


DQL数据查询语言
DQL数据查询语言
从数据表中提取满足特定条件的记录
- 可以从那个某一张表中查询----单表查询
- 数据分散在不同的表----多表联合查询
下面的示例主要以单表查询为例。
查询的基本语法
select <字段名1>,<字段名2> from
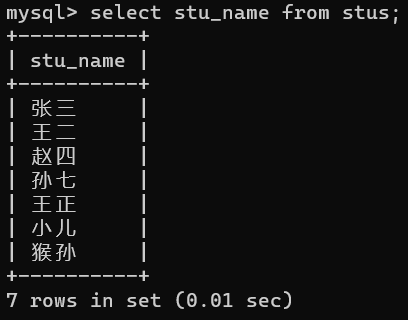
select stu_name from stus;
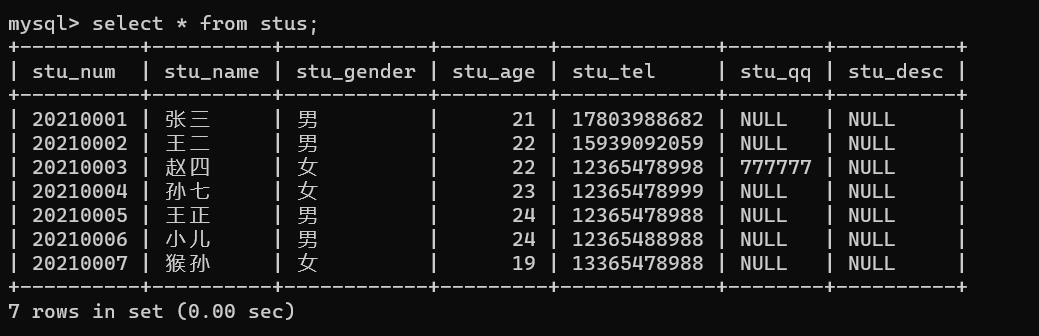
查询所有字段:select * from stus;(项目开发中不建议使用*查询所有列)
这样的查询,显示出的是某个字段或多个字段的所有数据。
下面我们对查询单条或多条记录进行学习。这就需要用到where子句
where子句
在删除、修改及查询的语句后都可以添加where子句(添加条件),用于筛选满足特定的条件的数据进行删除、修改和查询操作
- 条件关系运算符
1.“=”:等于,筛选字段值的精确匹配
2.“!=”:不等于
3.“<>”:小于并且大于
4.“>”:大于
5.“<”:小于
6.“>=”:大于等于
7.“<=”:小于等于
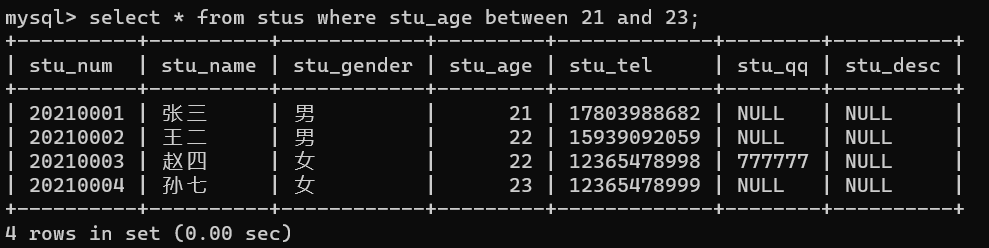
8.between and- 查询年龄在18~20岁之间的记录(区间查询)
1.select * from stus where stu_age>=18 and stu_age<=20;
2.select * from stus where stu_age between 18 and 20;(闭区间)
这两条语句是相同的,当金星区间查询时,推荐使用between and
- 查询年龄在18~20岁之间的记录(区间查询)
- 条件逻辑运算符(多条件查询) 关键字:and or not
关键字and
在where子句中,可以通过逻辑运算符进行连接,通过多个条件来筛选要操作的数据(即需要同时满足多个条件的记录),多个条件用"and"关键词来连接
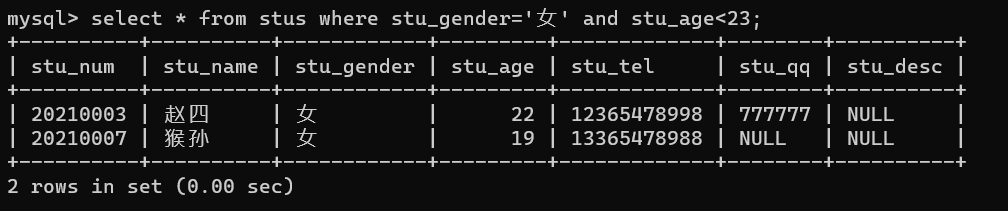
如,要查询年龄小于20岁,并且性别为女
语句:select * from stus where stu_gender='女' and stu_age<21;
关键字or
在查询时,记录满足多个条件中的某一个条件即可,条件之间用or连接
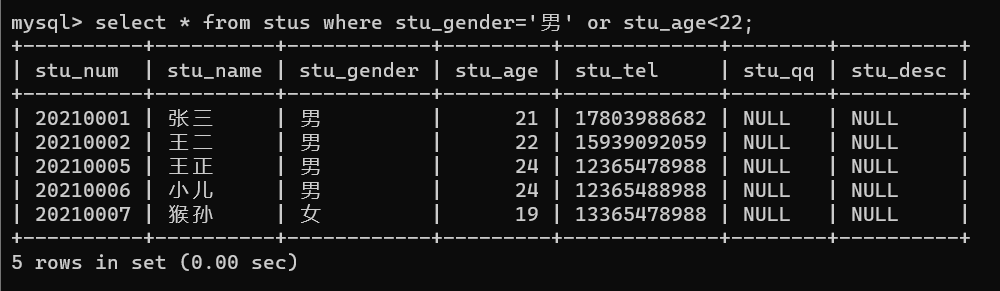
如,年龄小与20岁或者性别为男
语句:select * from stus where stu_gender='男' or stu_age<21;
关键字not
对条件进行取反
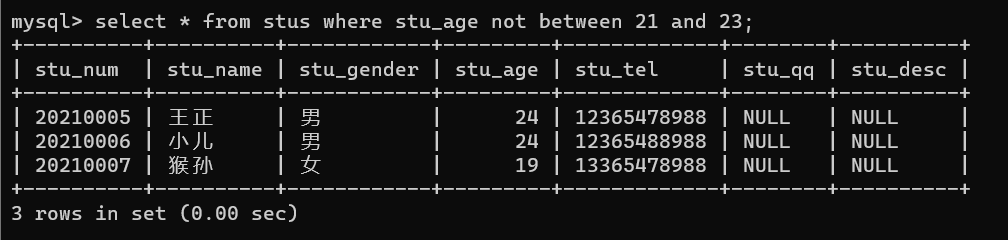
如,查询年龄不在18~20之间的记录
语句:select * from stus where stu_age not between 18 and 20;
- 模糊查询LIKE子句
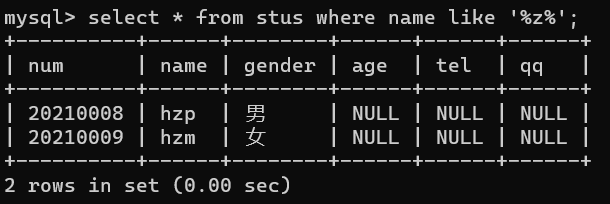
在where子句的条件中,我们可以使用LIKE关键字来实现模糊查询;比如:查询名字中带有字母o的学生信息
语句:select * fromwhere <字段名> like '%条件%';如:select * from stus where stu_name like '%o%';可以将like后面的这个语句理解为正则表达式,%代表o前面可以是任意字符
模糊查询字符含义:- %表示任意多个字符,%o%代表所查询的字段中,只要包含字符o,就被列为查询结果
- _表示任意一个字符,_o%代表,o前面可以有任意的字符,但只能有一个。select * from stus where stu_name like '_o%';
o前面有两个下划线就到表第三个字符必须是o的记录;
select * from stus where stu_name like '张%';查询学生姓名姓张的记录
select * from stus where stu_name like '%鑫';查询学生姓名最后一个字为鑫的记录
- %表示任意多个字符,%o%代表所查询的字段中,只要包含字符o,就被列为查询结果
对查询结果进行处理
- 对查询结果的处理
- 设置查询的列:声明显示查询结果的指定列,如同前面指定查询内容的方式一样,select <字段名1>,<字段名2>... from stus where age>20;
比如要显示年龄大于20岁的所有记录的学号和名字:select num,name from stus where age>20;
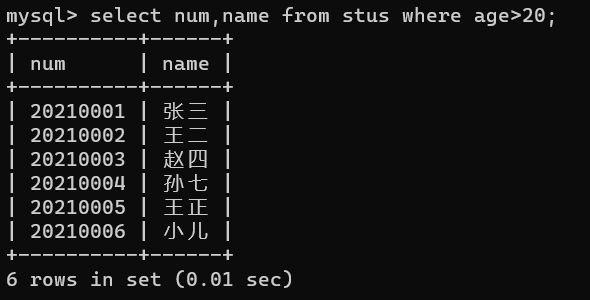
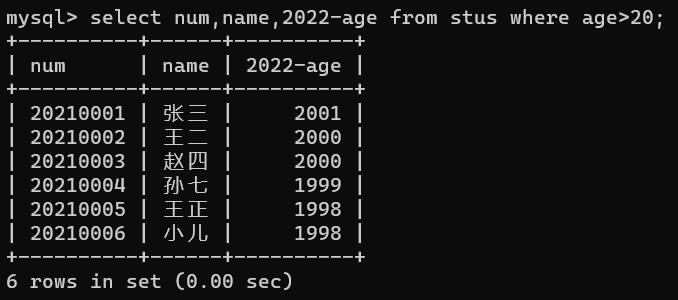
- 对查询结果的处理;比如,我们要显示查询学生的出生年份,但表中实际上并没有出生年份,那么这时我们就可以对查询结果进行处理,现在是2022年,用当前年份减去年龄就可以得到出生年份,操作如下:
select num,name,2022-age from stus where age>20;
2022-age我们将这样的列,称为计算列,就是从数据表中查询的字段进行一定的运算之后显示出来的列,叫做计算列
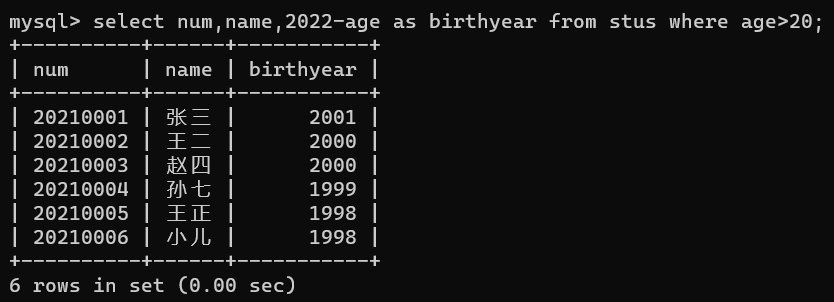
- 字段别名 关键字as:以上面为例,我们计算出了出生年份,但希望这列的字段名,不被显示为‘2022-age’,而是希望可以将字段名显示为‘birthyear’,“这就是字段名的修改”操作,语句如下:
select num,name,2022-age as birthyear from stus where age>20;
适用于计算子字段和普通字段
- 设置查询的列:声明显示查询结果的指定列,如同前面指定查询内容的方式一样,select <字段名1>,<字段名2>... from stus where age>20;
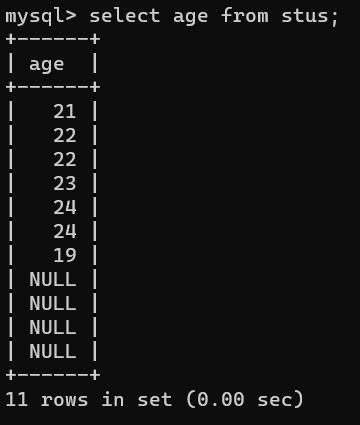
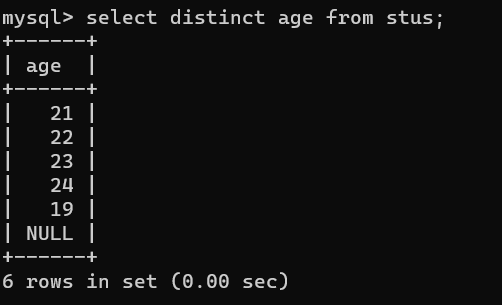
- 消除重复行 关键字distinct
从查询的结果中将重复的记录消除掉,比如想要查询表中的年龄段,如果只是查询age字段,那么显示的结果会有重复,如select age from stus;
操作如下:select distinct age from stus;
- (单字段)排序 关键字order by <字段名> asc|desc
order by <字段名>;默认升序asc,降序操作:order by <字段名> desc;
将查询到的满足条件的记录按照指定的列的值升序或者降序排列
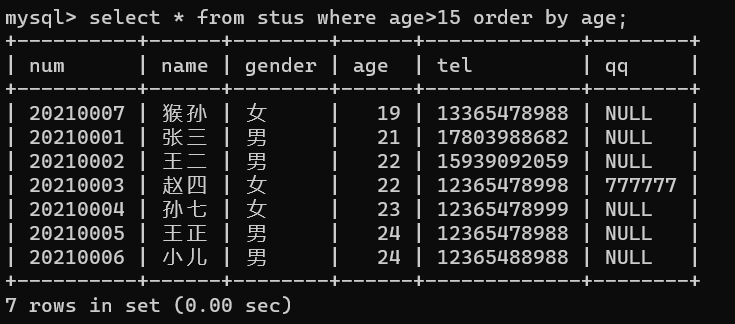
查询结果默认按照主键的顺序排列,并且默认升序;比如,我们要查询age大于15岁的记录(当然表中的记录都满足条件),并且要依据表中性别这一字段来进行排序(默认升序),操作如下:
select * from stus where age>15 order by age;
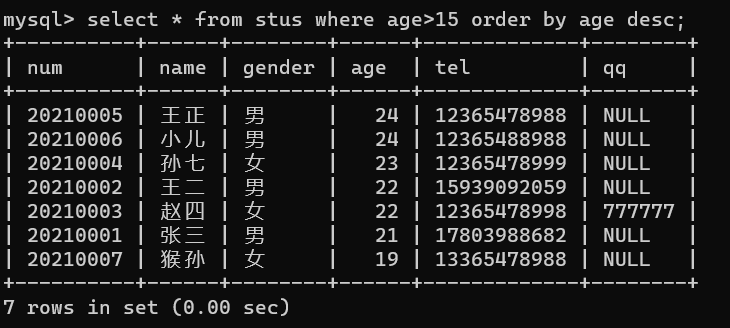
降序操作,select * from stus where age>15 order by age desc;
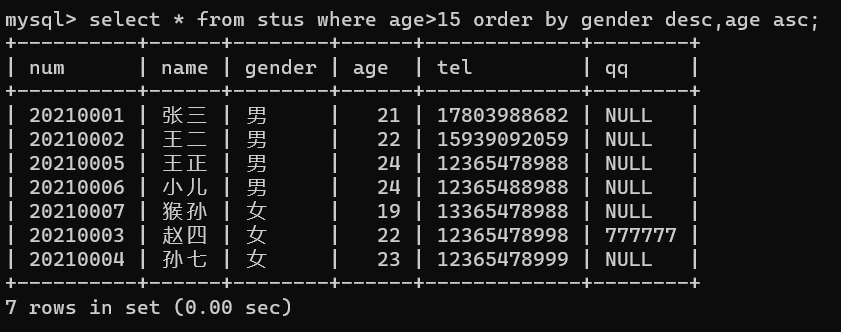
- (多字段)排序
意思就是,先按照某种规则排序,然后在这种规则的分支中,再按照某种规则排序,比如,将性别排序,而后在性别中将年龄进行排序(性别相同的放在一起,在这样的情况下,再将年龄进行排序)
语句:select * from stus where age>15 order by gender desc,age asc;
聚合函数
sql中定义提供了一些对查询的记录的字段进行计算的函数----聚合函数
- count统计函数:比如,统计学生表中有几个学号,select count(num) from stus;
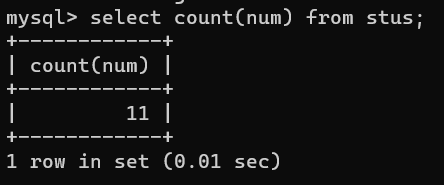
比如,查询表中性别为男的num字段的个数(虽然是一样的,但这里只是做演示)select count(num) from stus where gender='男';
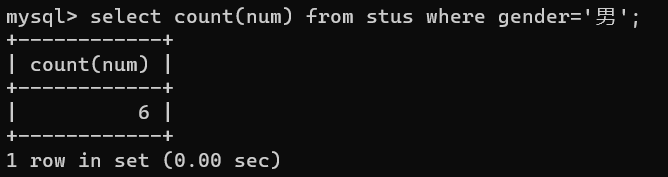
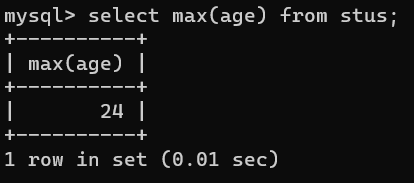
- max()计算最大值函数:比如,展示表中年龄最大字段数据值,select max(age) from stus;
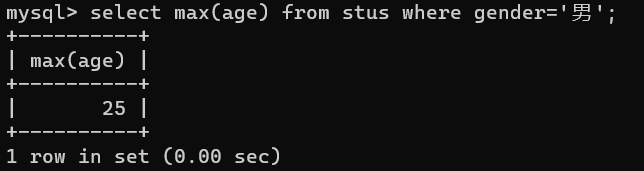
比如,性别为男的记录当中年龄最大的值select max(age) from stus where gender='男';
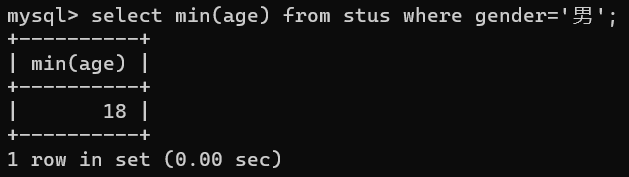
- min()计算最小值函数
select min(age) from stus where gender='男';
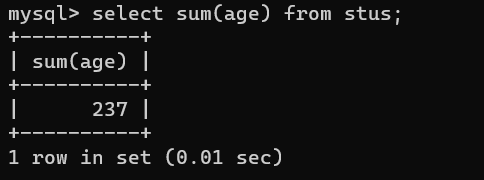
- sum()计算总和,查询满足条件的记录中指定字段数据值的总和,可以运用到总分查询
计算所有记录年龄总和,select sum(age) from stus;
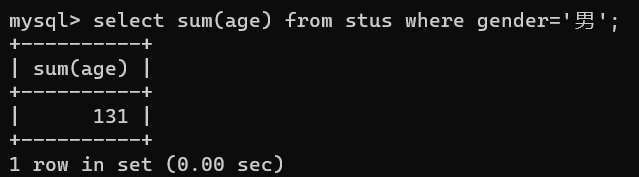
计算性别为男的所有记录的age总和select sum(age) from stus where gender='男';
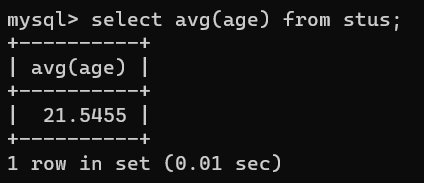
- avg()求平均值
查询指定字段数据值的平均值,不如求平均分,平均年龄
select avg(age) from stus;
日期函数、字符串函数
- 日期函数
我们再录入日期类型数据时,可以输入字符穿形式,如'2021-09-01 09:00:00',也可以使用日期函数,获取当前时间


当向日期类型添加数据时,可以使用字符串的形式,但必须是'yyyy-mm-dd hh:mm:ss'的格式
insert into stus(num, name, gender, age, tel, qq, enterence)
values('20210012', 'wjy', '女', 19, '13232323232', '951236', '2021-09-01 09:00:00');
如果我们想要系统时间添加到日期类型字段,可以使用now()函数
insert into stus(num, name, gender, age, tel, qq, enterence)
values('20210013', 'zwh', '女', 20, '13232323432', '952236', now());
或者sysdate(),效果一样的。

也可以在命令窗口查看当前时间****select now();或者select sysdate(); - 字符串函数
通过sql指令,对字符串进行处理- 拼接函数concat('字符串1','字符串2');如,select concat('hzp','666');
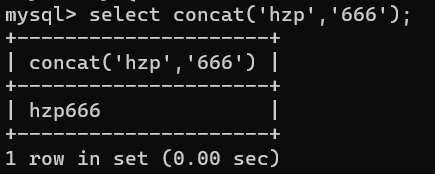
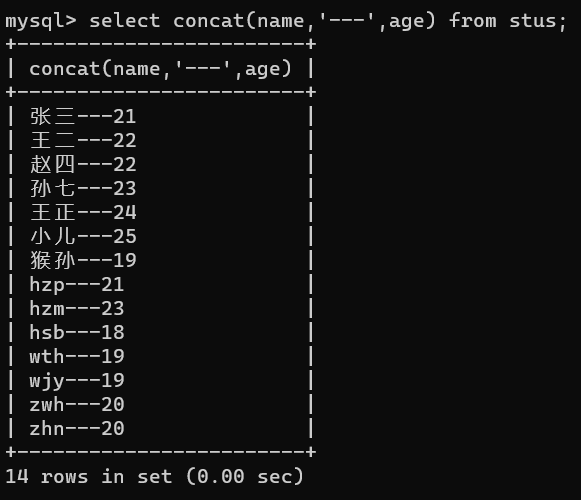
不仅如此,还可以拼接字段:select concat(name,'---',age) from stus;
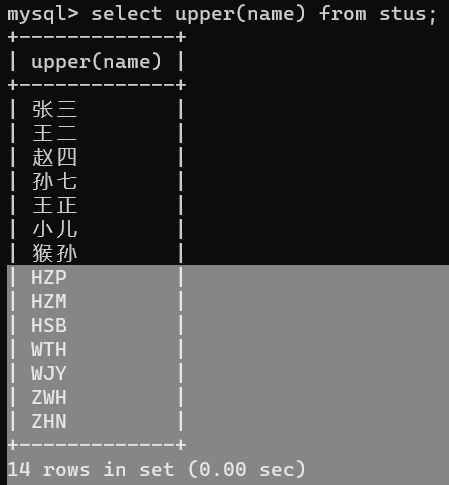
- upper(字段名)将指定字段数据值转化为大写,不对中文做处理
如,select upper(name) from stus;
- lower()作用与upper()相反
- 截取字符串substring(字段名,start,len)
比如只想要截取手机号码的后四位,语句:select name, substring(tel,8,4) from stus;,意为:对tel字段进行截取,从第8个字符开始截取包括第八个,往后截4个字符
注意:sql中的索引不是从0开始的,是从1开始的
- 拼接函数concat('字符串1','字符串2');如,select concat('hzp','666');


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏