Prometheus+grafana部署
分类出所需的监控项种类
一般可分为︰业务级别监控/系统级别监控/网络监控/程序代码监控/日志监控/用户行为分析监控/其他种类监控大的分类还有更多的细小分类,这里给出几个例子,例如:
业务监控
可以包含用户访问QPS,DAU日活,访问状态,业务接口,产品转化率,充值额度,用户投诉等等这些很宏观的概念
系统监控
主要是跟操作系统相关的基本监控项CPU/内存/硬盘/IO/TCP链接/流量等等
网络监控
对网络状态的监控互联网公司必不可少但是很多时候又被忽略例如:丢包率延迟等等。
日志监控
监控中的重头戏,往往单独设计和搭建,全部种类的日志都有需要采集
程序监控
一般需要和开发人员配合,程序中嵌入各种接口直接获取数据或者特质的日志格式
监控系统搭建流程
单点服务端的搭建。
单点客户端的部署·
单点客户端服务器测试。
采集程序单点部署
采集程序批量部署。
监控服务端HA/ cloud。
监控数据图形化搭建。
报警系统测试
报警规则测试
监控+报警联合测试。
正式上线监控
数据采集编写
shell:运维的入门脚本,任何和性能/后台/界面无关的逻辑都可以实现最快速的开发(shell是在运维领域里开发速度最快难度最低的)
python:各种扩展功能扩展库功能丰富,伴随各种程序的展示+开发框架〈如django)等可以
实现快速的中高档次的平台逻辑开发.目前在运维届除去shell这个所有人必须会的脚本之外,火爆程度就属python了
awk:本身是一个实用命令也是一门庞大的编程语言.结合shell脚本或者独立都可以使用·在文本和标准输出处理上有很大的优势
lua:多用于nginx的模块结合是比较新型的一个语言
php:老牌子的开发语言,在大型互联网开发中,目前有退潮的趋势不过在运维中工具开发还是很依赖PHP
perl:传说中对文本处理最快的脚本语言(但是代码可读性不强)
go:新型的语言目前在开发和运维中炒的很热工资也高在各种后端服务逻辑的编写上开发速度快成行早
作为监控数据采焦。我们首推 shell+python,如果说数据采集选取的模式对性能/后台界面不依赖,那么shell速度最快,成本最低(公司往往喜欢快的)
Prometheus server
这里是prometheus的服务端也就是核心
prometheus本身是一个以进程方式后动,之后以多进程和多线程实现监控数据收集/计算/查询/更新/存储的这样一个C/S模型运行模式本身的启动很简单。如果不带参数,不考虑后台运行的问题./prometheus即可之后默认监听在9090端口用来访问。
Prometheus存储方式
prometheus采用的是time-series(时间序列)的方式以一种自定义的格式存储在本地硬盘上
prometheus的本地T-S(time-series)数据库以每两小时为间隔来分block(块)存储,每一个块中又分为多个chunk文件,chunk文件是用来存放采集过来的数据的T-S数据,metadata和索引文件(index)
index文件是对metrics(prometheus中一次K/v采集数据叫做一个metric)和labels(标签)进行索引之后存储在chunk中,chunk是作为存储的基本单位,index and metadata是作为子集。
prometheus平时是将采集过来的数据先都存放在内存之中(prometheus对内存的消耗还是不小的)以类似缓存的方式用于加快搜索和访问。
当出现宕机时,prometheus有一种保护机制叫做WAL可以将数据定期存入硬盘中以chunk来表示,并在重新后动时用以恢复进入内存。
Prometheus服务发现
prometheus本身跟其他的开源软件类似也是通过定义配置文件来给prometheus本身规定需要被监控的项目和被监控节点
Prometheus的客户端
pull主动拉取的形式
push被动推送的形式
pull:指的是客户端(被监控机器)先安装各类已有exporters(由社区组织或企业开发的监控客户端插件)在系统上之后,exporters以守护进程的模式运行并开始采集数据
exporter本身也是一个http_server可以对http请求作出响应返回数据
prometheus 用pull 这种主动拉的方式(HTTP get)去访问每个节点上exporter并采样回需要的数据
push
指的是在客户端(或者服务端)安装这个官方提供的pushgateway插件
然后,使用我们运维自行开发的各种脚本把监控数据组织成k/v的形式metrics形式发送给pushgateway之后pushgateway会再推送给prometheus,这种是一种被动的数据采集模式
Metrics几种主要类型
promethes监控中对于采集过来的数据统一称为metrics数据
Gauges(gaole)
最简单的度量指标,只有一个简单的返回值,或者叫瞬时状态,例如,我们想衡量一个待处理队列中任务的个数
例如︰如果我要监控硬盘容量或者内存的使用量,那么就应该使用Gauges的metrics格式来度量,因为硬盘的容呈或者内存的使用量是随着时间的推移不断的瞬时变化的,这种变化没有规律当前是多少采集回来的就是多少,既不能肯定是一只持续增长也不能肯定是一直降低,是多少就是多少这种就是Gauges使用类型的代表
Counters(kangte)
Counter 就是计数器,从数据量0开始累积计算在理想状态下只能是永远的增长不会降低一些特殊情况另说.
举个例子来说比如对用户访问量的采样数据Counter数据是从0开始一直不断的积累累加下去的所以理想状态下不可能出现任何降低的状况最多只可能是一直保持不变(例如用户不再访问了,那么当前累积的总访问量会以一条水平线的状态保持下去直到再被访问).
Histogram (heisigouman)
Histogram统计数据的分布情况。比如最小值,最大值,中间值,还有中位数,75百分位, 9O百分位,95百分位.98百分位, 98百分位,和98.9百分位的值
这是一种特殊的metrics数据类型,代表的是一种近似的百分比估算数值
prometheus部署
安装Prometheus之前我们必须先安装ntp时间同步
(prometheus T_S对系统时间的准确性要求很高,必须保证本机时间实时同步)
下载地址https://prometheus.io/download/
wget https://github.com/prometheus/prometheus/releases/download/v2.39.1/prometheus-2.39.1.linux-amd64.tar.gz
启动Prometheus
./Prometheus
编写后台启动脚本
vim prometheus.sh
#!/bin/bash
/sfapp/prometheus/prometheus --web.enable-lifecycle --config.file=/sfapp/prometheus/prometheus.yml &>> /sfapp/prometheus/prometheus.log
#可用启动参数--web.read-timeout=5m 请求链接的最大等待时间,防止太多的空闲链接占用资源 --web.max-connections=512最大链接数 --storage.tsdb.retention=15d
prometheus开始采集监控数据后会存在内存中和硬盘中,对于保留期限的设置很重要太长的话硬盘和内存都吃不消太短的话要查历史数据就没有了企业中设置15天为宜 --storage.tsdb.path="data/" 存储数据路径这个也很重要不要随便放在一个地方就执行会把/根目录塞满了 --query.timeout=2m --query.max-concurrency=20 上面这两项是对用户执行prometheus查询时候的优化设置,防止太多的用户同时查询,也防止单个用户执行过大的查询而一直不退出
将prometheus加入到service中
chmod 755 prometheus.sh
touch prometheus.log
vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/docs/introduction/overview/
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/sfapp/prometheus/prometheus.sh
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable prometheus.service
systemctl start prometheus.service
systemctl status prometheus
如果报错查看日志文件
tail -f prometheus.log
启动参数新增,如果配置了脚本,在脚本中添加–web.listen-address=:8091 (你要修改成的端口号) prometheus --config.file=prometheus.yml --web.listen-address=:8091
启动后服务默认运行在9090端口
prometheus.yml文件配置
我们来大致讲解一下配置文件的内容

前两个全局变量
scrape_interval.抓取采样数据的时间间隔,默认每15秒去被监控机上采样一次
这个就是我们所说的prometheus的自定义数据采集频率了
evaluation_interval.监控数据规则的评估频率
这个参数是prometheus多长时间会进行一次监控规则的评估
举个例:假如我们设置当内存使用量>70%时发出报警这么一条rule(规则)那么prometheus 会默认每15秒来执行一次这个规则检查内存的情况
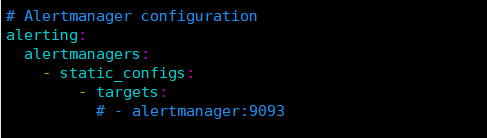
Alertmanager 是prometheus的一个用于管理和发出报警的插件
我采用4.0最新版的Grafana ,本身就已经支持报警发出功能
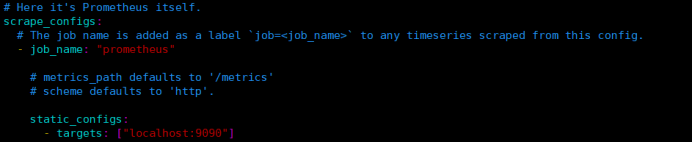
抓取数据配置:job_name定义抓取名称 static_config定义被监控的客户端:本机9090端口
这里可以继续扩展加入其他需要被监控的节点如下是一个生产配置例子
- job_name: 'aliyun'
static_donfigs: - targets: ['server04:9100' ,'web3:9100';'nginx06:9100', web7:9100' 'redis1:9100', log.:9100', redis2:9100"] (注意主机名需要在/etc/hosts中进行解析)
打开页面报错处理
Warning: Error fetching server time: Detected 1181.2449923332453 seconds time difference between your
处理方法:网络获取ntpdate ntp.aliyun.com即可,如果跟我一样内网环境,就暂时先使用data -s 命令修改成最新的北京时间
Node_export部署启动
光搭建好prometheus_server是不够的,我们需要给监控节点搭建第一个exporter用来采样数据
node_exporter,是一个以http_server方式运行在后台,并且持续不断采集 Linux系统中各种操作系统本身相关的监控参数的程序
先进行下载:
wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0/node_exporter-1.4.0.linux-amd64.tar.gz
下载好了同样直接运行node_exporte启动,我这把node_exporter设置为开机自启
vim /usr/lib/systemd/system/node_exporter.service
[Service]
ExecStart=/sfapp/node_exporter/node_exporter --web.listen-address=0.0.0.0:9101 #指定node_exporter 的监听端口为9101
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
[Unit]
Description=node_exporter
After=network.target
启动服务设置开机开机自启
systemctl start node_exporter.service
systemctl enable node_exporter.service
systemctl status node_exporter.service
启动过后可以通过curl来进行查看,node_exporter给我们返回了大量的这种metrics类型KV数据关于metrics 和k/v
curl localhost:9101/metrics
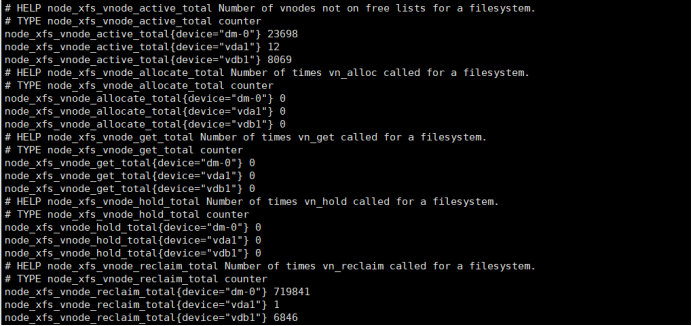
而这些返回的K/V数据,其中的Key的名称就可以直接复制黏贴在prometheus服务页面的查询命令行来查看结果了,见鬼了啥node_export的参数全搜索不到。

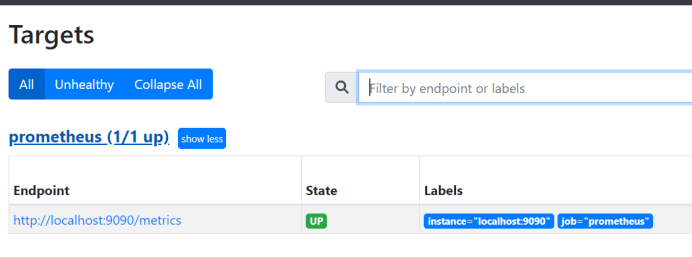
在页面查看status中targets有本地local:9090,大致是明白了export还需要连接上prometheus的服务器
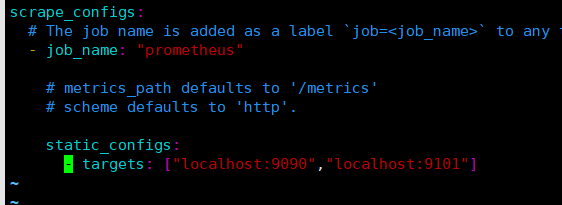
回到prometheus.yml文件把node_export地址添加进来
vim prometheus.yml
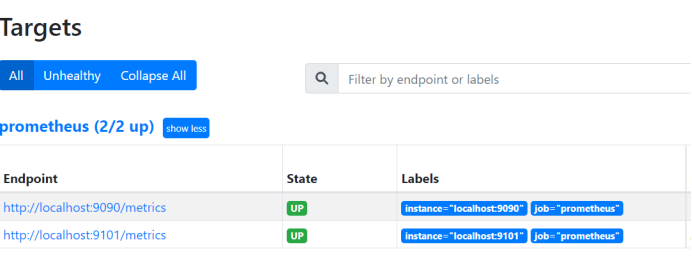
重启prometheus,就可以看到node_export
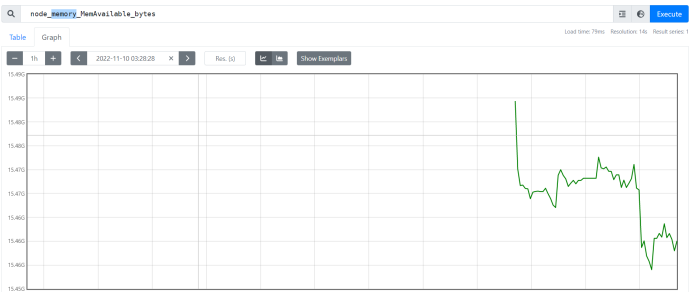
这下就能看见node的参数选项了,查看下memory,嗯,不错
prometheus服务器上存储方式(存储原理前面开头有讲)

其中这些长串字母的是历史数据保留,而当前近期数据实际上保留在内存中,并且按照一定间隔存放在wal目录中防止突然断电或者重后以用来恢复内存中的数据
Grafana部署
定义:Grafana是一款近几年新兴的开源数据绘图工具平台默认支持如下这么多钟数据源作为输入,其强大而美观的绘图能力灵活的数据链接以及4.0之后的报警功能让人爱不释手
官网:https://grafana.com/
下载地址:https://dl.grafana.com/oss/release/grafana-9.2.4.linux-amd64.tar.gz(我在内网只能用tar包安装)
解压及重命名
tar -xf grafana-9.2.4.linux-amd64.tar.gz
mv grafana-9.2.4 grafana
启动Grafana
前台启动
cd grafana/bin/
./grafana-server
设置服务启动
vim /usr/lib/systemd/system/grafana-server.service
[Unit]
Description=Grafana instance
Documentation=http://docs.grafana.org
Wants=network-online.target
After=network-online.target
After=postgresql.service mariadb.service mysqld.service
[Service]
EnvironmentFile=/etc/sysconfig/grafana-server #指定变量文件路径
User=root ##这里用户可以使用其它的,但注意一定要给所有文件夹授权
Group=root ##同上
Type=notify
Restart=on-failure
WorkingDirectory=/sfapp/grafana #工作目录
RuntimeDirectory=grafana #运行时创建grafana文件夹,这个选项好像并没有生效
RuntimeDirectoryMode=0750 #授权目录
ExecStart=/work/grafana/bin/grafana-server \
--config=${CONF_FILE} \
--pidfile=${PID_FILE_DIR}/grafana-server.pid \
--packaging=rpm \
cfg:default.paths.logs=${LOG_DIR} \
cfg:default.paths.data=${DATA_DIR} \
cfg:default.paths.plugins=${PLUGINS_DIR} \
cfg:default.paths.provisioning=${PROVISIONING_CFG_DIR}
#下面的参数是官方文档自带有不懂的可以查官网
LimitNOFILE=10000
TimeoutStopSec=20
CapabilityBoundingSet=
DeviceAllow=
LockPersonality=true
MemoryDenyWriteExecute=false
NoNewPrivileges=true
PrivateDevices=true
PrivateTmp=true
ProtectClock=true
ProtectControlGroups=true
ProtectHome=true
ProtectHostname=true
ProtectKernelLogs=true
ProtectKernelModules=true
ProtectKernelTunables=true
ProtectProc=invisible
ProtectSystem=full
RemoveIPC=true
RestrictAddressFamilies=AF_INET AF_INET6 AF_UNIX
RestrictNamespaces=true
RestrictRealtime=true
RestrictSUIDSGID=true
SystemCallArchitectures=native
UMask=0027
[Install]
WantedBy=multi-user.target
修改/etc/sysconfig/grafana-server变量文件
vim /etc/sysconfig/grafana-server
GRAFANA_USER=root #定义用户,我最开始使用grafana,不知道哪个文件授权有问题导致服务没法启动
GRAFANA_GROUP=root #定义组
GRAFANA_HOME=/work/grafana #grafana的工作目录,tar包解压的路径
LOG_DIR=/work/grafana/log #grafana的日志文件,最好自己手动建好
DATA_DIR=/work/grafana/data #grafana的数据存储路径,最好自己手动建好
MAX_OPEN_FILES=10000 #打开的最大文件数
CONF_DIR=/work/grafana/conf #grafana的主配置文件夹
CONF_FILE=/work/grafana/conf/sample.ini #grafana的主配置文件
RESTART_ON_UPGRADE=true
PLUGINS_DIR=/work/grafana/plugins #grafana的组件目录,自己手动建好
PROVISIONING_CFG_DIR=/work/grafana/conf/provisioning #grafana的provisioning的路径,tar包解压出来就有
# Only used on systemd systems
PID_FILE_DIR=/var/run/grafana #pid存放路径,自己手动建好
修改完成后手动创建文件
mkdir /sfapp/grafana/log
mkdir /sfapp/grafana/plugins
mkdir/sfapp/grafana/data
mkdir /var/run/grafana
启动服务,设置开机自启
systemctl start grafana-server.service
systemctl status grafana-server.service
systemctl enable grafana-server.service
Grafana启动浏览器访问,3000为Grafana的默认侦听端口,使用nginx反向代理报错:
If you're seeing this Grafana has failed to load its application files

修改grafana.ini配置文件
vim /sfapp/grafana/conf/sample.ini

rul加上ninx代理的二级路径,serve_from_sub_path改为true
systemctl restart grafana-server.service
再次刷新浏览器,出现了登录界面,系统默认用户名和密码为admin/admin,第一次登陆系统会要求修改密码,修改密码后登陆。
修改密码的时候报错origin not allowed,又踩坑。。。
修改nginx文件
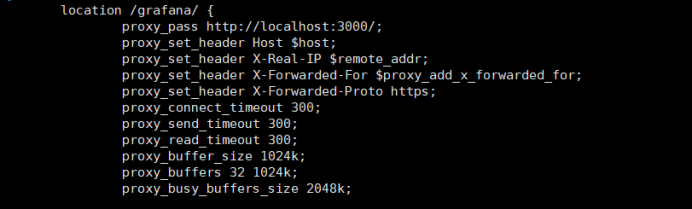
重启nginx服务后,刷新浏览器页面直接进入了,这是可以跳过密码修改?
为了保险一点,我还是手动改下密码

好了终于可以回归正轨,grafana设置新的数据源,连接prometheus_server
点击主菜单,找到data sources
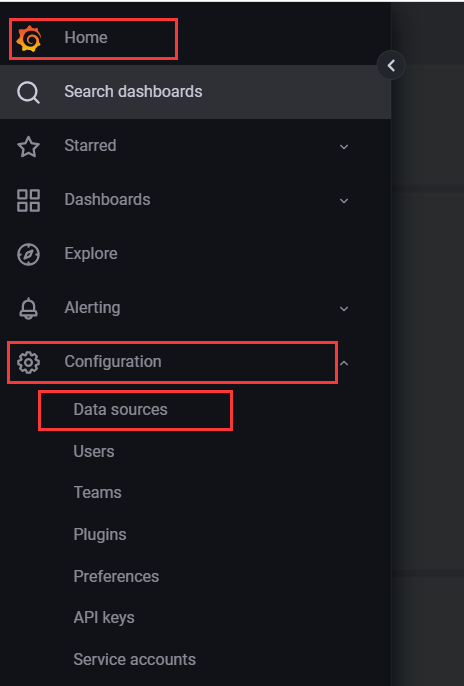
点击新的数据源
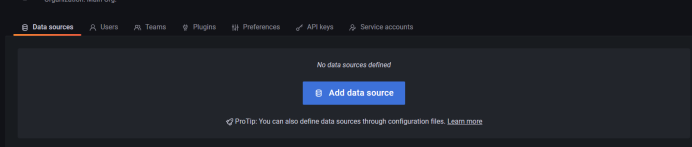
选择prometheus

先添加prometheus地址,其它参数暂时先不用配置,我grafana和prometheus在同一台服务器上
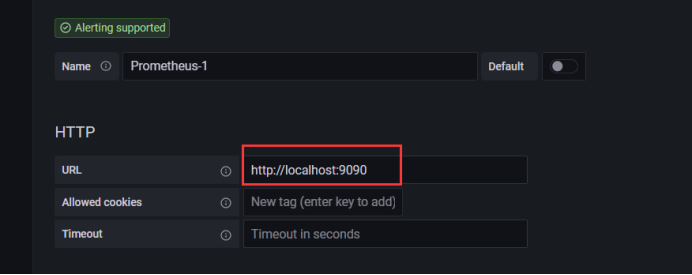
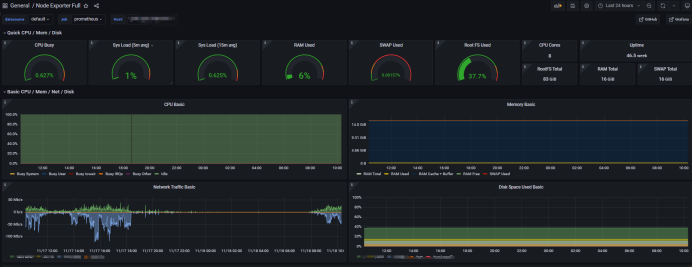
配置好数据源过后,就需要添加仪表盘,我这直接使用grfana官方的模板进行导入
官方监控模板地址:https://grafana.com/grafana/dashboards
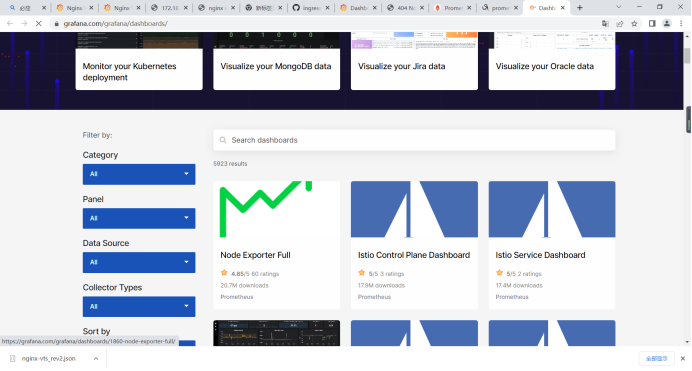
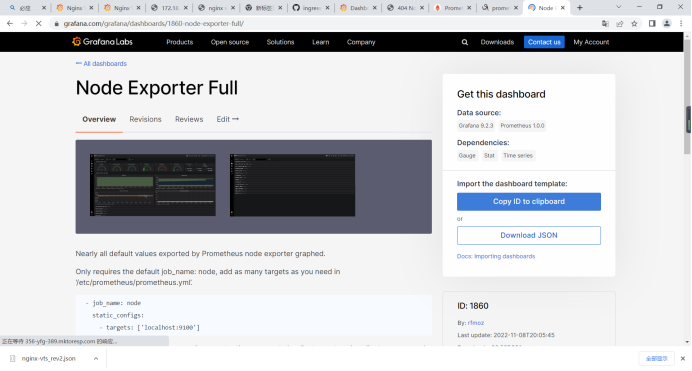
选定需要使用的模板后,有2种导入方式,1、在有互联网的情况下直接使用id导入。2、下载json文件进行导入
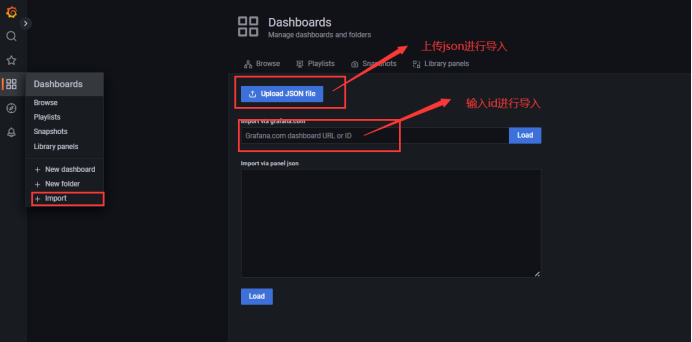
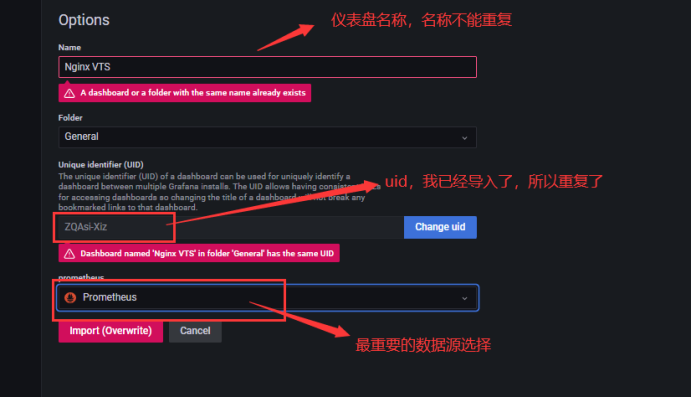
导入后,就可以看见仪表盘了