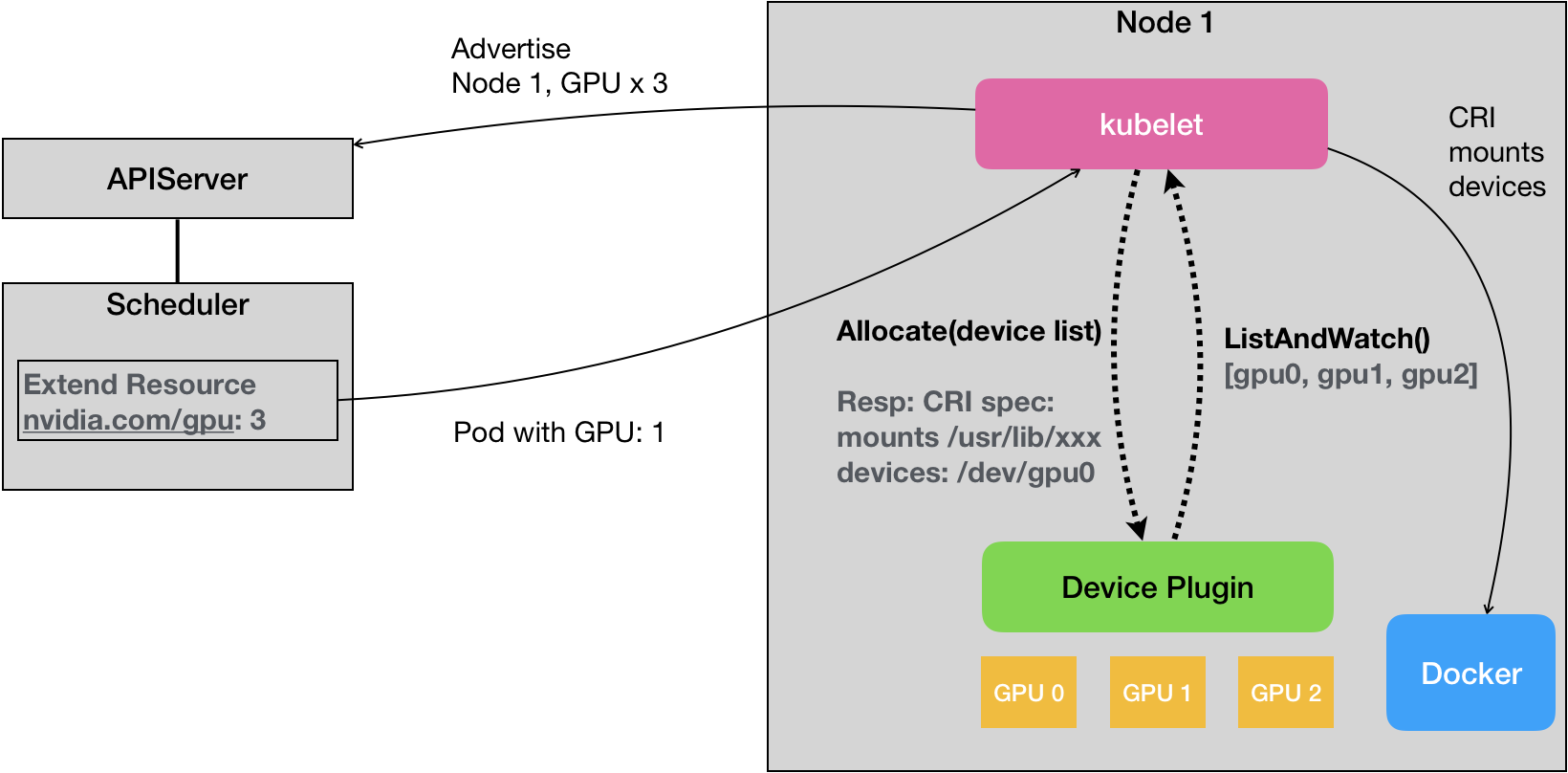
对于每一种设备,都有其对应的 Device Plugin 进行管理。这些插件通过 gRPC 的方式同 kubelet 通信。具体来说,Device Plugin 通过一个叫做ListAndWatch的 API,定期向 kubelet 汇报该 Node 上 GPU 的列表。kubelet 在拿到该列表之后,在向APIServer发送的heartbeat中添加Extended Resource字段。
不过ListAndWatch向上汇报的信息只有本机 GPU 的ID列表,不包括设备本身的其他信息。
分配阶段,对于用户来说最方便的方式是在yaml中说明自己需要多少块 GPU/FPGA,而不是显式地指定挂载多少块 GPU 以及显式地指定 GPU 驱动的挂载目录。
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
在上述Pod的limits字段中,资源名称为nvidia.com/gpu,申请的数量为 1。kube-scheduler在获得该请求之后,将该请求转发至相应的Node,然后kubelet根据其中的nvidia.com/gpu字段向本机的Device Plugin发起一个Allocate请求,其中携带的参数就是kubelet打算分配给容器的设备号。
Nvidia Docker
最前面提到,在容器中使用GPU设备需要设备目录和驱动目录,而yaml文件中并没有定义此类字段,只说自己想要使用一块GPU,实际上本机GPU设备的设备目录设备号都是通过另一个插件nvidia-docker获得的。nvidia-docker实际上是宿主机上的一个守护进程, Device Plugin周期性的通过nvidia-docker获取本机的GPU信息。Device-Plugin将获取的设备路径和驱动目录信息返回给kubelet之后,kubelet将此信息加入到创建该容器所对应的CRI请求中,这样创建的容器就可以使用该GPU设备。

