
urllib库的基础知识
一、库
import urllib.request
二、打开网页
通过urlopen()的方法,实现网页的打开。必须加“http://”
import urllib.request
response=urllib.request.urlopen('http://www.baidu.com')
2.1urlopen方法说明
| urlopen(url,data,timeout) | url | 网址(必传参数) |
| data | 默认为空,用于传递POST或GET的数据 | |
| timeout |
可以设置等待多久超时,为了解决一些网站实在响应过慢而造成的影响。 该参数属于隐式过期时间,如果响应提前,则时间提前结束 |
三、传递带header请求头的url
import urllib.request
url = 'http://www.budejie.com'#目标访问地址
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'#网页请求头
headers = {'User-Agent' : user_agent }#将请求头组合成键值对形式
req=urllib.request.Request(url,headers=header)#通过Request方法给url加访问头
response=urllib.request.urlopen(req)#打开带请求头的url
3.1请求头说明
| Header | 解释 | 示例 |
|---|---|---|
| Accept | 指定客户端能够接收的内容类型 | Accept: text/plain, text/html |
| Accept-Charset | 浏览器可以接受的字符编码集。 | Accept-Charset: iso-8859-5 |
| Accept-Encoding | 指定浏览器可以支持的web服务器返回内容压缩编码类型。 | Accept-Encoding: compress, gzip |
| Accept-Language | 浏览器可接受的语言 | Accept-Language: en,zh |
| Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段 | Accept-Ranges: bytes |
| Authorization | HTTP授权的授权证书 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 指定请求和响应遵循的缓存机制 | Cache-Control: no-cache |
| Connection | 表示是否需要持久连接。(HTTP 1.1默认进行持久连接) | Connection: close |
| Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 | Cookie: $Version=1; Skin=new; |
| Content-Length | 请求的内容长度 | Content-Length: 348 |
| Content-Type | 请求的与实体对应的MIME信息 | Content-Type: application/x-www-form-urlencoded |
| Date | 请求发送的日期和时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | 请求的特定的服务器行为 | Expect: 100-continue |
| From | 发出请求的用户的Email | From: user@email.com |
| Host | 指定请求的服务器的域名和端口号 | Host: www.zcmhi.com |
| If-Match | 只有请求内容与实体相匹配才有效 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | 只在实体在指定时间之后未被修改才请求成功 | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | 限制信息通过代理和网关传送的时间 | Max-Forwards: 10 |
| Pragma | 用来包含实现特定的指令 | Pragma: no-cache |
| Proxy-Authorization | 连接到代理的授权证书 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | 只请求实体的一部分,指定范围 | Range: bytes=500-999 |
| Referer | 先前网页的地址,当前请求网页紧随其后,即来路 | Referer: http://www.zcmhi.com/archives/71.html |
| TE | 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 | TE: trailers,deflate;q=0.5 |
| Upgrade | 向服务器指定某种传输协议以便服务器进行转换(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | User-Agent的内容包含发出请求的用户信息 | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | 通知中间网关或代理服务器地址,通信协议 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 关于消息实体的警告信息 | Warn: 199 Miscellaneous warning |
四、Proxy代理
4.1配置流程

import urllib.request as re
url='http://www.baidu.com'
proxy={'http':'192.168.1.1:8080'}#代理地址
proxy_handler=re.ProxyHandler(proxy)#将代理地址传入处理器
proxy_opener=re.build_opener(proxy_handler)#建立构造器
proxy_opener.addheaders=[('user-agent','Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')]#传入请求头
re.install_opener(proxy_opener)#安装构造器
response=re.urlopen(url)#打开网页
五、DebugLog调试模式
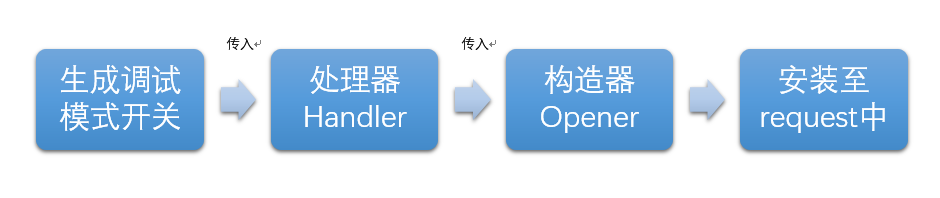
import urllib.request as re url='http://www.baidu.com' debug_start=re.HTTPHandler(debuglevel=1)#开启调试模式 debug_end=re.HTTPHandler(debuglevel=0)#关闭调试模式 opener=re.build_opener(debug_start,debug_end)#执行构造器 re.install_opener(opener)#安装构造器 response=re.urlopen(url)
六、URLError异常处理
使用try...except...来处理异常情况,一般的异常情况分两种:URLError和HTTPError
import urllib.request as re
url='http://www.baidu.com'
res=re.Request(url)
try:
re.urlopen(res)
except re.HTTPError as e:
print(e.code)#返回异常状态值
except re.URLError as e:
print(e.reason)#返回错误结果
else:
print('ALl Right')
6.1状态码
根据响应结果的类型,大致分为以下几类:
1XX(信息类):该类型状态码表示接收到请求并且继续处理。
- 100,客户端必须继续发出请求。
- 101,客户端要求服务器根据请求转换HTTP协议版本。
2XX(响应成功):该类型状态码表示动作被成功接收、理解和接受。
- 200,表明该请求被成功地完成,所请求的资源发送到客户端。
- 201,提示知道新文件的URL。
- 202,接受并处理,但处理未完成。
- 203,返回信息不确定或不完整。
- 204,收到请求,但返回信息为空。
- 205,服务器完成了请求,用户必须复位当前已经浏览过的文件。
- 206,服务器已经完成了部分用户的GET请求。
3XX(重定向类):该类型状态码表示为了完成指定的动作,必须接受进一步处理。
- 300,请求的资源可在多处获得。
- 301,本网页被永久性转移到另一个URL。
- 302,请求的网页被重定向到新的地址。
- 303,建议用户访问其他URL或访问方式。
- 304,自从上次请求后,请求的网页未修改过。
- 305,请求的资源必须从服务器指定的地址获得。
- 306,前一版本HTTP中使用的代码,现已不再使用。
- 307,声明请求的资源临时性删除。
XX(客户端错误类):该类型状态码表示请求包含错误语法或不能正确执行。
- 400,客户端请求有语法错误。
- 401,请求未经授权。
- 402,保留有效ChargeTo头响应。
- 403,禁止访问,服务器收到请求,但拒绝提供服务。
- 404,可连接服务器,但服务器无法取得所请求的网页,请求资源不存在。
- 405,用户在Request-Line字段定义的方法不被允许。
- 406,根据用户发送的Accept,请求资源不可访问。
- 407,类似401,用户必须首先在代理服务器上取得授权。
- 408,客户端没有在用户指定的时间内完成请求。
- 409,对当前资源状态,请求不能完成。
- 410,服务器上不再有此资源。
- 411,服务器拒绝用户定义的Content-Length属性请求。
- 412,一个或多个请求头字段在当前请求中错误。
- 413,请求的资源大于服务器允许的大小。
- 414,请求的资源URL长于服务器允许的长度。
- 415,请求资源不支持请求项目格式。
- 416,请求中包含Range请求头字段,在当前请求资源范围内没有range指示值。
- 417,服务器不满足请求Expect头字段指定的期望值。
5XX(服务器错误类):该类型状态码表示服务器或网关错误。
- 500,服务器错误。
- 501,服务器不支持请求的功能。
- 502,网关错误。
- 503,无法获得服务。
- 504,网关超时。
- 505,不支持的http版本。
七、Cookie
7.1引入
import http.cookiejar
7.2创建流程
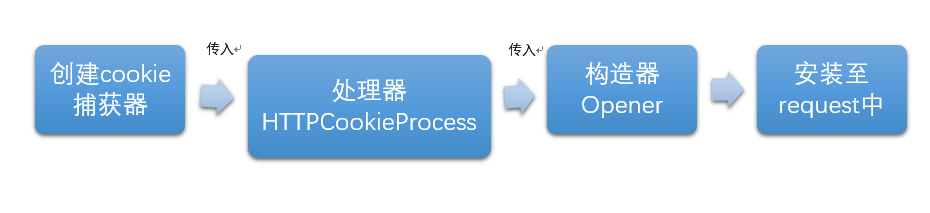
import urllib.request as re import http.cookiejar url="www.baidu.com" c=http.cookiejar.CookieJar()#创建cookie实例 handler=re.HTTPCookieProcessor(c)#创建cookie进程 opener=re.build_opener(handler)#创建构造器 re.install_opener(opener)#安装构造器 response=re.urlopen(url)#打开网页
