
线程池的探索
一、线程池
并发的基础是java.lang.Threads类。 Thread执行类型为java.lang.Runnable的对象。
直接使用Thread类有以下缺点:
Ø 创建新线程会导致一些性能开销。
Ø 太多的线程可能导致性能下降,因为CPU需要在这些线程之间切换。
Ø 不能轻易地控制线程数,因此线程过多会导致内存不足错误。
与直接使用Threads相比,java.util.concurrent包提供了对并发性的改进支持。
使用线程池的优点:
Ø 降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
Ø 提高响应速度:当任务到达时,任务可以不需要等到线程创建就能立即执行。
Ø 提高线程的可管理性:线程是稀缺资源,如果无限制的创建。不仅仅会降低系统的稳定性,使用线程池可以统一分配,调优和监控。但是要做到合理的利用线程池。必须对于其实现原理了如指掌。
二、Executor
Executor框架主要由三个部分组成:任务,任务的执行,异步计算的结果。
主要的类和接口简介如下:
|
ExecutorService |
真正的线程池接口。 |
|
ScheduledExecutorService |
能和Timer/TimerTask类似,解决那些需要任务重复执行的问题。 |
|
ThreadPoolExecutor |
ExecutorService的默认实现。 |
|
ScheduledThreadPoolExecutor |
继承ThreadPoolExecutor的ScheduledExecutorService接口实现,周期性任务调度的类实现。 |
|
Future |
代表异步计算的结果 |
|
Runnable |
可以被ThreadPoolExecutor或其他执行的主体逻辑代码 |
java.util.concurrent 包包含多个 Executor 实现,每个实现都实现不同的执行策略。
执行程序通常通过工厂方法例示,而不是通过构造函数。Executors 类包含用于构造许多不同类型的 Executor 实现的静态工厂方法:
Ø newSingleThreadExecutor()
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
Ø newFixedThreadPool()
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
Ø newCachedThreadPool()
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
Ø newScheduledThreadPool()
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
所需JAR包:
Jdk 1.5 + -> java.util.concurrent包
参考资料:
FixedThreadPool, CachedThreadPool, or ForkJoinPool? Picking correct Java executors for background tasks - https://zeroturnaround.com/rebellabs/fixedthreadpool-cachedthreadpool-or-forkjoinpool-picking-correct-java-executors-for-background-tasks/
java自带线程池和队列详细讲解 - https://www.oschina.net/question/565065_86540
Java并发编程与技术内幕:线程池深入理解 -http://blog.csdn.net/evankaka/article/details/51489322
三、Fork/Join
Fork/Join框架是Java 7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork-Join框架有自己的适用范围。如果一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案,那么这个应用就适合用 Fork-Join框架模式来解决。
Fork-Join框架能够解决很多种类的并行问题。软件开发人员只需要关注任务的划分和中间结果的组合就能充分利用并行平台的优良性能。其他和并行相关的诸多难于处理的问题,例如负载平衡、同步等,都可以由框架采用统一的方式解决。
Fork-Join框架是ExecutorService接口的一种具体实现,目的是为了更好地利用多处理器。它是为那些能够被递归地拆解成子任务的工作类型量身设计的。类似于ExecutorService接口的其他实现,Fork-Join框架会将任务分发给线程池中的工作线程。
Fork-Join框架的核心是ForkJoinPool类,它是对AbstractExecutorService类的扩展。ForkJoinPool实现了工作窃取算法,并可以执行ForkJoinTask任务。
工作窃取算法
Fork-Join框架通过一种称作工作窃取(work stealing)的技术减少了工作队列的争用情况。每个工作线程都有自己的工作队列,这是使用双端队列(或者叫做 deque)来实现的(Java 6 在类库中添加了几种 deque 实现,包括 ArrayDeque 和 LinkedBlockingDeque)。当一个任务划分一个新线程时,它将自己推到 deque 的头部。当一个任务执行与另一个未完成任务的合并操作时,它会将另一个任务推到队列头部并执行,而不会休眠以等待另一任务完成(像 Thread.join() 的操作一样)。当线程的任务队列为空,它将尝试从另一个线程的 deque 的尾部窃取另一个任务。
所需JAR包:
Jdk 1.7 + -> java.util.concurrent包
参考资料:
3. Java 理论与实践: 应用 fork-join 框架
四、Google Guava[建议使用]
Guava工程包含了若干被Google的 Java项目广泛依赖的核心库,例如:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string processing] 、I/O 等等。所有这些工具每天都在被Google的工程师应用在产品服务中。
关于Java并发操作,guava提供了一组API用于封装线程。
有两个关键接口:
ListenableFuture:完成后触发回调的Future
Service:抽象可开启和关闭的服务,帮助你维护服务的状态逻辑
其中:
1、ListenableFuture接口继承自JDK concurrent包下的Future接口,对比Future接口有一些优点:
Ø 大多数Futures 方法中需要它。
Ø 转到ListenableFuture 编程比较容易。
Ø Guava提供的通用公共类封装了公共的操作方方法,不需要提供Future和ListenableFuture的扩展方法。

2、Service接口用于封装一个服务对象的运行状态、包括start和stop等方法。例如web服务器,RPC服务器、计时器等可以实现这个接口。对此类服务的状态管理并不轻松、需要对服务的开启/关闭进行妥善管理、特别是在多线程环境下尤为复杂。Guava包提供了一些基础类帮助你管理复杂的状态转换逻辑和同步细节。
实现:
AbstractIdleService
AbstractExecutionThreadService
AbstractScheduledService
AbstractService
ServiceManager
所需JAR包:
google-guava_xxx.jar
参考资料:
http://www.baeldung.com/thread-pool-java-and-guava
五、threadly
一个工具库,以协助安全并发java开发。提供一个独特的基于优先级的线程池,以及安全地分发线程工作的方法。
参考资料:
GitHub: https://github.com/threadly/threadly
API:http://threadly.github.io/threadly/javadocs/4.4.2/
Download: http://mvnrepository.com/artifact/org.threadly/threadly/4.9.0
六、talent-thread-pool
talent-thread-pool是基于jdk5内置线程池的封装,省却你一些事件的框架
1、帮你完成使用线程池所带来的繁琐的同步安全工作
2、为你提供一个更靠谱的RejectedExecutionHandler(jdk自带的是抛异常,本框架默认的是用定时继续提交)
3、为你提供一个更友好的ThreadFactory(jdk自带的Factory产生出来的Thread名字是形如thread-pool-1的,本框架默认的是形如:myname-1,其中“myname”是应用提供的参数)
4、提供更简单的ThreadPoolExecutor构造器,当然你也可以根据业务需要构造更细化的ThreadPoolExecutor 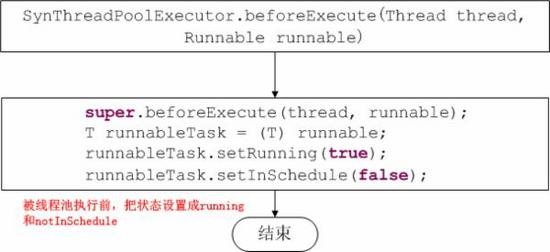
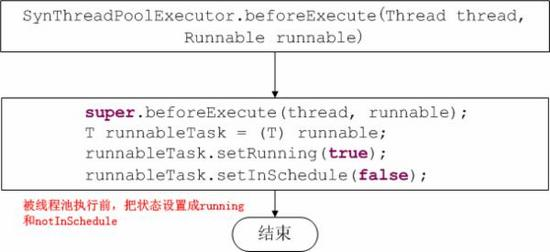
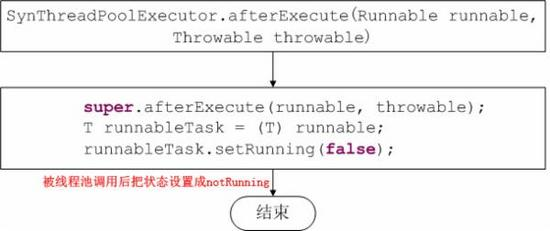
参考资料:
http://tywo45.iteye.com/blog/1944341
http://tywo45.iteye.com/blog/1536159
七、Eclipse Jobs
Eclipse 提供了一套多线程类库(包括 Job 等)极大的方便了开发人员对多线程程序的处理。本文通过对 Eclipse 内核代码的研究,分析 Eclipse 多线程库的内部实现机制,特别是其内部线程池的实现方式,Job 的调度,线程同步机制等。
Eclipse 在 org.eclipse.core.runtime.osgi 运行时插件里提供了 Jobs API 。 Jobs API 被广泛的应用到 Eclipse 平台中,用户所开发的 eclipse 插件里。 Job 是 Eclipse 运行时重要的组成部分(基于 equinox 的 OSGi 框架则是 Eclipse 运行时的最重要的组成部分)。 Job 可以理解成被平台调用异步运行的代码块。 Job 可以异步的执行,多个 Jobs 可以并发执行。那么读者会问了?为什么 eclipse 平台要提供这样的 API 出来,为什么不直接使用 java.lang.Thread 呢?
原因有以下几点:
1)性能更好:通过使用线程池实现了线程共享,减少了创建和销毁线程的开销,提高了性能。
2)交互响应信息:Job 提供了一个框架,开发人员使用 Job 很容易实现与用户的交互,例如允许用户取消 Job 的执行或者显示 Job 。
3)调度的灵活性:可以马上运行一个 Job,可以稍后运行一个 Job, 还可以反复的运行一个 Job
4)Job 的监听机制:Job 监听器监听 Job 的状态信息,比如,知道一个 Job 何时开始运行以及何时结束运行等。
5)优先级及互斥的灵活应用:Job 提供了多种方式来控制 Job 的调度,开发者可以设定 Job 的优先级(读者应注意这一点,JobManager 不保证优先级高的 Job 一定比优先级低的 Job 先被调度执行),也可以使用调度规则保证 Jobs 的同步与互斥。
6)使用Job可以提高程序的性能,节省线程创建和销毁的开销。Eclipse中的Job封装了线程池的实现。当我们启动一个Job时,Eclipse不会马上新建一个Thread,它会在它的线程池中寻找是否有空闲的线程,如果有空闲线程,就会直接用空闲线程运行你的Job。一个Job终止时,它所对应的线程也不会立即终止,它会被返回到线程池中以备重复利用。这样,我们可以节省创建和销毁线程的开销。

图 1. Jobs 框架
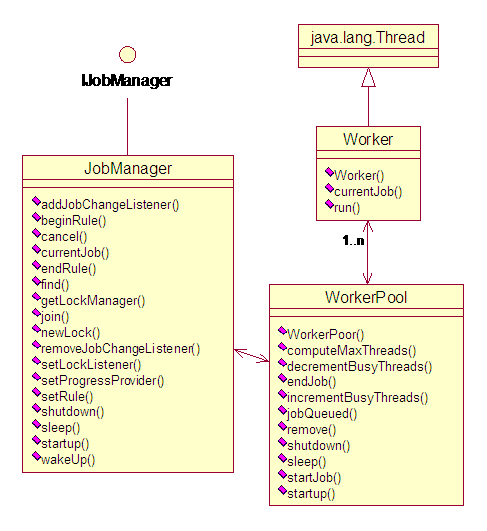
图 2. Work 和 WorkPool,线程池机制
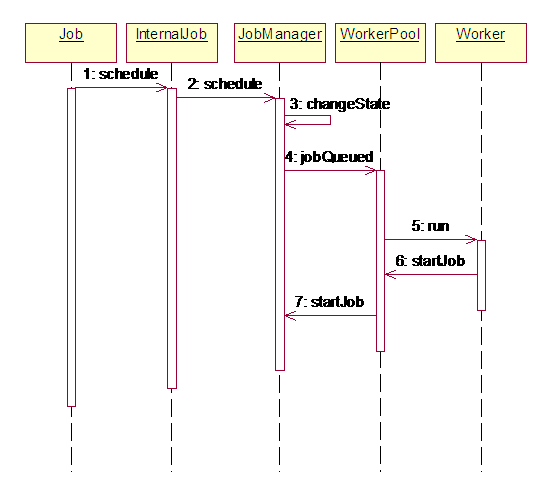
图 3. Schedule方法调用顺序
所需JAR包:
org.eclipse.core.jobs-3.3.0.jar
org.eclipse.core.runtime-3.1.0.jar
org.eclipse.osgi-3.2.0-v20060601.jar
参考资料:
https://www.ibm.com/developerworks/cn/opensource/os-cn-ecl-mthrd/
https://www.ibm.com/developerworks/cn/opensource/os-cn-eclipse-multithrd/
http://defrag-sly.iteye.com/blog/344837
八、Tomcat ThreadPool
Tomcat 的线程池位于tomcat-util.jar文件中,包含了两种线程池方案。
方案一:使用APR的Pool技术,使用了JNI;
方案二:使用Java实现的ThreadPool。这里介绍的是第二种。如果想了解APR的Pool技术,可以查看APR的源代码。
ThreadPool默认创建了5个线程,保存在一个200维的线程数组中,创建时就启动了这些线程,当然在没有请求时,它们都处理“等待”状态(其实就是一个while循环,不停的等待notify)。如果有请求时,空闲线程会被唤醒执行用户的请求。
具体的请求过程是: 服务启动时,创建一个一维线程数组(maxThread=200个),并创建空闲线程(minSpareThreads=5个)随时等待用户请求。 当有用户请求时,调用 threadpool.runIt(ThreadPoolRunnable)方法,将一个需要执行的实例传给ThreadPool中。其中用户需要执行的 实例必须实现ThreadPoolRunnable接口。 ThreadPool 首先查找空闲的线程,如果有则用它运行要执行ThreadPoolRunnable;如果没有空闲线程并且没有超过maxThreads,就一次性创建 minSpareThreads个空闲线程;如果已经超过了maxThreads了,就等待空闲线程了。总之,要找到空闲的线程,以便用它执行实例。找到 后,将该线程从线程数组中移走。 接着唤醒已经找到的空闲线程,用它运行执行实例(ThreadPoolRunnable)。 运行完ThreadPoolRunnable后,就将该线程重新放到线程数组中,作为空闲线程供后续使用。
由此可以看出,Tomcat的线程池实现是比较简单的,ThreadPool.java也只有840行代码。用一个一维数组保存空闲的线程,每次以一个较小步伐(5个)创建空闲线程并放到线程池中。使用时从数组中移走空闲的线程,用完后,再“归还”给线程池。
tomcat5.5.10以上版本支持apr,支持通过apache runtime module进行JNI调用,使用本地代码来加速网络处理。
如果不使用apr之前,Tomcat的Servlet线程池使用的是阻塞IO的模式,使用apr之后,线程池变成了 NIO的非阻塞模式,而且这种NIO还是使用了操作系统的本地代码,看tomcat文档上面的说法是,极大提升web处理能力,不再需要专门放一个web server处理静态页面了。
我自己直观的感受是,不用apr之前,你配置多少个等待线程,tomcat就会启动多少个线程挂起等待,使用apr以后,不管你配置多少,就只有几个NIO调度的线程,这一点你可以通过kill -3 PID,然后察看log得知。
假设不使用apr,可能端口的线程调度能力比较差,所以通过iptables进行端口转发,让两个端口去分担一个端口的线程调度,就有可能减少线程调度的并发,从而提高处理能力,减少资源消耗。
所需JAR包:
tomcat-util.jar
tomcat-juli.jar
参考资料:
Tomat组件研究之ThreadPool - 老码农的专栏http://blog.csdn.net/chen77716/article/details/344764
九、task-frame
负责线程池中任务的高效率和并发执行。
1.您可以自定义线程池大小,以便您可以调整项目的性能要求。
2.您不必担心任务运行时间过长,因为任务框架已经被实现来监视超时任务,一旦任务运行时间不长,任务监视器将从线程池中删除它,还可帮助您自动结束超时任务。
3.任务调度框架具有出色的性能,如果任务队列为空,则框架将自动进入等待状态,直到任务队列有要添加的任务。这将大大降低CPU的消耗。
框架很容易使用,例如:
TaskQueue queue = new TaskQueue();
taskAssigner = new TaskAssigner(queue,10);
taskAssigner.start();
queue.add(task);
参考资料:
https://sourceforge.net/projects/task-frame/?source=directory
十、自己实现一个Thread Pool
参考资料:
https://github.com/gauravrmazra/java-threadpool
http://geekrai.blogspot.in/2014/12/implementing-thread-pool-in-java.html
作者:何钊
来源:博客园
链接:http://www.cnblogs.com/hezhao/
CSDN:http://blog.csdn.net/sinat_27403673
简书:http://www.jianshu.com/u/5ae45d288275
Email:hezhao_java@163.com
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号