

[Bachelor] 磁盘与文件系统
文件系统概述
参考自《鸟哥的Linux私房菜》:http://linux.vbird.org/
[TOC]
1. 磁盘分区
1.1 磁盘装置名
磁盘文件名:实体磁盘大多使用/dev/sd[a-]这样的文件名,而虚拟机下的虚拟磁盘可能会使用/dev/vd[a-p]这种文件名。
所有使用SCSI模块驱动的磁盘接口的装置文件名都是/dev/sd[a-p]的格式。顺序则由磁盘被系统侦测到的顺序决定。
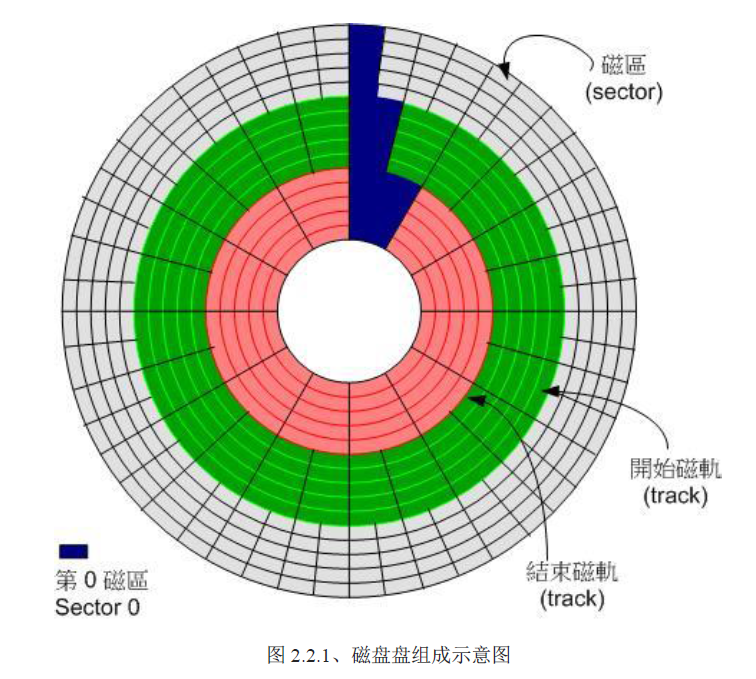
磁盘可能有多个磁盘盘,所有磁盘盘上的同一个磁道组成的同心圆称为磁柱。
1.2 MSDOS(MBR) 与 GPT 磁盘分区表(partition table)
MSDOS(MBR)分区表格式
在第一个扇区 512bytes 会有如下数据:
- 主要启动记录区(Master Boot Record, MBR):安装开机管理程序的地方,446 bytes
- 分区表(partition table):记录整个硬盘分区的状态,46 bytes
分区表最多只能有四组记录区,每组记录区记录该区段的起始与结束的磁柱号码。
假设磁盘装置的装置名为/dev/sda,那么四个分区在Linux系统中的装置名为:
- /dev/sda1
- /dev/sda2
- /dev/sda3
- /dev/sda4
这四个分区可以作为主要(primary)分区或者延伸(extended)分区。
如果想要更多的分区?
第一个扇区的分区表只有 64 bytes,所以只能分出 4 个分区。那么利用其他的扇区来存储额外的分区表就可以达到分出更多分区的目的。延展分区就是作为这个目的来设计的。
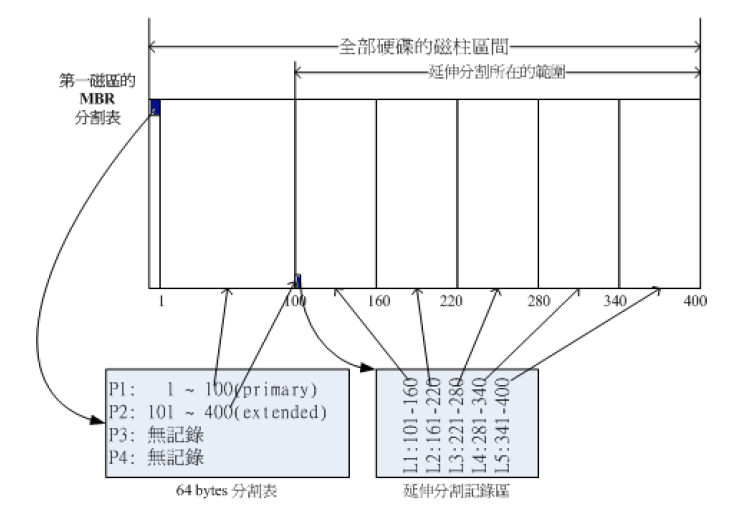
延展分区本身不能被格式化,延展分区的目的是使用额外的扇区来记录分区信息。
由延展分区继续分出来的分区叫做逻辑分区(logical partition)。逻辑分区是延展分区分出来的,所以逻辑分区使用的磁柱区域不能超过延展分区的大小。
按照上述分区,各个分区在Linux中的装置文件名为:
- /dev/sda1
- /dev/sda2
- /dev/sda5
- /dev/sda6
- /dev/sda7
- /dev/sda8
- /dev/sda9
分区号1-4只能作为主要分区或者延展分区的号码,逻辑分区分区号从5开始。
逻辑分区和主要分区可以被格式化,这两个分区是数据存取的主要区域。
MBR分区表的缺点:
- 单一分区无法超过2.2T
- MBR仅有一个区块,被破坏之后无法修复
- 存放开机管理程序的大小只有 446bytes,无法容纳更多代码。
单一分区无法超过2.2T,假设有一个70TB的磁盘,那么只能每2TB分一次区。导致分区过多。
GUID partition table,GPT 磁盘分区表
1.3 挂载
文件系统与目录树的关系(挂载)
挂载就是利用一个目录当成进入点,将磁盘分区的数据放置在该目录下,进入该目录就可以获取该磁盘分区中的数据。
2. Linux文件系统
2.1 文件系统的概念
文件的作用是保存数据,数据在高级意义上包括代码、文字、音视频等等内容,而在低级意义上,数据在磁盘上的本质就是一串二进制数字。操作系统为了管理这些数据,还额外为这些数据创建了各种属性,例如Linux操作系统的文件权限与文件属性。所以文件的概念包含了文件本身所包含的数据以及他们所具有的属性。
不同文件系统对文件的管理方式不同,管理方式包括文件属性、文件权限、文件夹的组织方式等。因此为了使用某个分区,必须按照某种文件系统格式化对应的分区。
传统磁盘与文件系统的概念中,一个分区按照一个文件系统被格式化。但是由于新技术的使用,使得一个分区可以被同时格式化为多个文件系统。所以我们现在将一个可被挂载的数据称为一个文件系统。
文件系统将文件属性与文件内容存放到分区内的不同扇区中,即 inode 和 data block。关于 inode 和 data block 详细内容见其他笔记。
理解一个文件系统的关键是两点:
- 数据结构。它采用哪种on-disk data structure保存文件(data and metadata)
- 访问方式。文件系统如何将进程发出的调用,比如
open(),read(),write(),和它自己的数据结构对应起来?当执行指定系统调用时会访问哪些数据结构?效率如何?
2.2 Linux 的 EXT2 文件系统
当对某个磁盘分区进行格式化之后,该分区内的各个扇区就已经按照指定文件系统的要求,被规划为inode 或者 block。
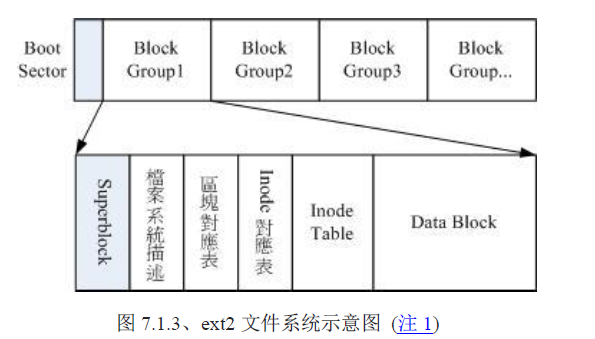
data block
- 原则上,block 的大小和数量在格式化完就不能再改变
- 每个block内最多只能存放一个文件的内容
- 如果文件过大,可以占用多个block
- 文件过小,那么block中剩余的空间不能被其他文件使用(被浪费)
如果block过小,那么如果有很多大文件,就会导致文件对应的inode会对应很多block,导致文件的读写性能下降。
inode table
inode中的内容主要是文件的属性以及该文件的实际数据存放在哪几号block内。因此,每个文件inode中记录的数据至少有如下:
- 该文件的存取模式
- 文件的拥有者与群组
- 文件的大小
- 创建时间
- 最后读取时间
- 最后修改时间
- 定义文件时的flag
- 文件内容指向pointer
superblock
记录文件系统的信息。包括:
- block与inode的总量
- 未使用和已使用的inode/block数量
- block与inode的大小
- file system的挂载时间、最近一次写入数据的时间、最近一个磁盘检查的时间等
- valid bit若文件系统已被挂载,则valid bit为 0,否则为 1.
block bitmap
记录空block的号码
inode bitmap
记录空的inode号码
dumpe2fs命令
使用该命令查看文件系统的信息。
2.3 文件的存取与日志式文件系统的功能
新建一个文件:
- 先确定用户对于目标文件夹是否有w和x的权限,若有则继续;
- 根据inode bitmap找到空的inode,并且将新文件的权限、属性写入
- 根据block bitmap找到空的block,写入实际的数据,并且更新inode中的block pointer
- 更新inode bitmap、block bitmap,并且更新superblock
2.3.1 数据不一致状态
metadata中的内容与实际数据存放区不一致。
2.3.2 日志式文件系统
在文件系统中规划出一个或者几个block,专门记录写入或者修订文件时的步骤。
- 在写入文件之前,先在日志记录区记录准备进行的操作
- 实际写入数据
- 更新日志记录区
2.4 Linux 文件系统的运作
Linux将内存中被修改过的文件标记为Dirty,未被修改过的文件标记为Clean。脏文件不会被直接写入磁盘,而是由系统不定时地将所有脏文件一次性写入磁盘,以达到内存和磁盘数据一致性和文件系统性能的平衡。
